[논문 리뷰] Object Detection with Transformers: A Review
이 논문은 DETR 및 이후 21개의 DETR 기반 개선점을 조사하면서 아키텍처 변경, 학습 수렴 및 COCO와 같은 벤치마크에서의 성능을 분석한다.
The astounding performance of transformers in natural language processing (NLP) has motivated researchers to explore their applications in computer vision tasks. DEtection TRansformer (DETR) introduces transformers to object detection tasks by reframing detection as a set prediction problem. Consequently, eliminating the need for proposal generation and post-processing steps. Initially, despite competitive performance, DETR suffered from slow training convergence and ineffective detection of smaller objects. However, numerous improvements are proposed to address these issues, leading to substantial improvements in DETR and enabling it to exhibit state-of-the-art performance. To our knowledge, this is the first paper to provide a comprehensive review of 21 recently proposed advancements in the original DETR model. We dive into both the foundational modules of DETR and its recent enhancements, such as modifications to the backbone structure, query design strategies, and refinements to attention mechanisms. Moreover, we conduct a comparative analysis across various detection transformers, evaluating their performance and network architectures. We hope that this study will ignite further interest among researchers in addressing the existing challenges and exploring the application of transformers in the object detection domain. Readers interested in the ongoing developments in detection transformers can refer to our website at: https://github.com/mindgarage-shan/trans_object_detection_survey
연구 동기 및 목표
- Provide a comprehensive overview of DETR and its architectural modules.
- Categorize and summarize improvements to DETR by backbone, pre-training, attention, and query design.
- Evaluate performance and training dynamics of detection transformers on MS COCO.
- Discuss building blocks and future directions for detection transformers.
제안 방법
- Catalog and describe DETR and its numerous enhancements.
- Compare architectural components and training strategies across variants.
- Assess convergence behavior and object detection performance on COCO.
- Summarize efficiency and accuracy considerations of different attention and query designs.
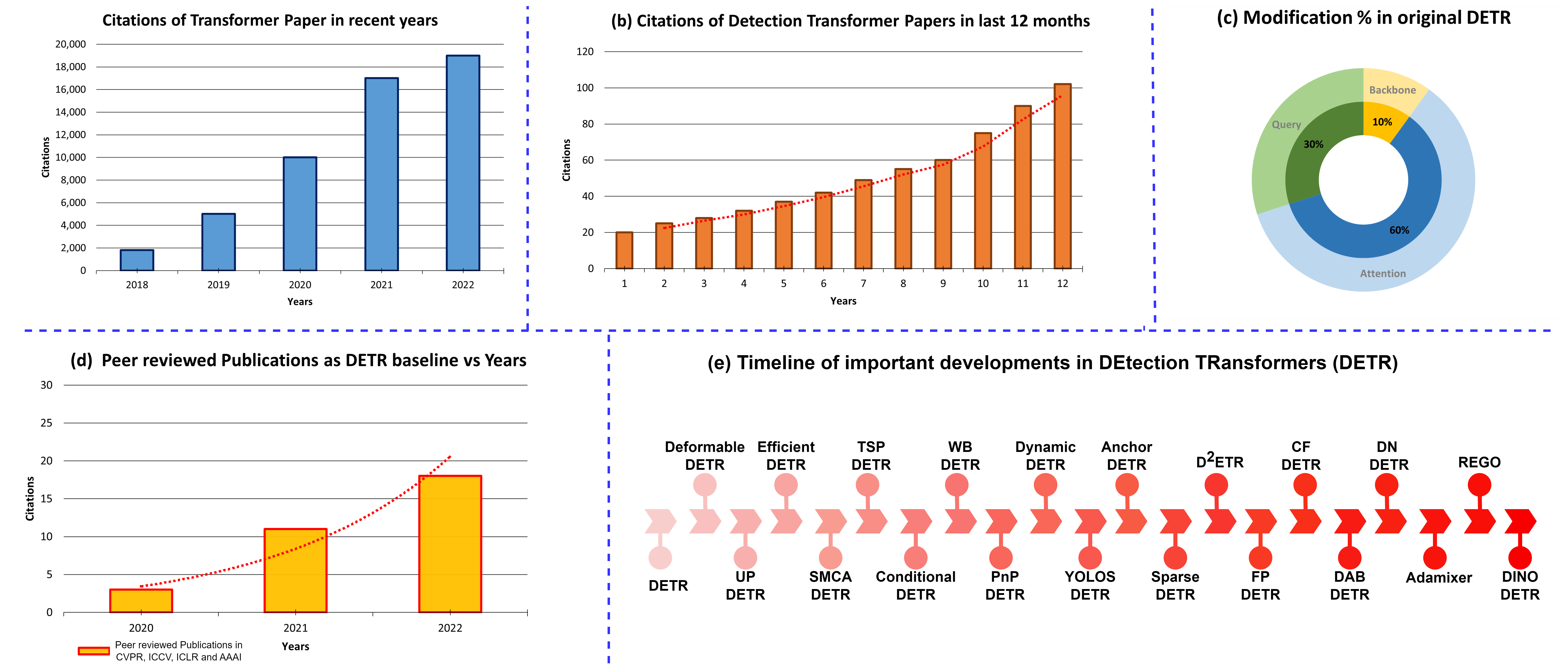
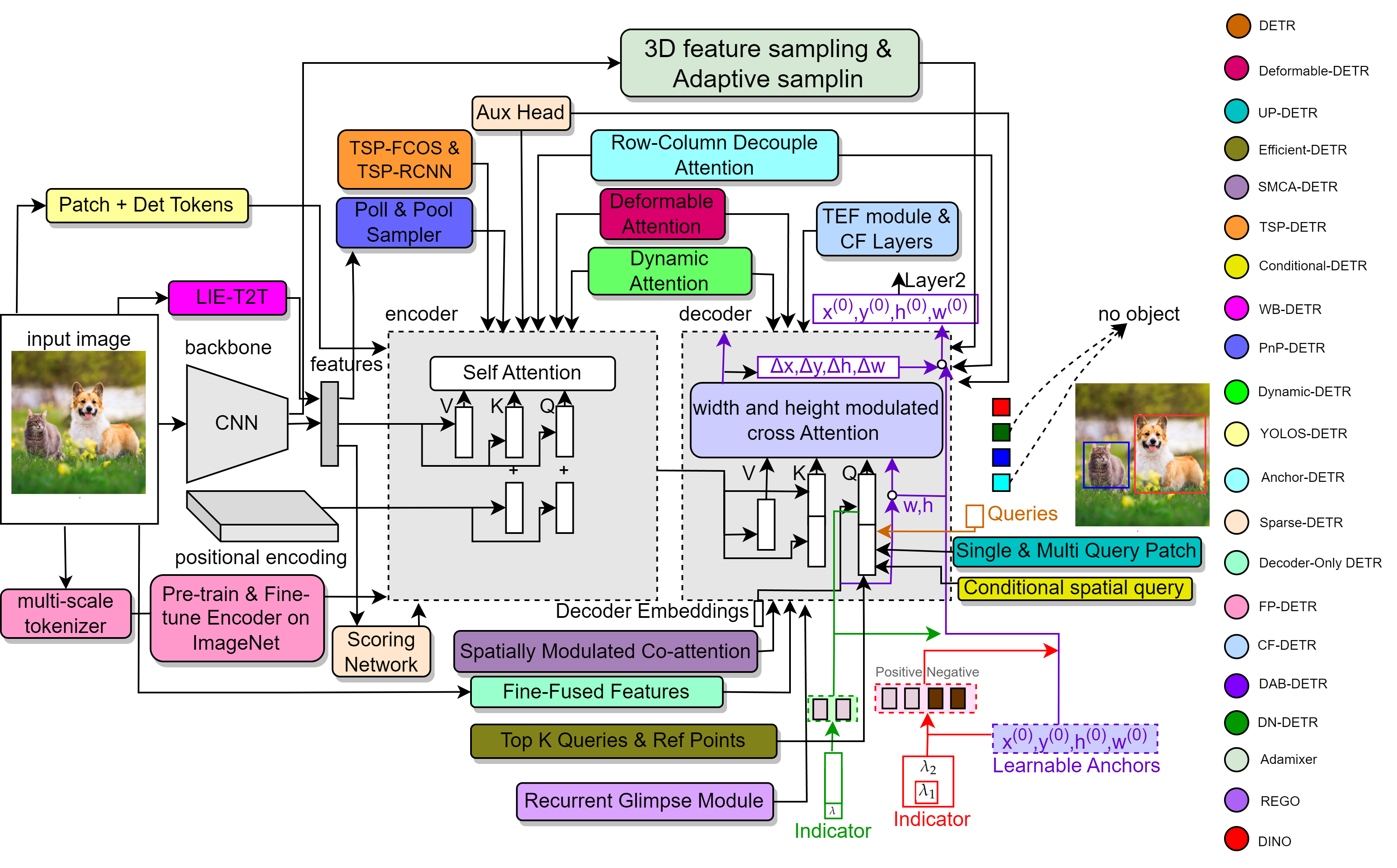
실험 결과
연구 질문
- RQ1What are the key architectural components of DETR and how have they evolved in its successors?
- RQ2How do backbone changes, pre-training strategies, attention mechanisms, and query designs impact training convergence and small-object detection?
- RQ3How do state-of-the-art detection transformers compare in accuracy and efficiency on MS COCO?
- RQ4What are the main challenges and open directions for detection transformers?
주요 결과
- DETR introduced a set-based, end-to-end object detector that removes region proposals and NMS.
- Numerous improvements address slow convergence and small-object performance, including deformable attention and multi-scale features.
- Deformable-DETR reduces computational complexity and speeds up training by focusing attention samples near reference points.
- Other variants (UP-DETR, SMCA-DETR, Conditional-DETR, TSP-DETR, etc.) propose pretraining, spatially modulated co-attention, cross-attention refinements, and RoI-based refinements to improve convergence and accuracy.
- WB-DETR explores backbone-free detection by using a transformer encoder-decoder without a CNN backbone, with local-information enhancements to compensate for missing locality.
- Overall, the surveyed methods show faster convergence and improved small-object performance compared to original DETR, with diverse design trade-offs.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.