[논문 리뷰] Offsite-Tuning: Transfer Learning without Full Model
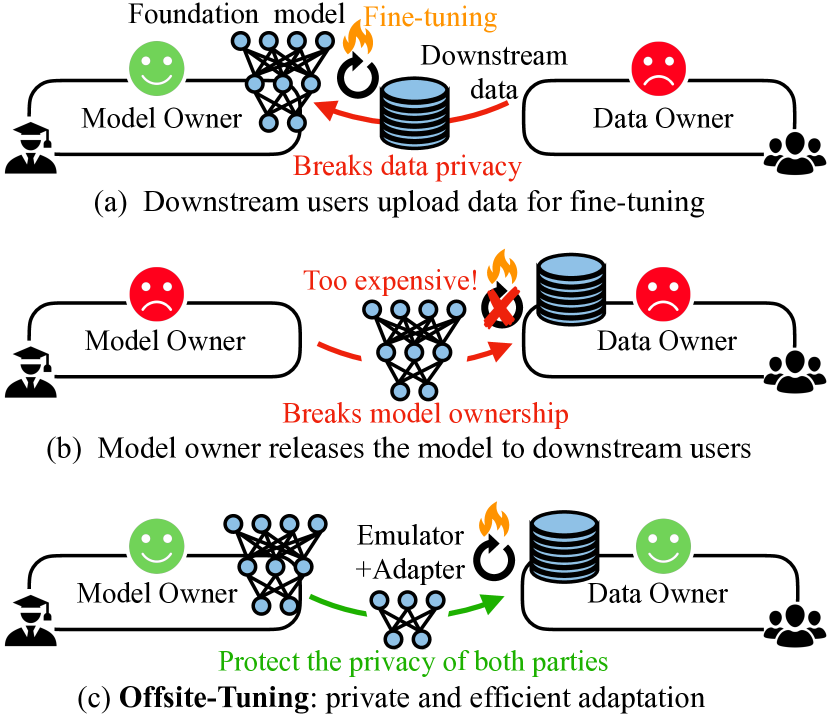
Offsite-Tuning은 전체 모델 가중치에 접근하지 않고도, 학습 가능한 어댑터와 데이터 소유자와 공유되는 손실 압축 에뮬레이터를 사용하여 다운스트림 데이터에 맞게 수십억 매개변수 파운데이션 모델을 적응시킬 수 있게 하며, 프라이버시를 보장하고 전체 파인튜닝과 비슷한 정확도를 유지하면서 더 효율적인 파인튜닝을 달성합니다.
Transfer learning is important for foundation models to adapt to downstream tasks. However, many foundation models are proprietary, so users must share their data with model owners to fine-tune the models, which is costly and raise privacy concerns. Moreover, fine-tuning large foundation models is computation-intensive and impractical for most downstream users. In this paper, we propose Offsite-Tuning, a privacy-preserving and efficient transfer learning framework that can adapt billion-parameter foundation models to downstream data without access to the full model. In offsite-tuning, the model owner sends a light-weight adapter and a lossy compressed emulator to the data owner, who then fine-tunes the adapter on the downstream data with the emulator's assistance. The fine-tuned adapter is then returned to the model owner, who plugs it into the full model to create an adapted foundation model. Offsite-tuning preserves both parties' privacy and is computationally more efficient than the existing fine-tuning methods that require access to the full model weights. We demonstrate the effectiveness of offsite-tuning on various large language and vision foundation models. Offsite-tuning can achieve comparable accuracy as full model fine-tuning while being privacy-preserving and efficient, achieving 6.5x speedup and 5.6x memory reduction. Code is available at https://github.com/mit-han-lab/offsite-tuning.
연구 동기 및 목표
- 다운스트림 태스크를 위한 독점 파운데이션 모델의 파인튜닝에서 프라이버시 및 효율성 문제를 제기한다.
- 전체 모델 가중치나 데이터를 노출하지 않고 파인튜닝을 가능하게 하는 프레임워크를 제안한다.
- 표준 벤치마크 전반에서 언어 및 비전 파운데이션 모델에의 적용 가능성을 시연한다.
제안 방법
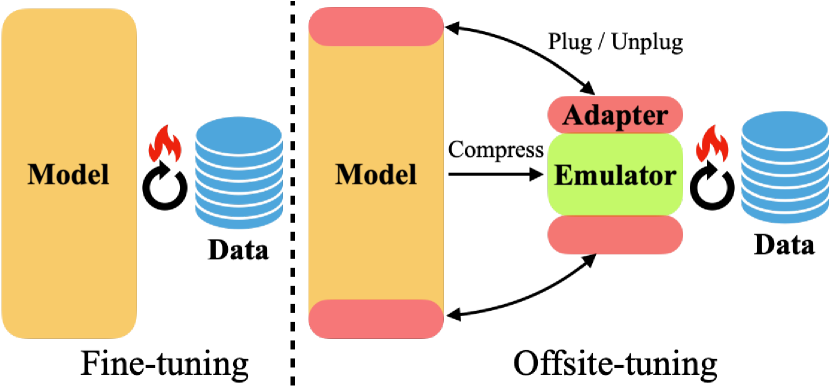
- 기초 모델을 작은 학습 가능한 어댑터(A)와 동결된 나머지(E)로 분할한다; E에 손실 압축을 적용해 에뮬레이터(E*)를 생성한다.
- 데이터 소유자에게 [A, E*]를 제공하고, 소유자는 E*에서 얻은 근사 기울기로 A를 파인튜닝한다.
- 업데이트된 어댑터 A'를 모델 소유자에게 반환하고, 소유자는 이를 전체 모델에 주입해 M' = [A', E]를 얻는다.
- E의 중간 계층을 제거하여 계층 드롭 기반의 에뮬레이터 압축을 탐색하되, 처음과 마지막 계층은 보존한다; 자원이 허용하는 경우 E에서 E*를 증류하는 것을 선택적으로 수행한다.
- 샌드위치 형태의 어댑터를 M = A1 ∘ E ∘ A2로 설계해 얕은 계층과 깊은 계층의 업데이트를 모두 포착하고, 상향/하향 계층만 업데이트하는 것보다 전이 성능을 향상시킨다.
- 어댑터 계층에 이러한 기법(Adapter, LoRA, BitFit)을 적용하여 파라미터 효율적인 파인튜닝 기법과 결합하고, 학습 가능한 파라미터를 추가로 감소시킨다.
실험 결과
연구 질문
- RQ1작은 어댑터와 압축된 에뮬레이터가 전체 모델 가중치나 데이터를 공유하지 않고도 수십억 매개변수의 파운데이션 모델에 대해 효과적인 파인튜닝을 가능하게 할 수 있는가?
- RQ2에뮬레이터를 어떻게 압축해야 어댑터에 대한 그래디언트 유용성과 모델 소유권 보호의 균형을 이룰 수 있는가?
- RQ3데이터 소유자의 데이터로 학습된 어댑터를 전체 모델에 주입하는 플러그인 방식이 언어 및 비전 태스크 전반에서 전체 파인튜닝 성능에 근접하는가?
- RQ4Offsite-Tuning을 사용할 때의 효율성 증가(속도, 메모리)와 이것이 모델 크기 및 압축 전략에 따라 어떻게 스케일되는가?
- RQ5Offsite-Tuning이 기존의 파라미터 효율적 파인튜닝 방법들과 어떻게 상호 작용하는가?
주요 결과
- Offsite-Tuning은 프라이버시를 유지하면서(전체 모델 가중치에 접근하지 않음) 여러 언어 및 비전 태스크에서 전체 파인튜닝과 비교 가능한 플러그인 성능을 달성한다.
- 레이어 드롭 기반 에뮬레이터 압축이 성능과 프라이버시 사이의 최적 균형을 제공하며, 에뮬레이터와 플러그인 성능 간의 차이가 모델 소유권을 보존하도록 눈에 띄게 유지된다.
- 에뮬레이터의 증류(distillation)가 플러그인 성능을 에뮬레이터 성능보다 더 향상시켜 특정 모델들에서 성과를 개선한다(예: OPT-1.3B 및 GPT2-XL).
- Offsite-Tuning을 파라미터 효율적 파인튜닝 방법(Adapter, LoRA)과 결합하면 학습 가능한 파라미터를 감소시키면서도 플러그인 성능을 유지하거나 향상시키고, BitFit은 경우에 따라 전체 파인튜닝에 비해 성능이 떨어지는 경향이 있다.
- 효율성 향상은 상당하며, 로라(LoRA)와 결합했을 때 단일 GPU 하드웨어에서 최대 6.5배의 처리량 향상 및 5.6배의 메모리 절감을 달성한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.