[논문 리뷰] On Leveraging Large Language Models for Enhancing Entity Resolution: A Cost-efficient Approach
논문은 주어진 예산 내에서 불확실성(엔트로피)을 줄이기 위해 최적의 매칭 질문 집합(MQsSP)을 선택하는 LLM 기반의 비용 인식 프레임워크를 제안하며, LLM의 신뢰도를 사용하여 파티션 확률을 조정한다.
Entity resolution, the task of identifying and merging records that refer to the same real-world entity, is crucial in sectors like e-commerce, healthcare, and law enforcement. Large Language Models (LLMs) introduce an innovative approach to this task, capitalizing on their advanced linguistic capabilities and a ``pay-as-you-go'' model that provides significant advantages to those without extensive data science expertise. However, current LLMs are costly due to per-API request billing. Existing methods often either lack quality or become prohibitively expensive at scale. To address these problems, we propose an uncertainty reduction framework using LLMs to improve entity resolution results. We first initialize possible partitions of the entity cluster, refer to the same entity, and define the uncertainty of the result. Then, we reduce the uncertainty by selecting a few valuable matching questions for LLM verification. Upon receiving the answers, we update the probability distribution of the possible partitions. To further reduce costs, we design an efficient algorithm to judiciously select the most valuable matching pairs to query. Additionally, we create error-tolerant techniques to handle LLM mistakes and a dynamic adjustment method to reach truly correct partitions. Experimental results show that our method is efficient and effective, offering promising applications in real-world tasks.
연구 동기 및 목표
- 데이터가 풍부한 도메인에서 엔티티 해상도를 개선하기 위해 Large Language Models (LLMs)의 활용을 촉진한다.
- 정확도와 LLM 사용 비용의 균형을 맞추는 비용 인식 워크플로우를 도입한다.
- 예산 제약 하에서 불확실성을 최소화하기 위해 Matching Questions Selection Problem (MQsSP)을 정의하고 해결한다.
- LLM 응답이 파티션 확률을 어떻게 조정하고 결과 집합의 엔트로피를 감소시키는지 모델링한다.
제안 방법
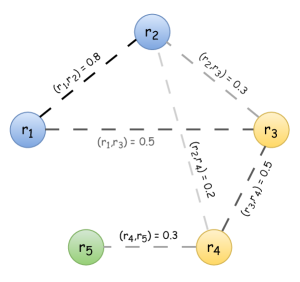
- 레코드를 그래프의 노드로 표현하고 관련 확률을 갖는 레코드의 클러스터 분할 가능한 부분을 정의한다.
- RS(파티션의 결과 집합)에서의 불확실성을 정량화하기 위해 Shannon 엔트로피를 사용한다.
- Matching Questions (MQ)와 LLM 가격을 반영하기 위한 비용 함수 F(MQ)를 정의하여 예산 제약 MQ 선택을 가능하게 한다.
- MQsSP를 가방 문제와 유사한 예산 하에서 공동 엔트로피 감소를 최대화하는 형태로 정식화하고, (1-1/e) 보장을 갖는 탐욕적이고 부분모듈적 최적화 접근법을 제안한다.
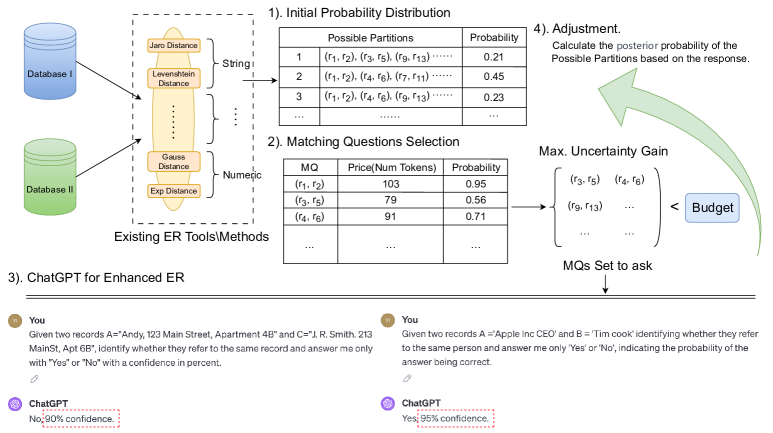
- MQs를 반복적으로 선택하고 LLM에 질의하며 파티션 확률을 업데이트하는 LLM 보조 ER 워크플로우(Algorithm 2)를 개발한다.
- RS를 업데이트할 때 불완전한 LLM 응답을 반영하기 위한 확률적 보정 모델( Cap 및 Conf 포함 )을 제공한다.
실험 결과
연구 질문
- RQ1비용을 통제하면서 LLM을 서비스로 활용하여 엔티티 해상도를 개선하는 방법은 무엇인가?
- RQ2예산 하에서 불확실성을 최대한 줄이는 매칭 질문 세트를 선택하는 효과적인 방법은 무엇인가?
- RQ3가능한 파티션들에 대한 확률 분포를 정교화하기 위해 LLM 응답을 어떻게 통합할 수 있는가?
- RQ4MQsSP의 계산 복잡도는 무엇이며 실제로 효율적으로 근사화될 수 있는가?
주요 결과
- MQsSP는 NP-hard이며, k=1의 특수한 경우에도 (0/1 Knapsack으로 환원 가능).
- 부분모듈성을 이용한 탐욕적 근사는 예산 제약 MQ 선택 전략에 효과적이며 (1-1/e) 성능 보장을 제공한다.
- 엔트로피 기반 프레이밍은 LLM 응답을 통합할 때 불확실성 감소를 정량화할 수 있게 한다.
- 이 프레임워크는 LLM 응답과 신뢰도에 따라 파티션 분포를 조정하여 엔티티 해상도에서 비용 효율적인 불확실성 감소를 보여준다.
- 데이터세트(ACM, Amazon-eBay, Electronics)에 대한 실험은 예산 하에서 불확실성을 감소시킬 수 있으며 초기 분할에 기존 ER 도구를 사용한다는 것을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.