[논문 리뷰] On the Connection Between MPNN and Graph Transformer
논문은 가상 노드를 가진 MPNN이 그래프 트랜스포머의 자기 주의(attention)을 임의로 근사할 수 있으며, 다양한 깊이-너비 트레이드오프와 벤치마크 전반에 걸친 실험적 증거를 제공한다.
Graph Transformer (GT) recently has emerged as a new paradigm of graph learning algorithms, outperforming the previously popular Message Passing Neural Network (MPNN) on multiple benchmarks. Previous work (Kim et al., 2022) shows that with proper position embedding, GT can approximate MPNN arbitrarily well, implying that GT is at least as powerful as MPNN. In this paper, we study the inverse connection and show that MPNN with virtual node (VN), a commonly used heuristic with little theoretical understanding, is powerful enough to arbitrarily approximate the self-attention layer of GT. In particular, we first show that if we consider one type of linear transformer, the so-called Performer/Linear Transformer (Choromanski et al., 2020; Katharopoulos et al., 2020), then MPNN + VN with only O(1) depth and O(1) width can approximate a self-attention layer in Performer/Linear Transformer. Next, via a connection between MPNN + VN and DeepSets, we prove the MPNN + VN with O(n^d) width and O(1) depth can approximate the self-attention layer arbitrarily well, where d is the input feature dimension. Lastly, under some assumptions, we provide an explicit construction of MPNN + VN with O(1) width and O(n) depth approximating the self-attention layer in GT arbitrarily well. On the empirical side, we demonstrate that 1) MPNN + VN is a surprisingly strong baseline, outperforming GT on the recently proposed Long Range Graph Benchmark (LRGB) dataset, 2) our MPNN + VN improves over early implementation on a wide range of OGB datasets and 3) MPNN + VN outperforms Linear Transformer and MPNN on the climate modeling task.
연구 동기 및 목표
- MPNN(가상 노드 포함)이 그래프 트랜스포머의 자기 어텐션을 근사할 수 있는지 조사한다.
- 다른 트랜스포머 변형에서 MPNN + VN이 자기 어텐션을 근사하는 깊이-너비 트레이드오프를 특징화한다.
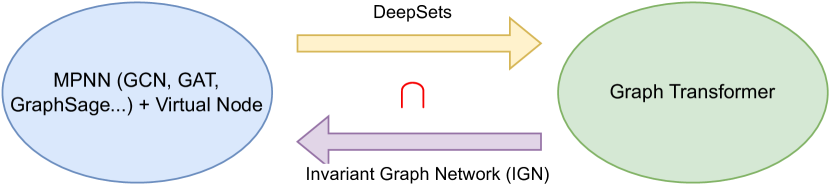
- MPNN+VN, DeepSets, 그리고 순열 등가성 universality 사이의 연결고리를 확립한다.
- LRGB 및 다른 데이터셋에서 empirical 증거를 제공하여 MPNN+VN과 GT 및 다른 베이스라인들을 비교한다.
제안 방법
- 전역 상호 작용을 모델링하기 위해 이질적 및 단순화된 이질적 MPNN + VN 계층을 정의한다.
- O(1) 깊이 및 O(1) 너비의 MPNN + VN이 Performer/Linear Transformer 자기 어텐션을 근사할 수 있음을 증명한다.
- DeepSets와의 연결고리를 활용하여 O(1) 깊이 및 O(n^d) 너비의 보편 근사성을 보인다.
- 강한 특징 가정하에 O(1) 너비 및 O(n) 깊이의 MPNN + VN이 자기 어텐션을 임의로 잘 근사하도록 구성한다.
- LRGB 및 OGB 데이터셋에서 MPNN + VN이 경쟁력 있거나 더 우수하게 작동하고, 기후 모델링 작업에서의 성능도 향상된다는 실험 결과를 제시한다.
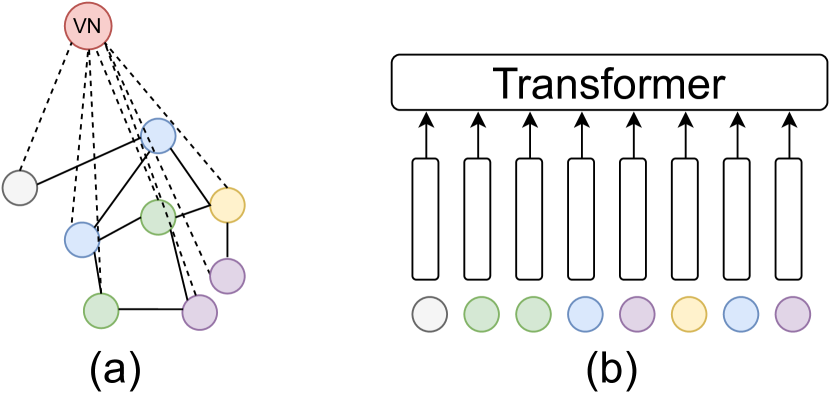
실험 결과
연구 질문
- RQ1MPNN + VN이 Graph Transformer에서 사용되는 자기 어텐션 층을 근사할 수 있는가?
- RQ2다른 트랜스포머 구성 하에서 MPNN + VN이 GT 어텐션을 재현하기에 충분한 깊이-너비 체계는 무엇인가?
- RQ3MPNN + VN 접근 방식은 DeepSets 및 순열 등가성 universality와 어떤 관련이 있는가?
- RQ4경험적 결과가 표준 그래프 벤치마크 전반에서 MPNN + VN를 강한 베이스라인으로 뒷받침하는가?
주요 결과
| Depth | Width | Self-Attention | Notes |
|---|---|---|---|
| O(1) | O(1) | Approximate | Approximate self attention in Performer (Choromanski et al., 2020 ) |
| O(1) | O(n^d) | Full | Leverage the universality of equivariant DeepSets |
| O(n) | O(1) | Full | Explicit construction, strong assumption on 𝑋 |
| O(n) | O(1) | Full | Explicit construction, more relaxed (but still strong) assumption on 𝑋 |
- O(1) 깊이 및 O(1) 너비의 MPNN + VN은 Performer/Linear Transformer의 자기 어텐션을 근사할 수 있다.
- O(1) 깊이 및 O(n^d) 너비의 MPNN + VN은 순열 등가 보편적 보증성을 가지며, 따라서 DeepSets를 통해 자기 어텐션 및 전체 트랜스포머를 근사할 수 있다.
- 특정 특징 가정하에 O(n) 깊이 및 O(1) 너비 구성이 자기 어텐션을 임의로 잘 근사하도록 존재하며, 가정은 강력하다.
- 경험적으로 MPNN + VN은 LRBG에서 일부 그래프 트랜스포머보다 성능이 우수하고, OGB 데이터셋에서 초기 MPNN+VN 구현보다 개선되며, 기후 모델링 작업에서도 Linear Transformer 및 일반 MPNN보다 우수한 성능을 보인다.
- 이론적 연결은 MPNN + VN이 두 층에서 DeepSets를 정확히 시뮬레이션할 수 있음을 보여주며, 보편 근사화 결과를 뒷받침한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.