[논문 리뷰] On the Detectability of ChatGPT Content: Benchmarking, Methodology, and Evaluation through the Lens of Academic Writing
본 논문은 GPABenchmark를 도입하여 인간과 GPT 생성의 학술 초록의 600,000개 샘플 데이터셋을 만들고, 모델-무관(detector)인 CheckGPT를 제안한다. 이는 학문 분야별 작업에서 약 98-99%의 정확도와 새로운 도메인으로의 강력한 전이를 달성한다.
With ChatGPT under the spotlight, utilizing large language models (LLMs) to assist academic writing has drawn a significant amount of debate in the community. In this paper, we aim to present a comprehensive study of the detectability of ChatGPT-generated content within the academic literature, particularly focusing on the abstracts of scientific papers, to offer holistic support for the future development of LLM applications and policies in academia. Specifically, we first present GPABench2, a benchmarking dataset of over 2.8 million comparative samples of human-written, GPT-written, GPT-completed, and GPT-polished abstracts of scientific writing in computer science, physics, and humanities and social sciences. Second, we explore the methodology for detecting ChatGPT content. We start by examining the unsatisfactory performance of existing ChatGPT detecting tools and the challenges faced by human evaluators (including more than 240 researchers or students). We then test the hand-crafted linguistic features models as a baseline and develop a deep neural framework named CheckGPT to better capture the subtle and deep semantic and linguistic patterns in ChatGPT written literature. Last, we conduct comprehensive experiments to validate the proposed CheckGPT framework in each benchmarking task over different disciplines. To evaluate the detectability of ChatGPT content, we conduct extensive experiments on the transferability, prompt engineering, and robustness of CheckGPT.
연구 동기 및 목표
- LLM-생성 학술작성의 탐지 난이도에 대한 동기 부여와 정량화.
- 탐지기 벤치마킹을 위한 포괄적이고 교차학문적 데이터셋(GPABenchmark)을 제공.
- 모델-무관(detector)인 CheckGPT를 개발하여 정확하고, 전이 가능하며, 해석가능하다는 것을 목표로 한다.
제안 방법
- GPABenchmark를 600,000 샘플로 구성하되, 인간-작성(human-written), GPT-작성(GPT-written), GPT-완성(GPT-completed), GPT-다듬은(GPT-polished) 초록을 CS, 물리학, HSS에 걸쳐 포함.
- GPABenchmark에서 세 가지 작업(GPT-WRI, GPT-CPL, GPT-POL)으로 기존 오픈소스 및 상용 탐지기(GPTZero, ZeroGPT, OpenAI의 분류기)를 평가.
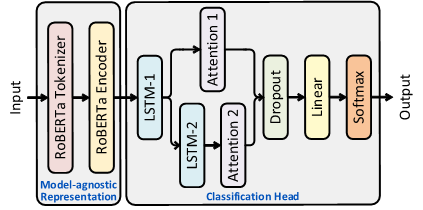
- CheckGPT를 일반적인 표현 모듈과 주의-attentive BiLSTM 분류기를 갖춘 언어모델 기반 탐지기로 설계.
- CheckGPT가 모델-무관하고 전이 가능하며 최소한의 도메인 특화 튜닝이 필요하다고 보여주기.
- 150명 이상 참가자의 인간 사용자 연구를 수행하여 GPT생성 초록의 탐지 가능성을 평가.
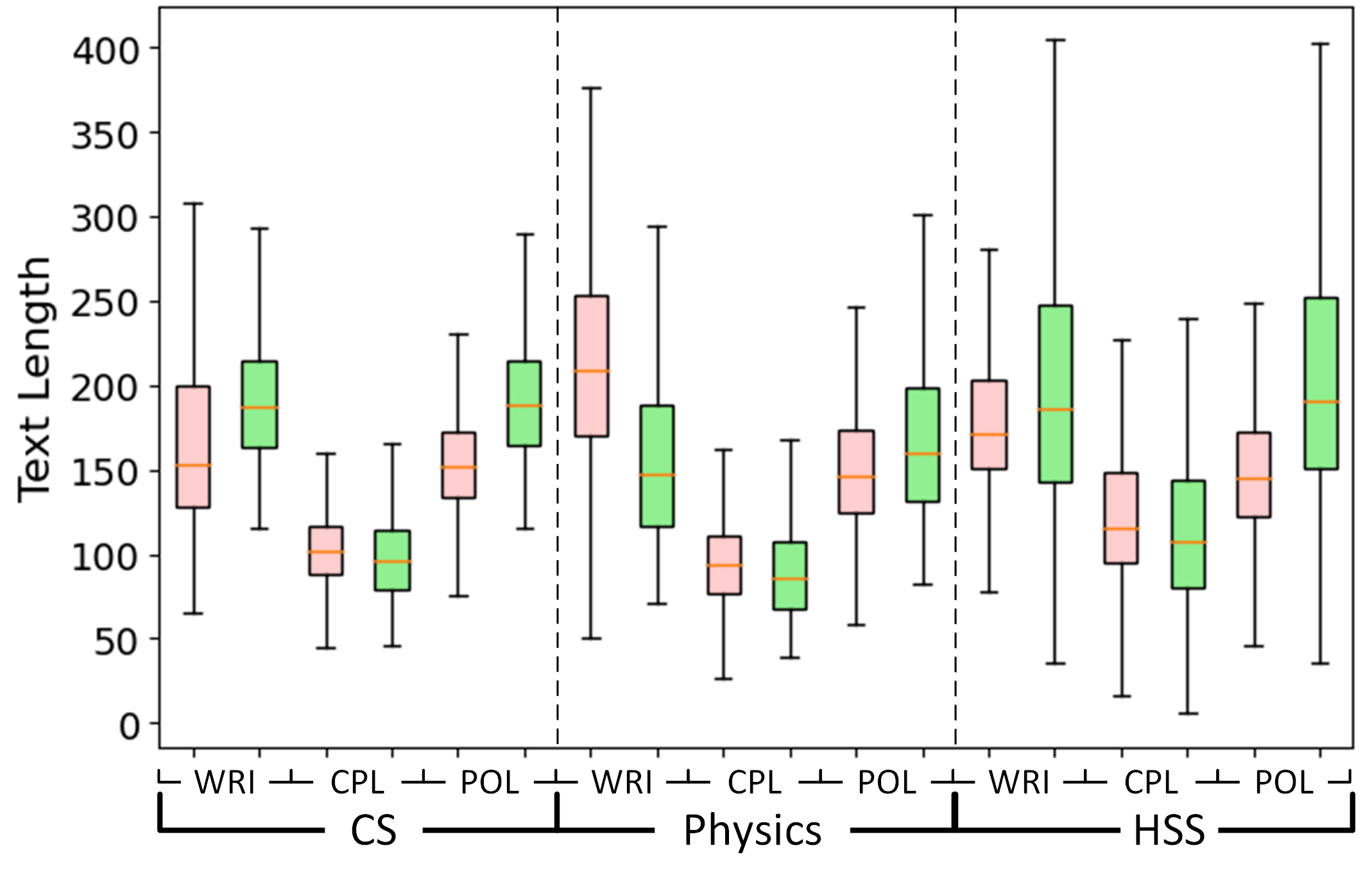
실험 결과
연구 질문
- RQ1학문 간에 GPT생성 초록을 인간이 얼마나 잘 구분할 수 있는가?
- RQ2GPABenchmark에서 최첨단 탐지기의 성능은 어떠하며 특히 GPT-다듬은 텍스트에 대해 어떤가?
- RQ3화이트 박스 접근 없이도 언어모델 기반 탐지기(CheckGPT)가 높은 정확도와 전이 가능성을 달성할 수 있는가?
- RQ4CheckGPT가 LLM 출력에 대해 생성 과정을 해석적으로 제공할 수 있는 인사이트를 어떤 형태로 제공하는가?
주요 결과
- GPABenchmark는 CS, 물리학, HSS에 걸친 인간-작성, GPT-작성, GPT-완성, GPT-다듬은 초록 600,000 샘플을 포함한다.
- 인간 평가자들은 GPT생성 초록을 식별하는 데 어려움을 겪으며, 전문가들 사이에서도 정확도는 무작위에 가까운 수준에서 다소 낮다.
- 오픈 소스 및 상용 탐지기는 GPABenchmark에서 만족스럽지 않은 성능을 보이며 특히 GPT-다듬은 텍스트에 대해 그렇다.
- CheckGPT는 작업별 탐지에서 평균 정확도 98%–99%에 도달하고, 튜닝 없이도 새로운 도메인으로의 전이 정확도가 약 90%이며 약 2,000개의 도메인 튜닝 샘플로 ~98%까지 상승한다.
- CheckGPT는 모델-무관하고 가볍고 전이 가능하며 LLM 생성 텍스트에 대한 해석 가능성 인사이트를 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.