[논문 리뷰] On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
해당 논문은 OpenAI의 o1 모델을 계획 작업에 대해 실증적으로 평가하며, 여러 벤치마크에서 타당성, 최적성, 일반화 가능성을 분석하고 GPT-4와 비교한다.
Recent advancements in Large Language Models (LLMs) have showcased their ability to perform complex reasoning tasks, but their effectiveness in planning remains underexplored. In this study, we evaluate the planning capabilities of OpenAI's o1 models across a variety of benchmark tasks, focusing on three key aspects: feasibility, optimality, and generalizability. Through empirical evaluations on constraint-heavy tasks (e.g., $ extit{Barman}$, $ extit{Tyreworld}$) and spatially complex environments (e.g., $ extit{Termes}$, $ extit{Floortile}$), we highlight o1-preview's strengths in self-evaluation and constraint-following, while also identifying bottlenecks in decision-making and memory management, particularly in tasks requiring robust spatial reasoning. Our results reveal that o1-preview outperforms GPT-4 in adhering to task constraints and managing state transitions in structured environments. However, the model often generates suboptimal solutions with redundant actions and struggles to generalize effectively in spatially complex tasks. This pilot study provides foundational insights into the planning limitations of LLMs, offering key directions for future research on improving memory management, decision-making, and generalization in LLM-based planning. Code available at https://github.com/VITA-Group/o1-planning.
연구 동기 및 목표
- 도메인 제약 하에서 o1 모델이 실행 가능한 계획을 어떻게 생성하는지 평가한다.
- 행동 효율성과 중복성에 초점을 맞춰 o1 모델이 생성한 계획의 최적성을 평가한다.
- 보지 못한 작업이나 기호적으로 표현된 작업에 대한 o1 모델의 일반화 가능성을 조사한다.
- 메모리/의사결정 과정에서 흔한 계획 오류와 병목 현상을 식별한다.
- 자기평가와 기억 기술을 통한 LLM 기반 계획 개선 방향을 제시한다.
제안 방법
- GPT-4, o1-mini, o1-preview를 사용하여 Barman, Blocksworld, Floortile, Grippers, Tyreworld, Termes 등의 계획 작업 집합을 벤치마크한다.
- 오류를 타당성(IR, IP, MG) 및 최적성(LO)으로 분류하고, 성공/타당성 및 최적성 비율을 측정한다.
- 공간적 및 행동 복잡성에 걸친 성능을 분석하여 병목 현상을 식별한다.
- 계획 중에 행동을 평가하고 수정하기 위해 o1-preview의 자기평가 메커니즘을 활용한다.
- 추상적/기호적 작업 표현(무작위화된 Tyreworld)으로 일반화를 테스트하여 비교한다.
- 메모리 관리, 제약 이행, 일반화의 한계를 강조하고 향후 방향을 제시한다.
실험 결과
연구 질문
- RQ1다양한 계획 도메인에서 o1 모델이 생성한 계획의 타당성은 어느 정도인가?
- RQ2o1 모델이 GPT-4보다 더 최적(효율적인) 계획을 생성하는가, 그렇다면 어디에서 여전히 미흡한가?
- RQ3o1 모델이 추상적이거나 기호적으로 표현된 작업에 대해 계획 전략을 일반화할 수 있는가?
- RQ4o1 모델에서 관찰되는 주요 계획 오류(IR, IP, MG, LO)의 유형은 무엇이며 도메인에 따라 어떻게 다른가?
- RQ5계획 성능에 영향을 주는 메모리, 상태 관리, 공간 추론의 주요 병목은 무엇인가?
주요 결과
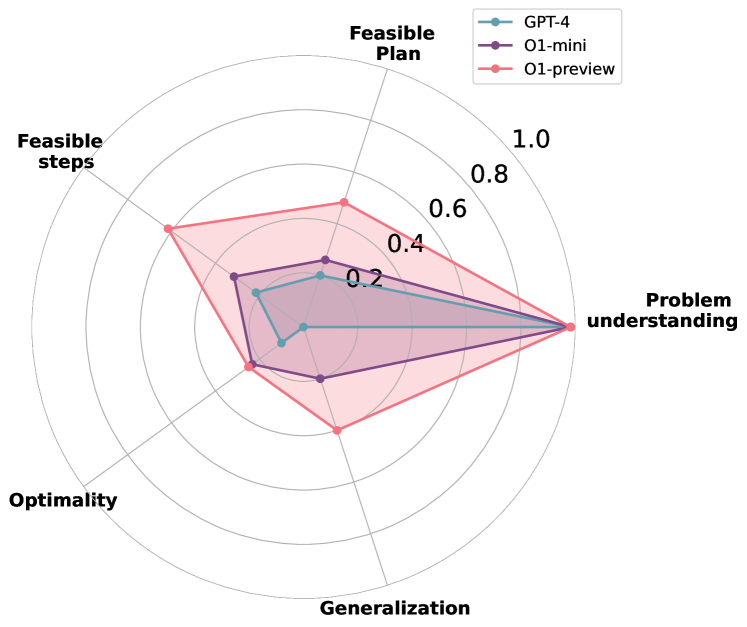
- o1-preview는 여러 도메인에서 GPT-4 및 o1-mini보다 일반적으로 더 높은 성공률을 달성하며, 일부 경우 Blocksworld와 Tyreworld 테스트 세트에서 완전한 성공을 보인다.
- o1-preview는 제약 이행과 자기평가를 향상시키지만 Termes와 같은 복잡한 공간에서 여전히 비최적 계획(LO) 및 오해(MG)가 나타난다.
- GPT-4는 제약 준수 및 계획 효율성에서 종종 저조하며, 특히 더 공간적으로 복잡한 작업에서 그렇다.
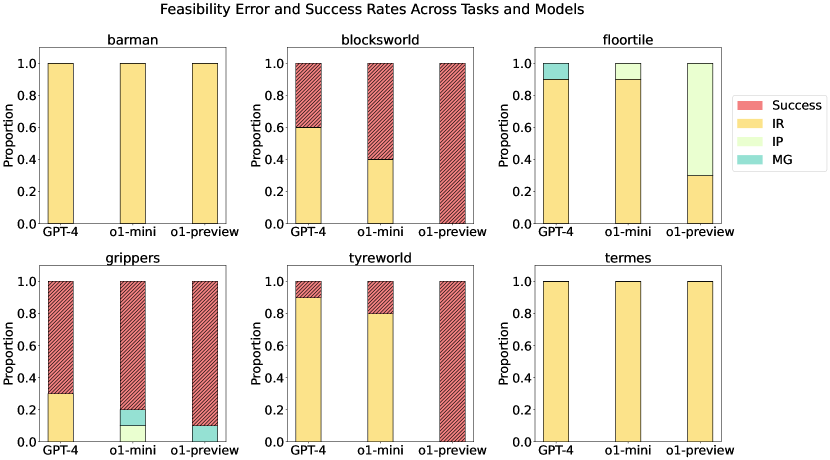
- Floortile은 모든 모델에서 광범위한 실패를 보이며, IR 오류가 GPT-4와 o1-mini를 지배하지만, o1-preview는 IR 발생을 감소시키되 다른 오류에 직면한다.
- Grippers 작업에서 o1-preview는 최대 90%의 성공과 70%의 최적성을 달성하는 것으로 나타나 많은 경우 GPT-4 및 o1-mini를 능가한다.
- 일반화 테스트는 o1-preview가 구조화된 일반화(Grippers)를 GPT-4보다 더 잘 처리하지만, 추상적 기호 표현(randomized Tyreworld)에서는 성능이 저하됨을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.