[논문 리뷰] On the Variance of Neural Network Training with respect to Test Sets and Distributions
본 논문은 서로 독립적인 학습 실행 간의 테스트 세트 분산이 주로 유한 표본 노이즈와 초기 조건 민감성 때문이며, 수렴 훈련에서 분포-wise 분산은 작아진다고 주장하고; 앙상블 보정은 불가피하지만 한계가 있는 테스트 세트 분산을 시사한다.
Typical neural network trainings have substantial variance in test-set performance between repeated runs, impeding hyperparameter comparison and training reproducibility. In this work we present the following results towards understanding this variation. (1) Despite having significant variance on their test-sets, we demonstrate that standard CIFAR-10 and ImageNet trainings have little variance in performance on the underlying test-distributions from which their test-sets are sampled. (2) We show that these trainings make approximately independent errors on their test-sets. That is, the event that a trained network makes an error on one particular example does not affect its chances of making errors on other examples, relative to their average rates over repeated runs of training with the same hyperparameters. (3) We prove that the variance of neural network trainings on their test-sets is a downstream consequence of the class-calibration property discovered by Jiang et al. (2021). Our analysis yields a simple formula which accurately predicts variance for the binary classification case. (4) We conduct preliminary studies of data augmentation, learning rate, finetuning instability and distribution-shift through the lens of variance between runs.
연구 동기 및 목표
- Independent training runs 사이의 테스트 세트 정확도 분산의 원인을 조사한다.
- 최고 성능 실행이 테스트 분포에서 평균 이상으로 일반화되는지 여부를 결정한다.
- 분산에 영향을 주는 하이퍼파라미터나 학습 측면을 식별한다.
- 테스트 세트 분산과 분포-wise 분산 및 앙상블 보정 간의 통계적 프레임워크를 개발한다.
제안 방법
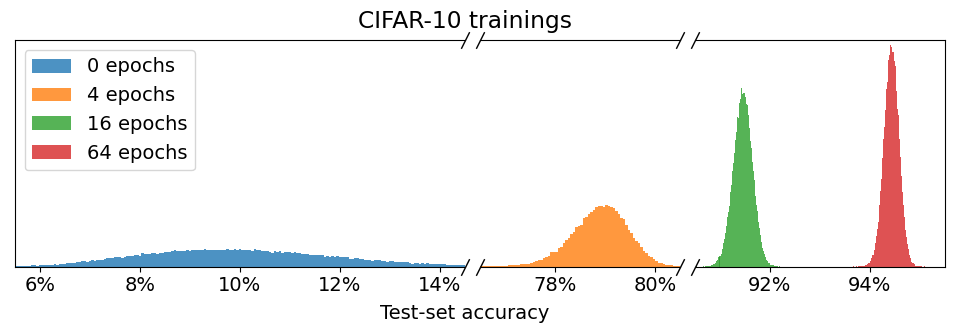
- CIFAR-10과 ImageNet에서 약 350,000개의 네트워크를 실험적으로 학습하여 분산 특성을 파악한다.
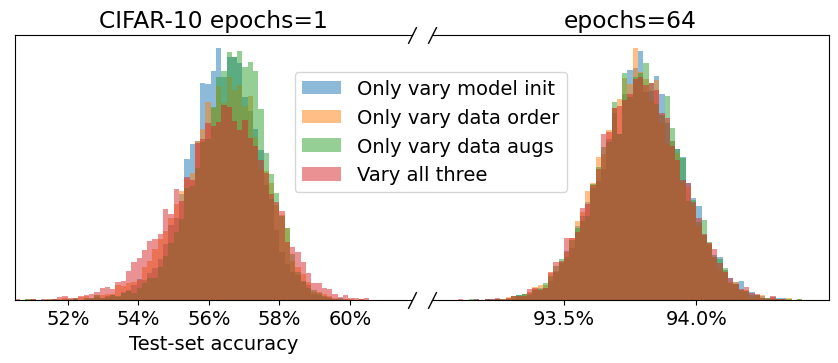
- 무작위성의 원인을 제어한다(모델 초기화, 데이터 순서, 증강 등)으로 그 효과를 분리한다.
- Hypothesis 1 (example-wise independence)을 제시하여 테스트 정확도 분포를 모델링한다.
- 분포-wise 분산에 대한 바이어스 없는 추정량(Equation 2)을 도출한다.
- 테스트 세트 분산과 앙상블 보정 간의 이론적 관계를 정리한다(정리 3–5).
실험 결과
연구 질문
- RQ1독립적인 학습 실행 간의 분산을 유발하는 원인은 무엇이며 어떤 무작위성 소스가 가장 큰 책임이 있는가?
- RQ2테스트 세트에서 최고 성능 실행을 선택하는 것이 테스트 분포에 대해 평균 이상으로 일반화되는 것을 시사하는가?
- RQ3테스트 세트 분산과 분포-wise 분산에 영향을 주는 하이퍼파라미터는 무엇인가?
- RQ4유한한 테스트 샘플로부터 분포-wise 분산을 추정하고 이를 앙상블 보정과 어떻게 연관지을 수 있는가?
- RQ5분포 이동, 데이터 증강, 학습률 변화 하에서 분산은 어떻게 변하는가?
주요 결과
- 실행 간 분산은 주로 초기 조건에 대한 극단적 민감도 때문이며, 어떤 특정 무작위성 소스 때문이라 보기 어렵다.
- 훈련이 수렴함에 따라 분리된 테스트 분할 간 상관관계가 약해지므로 분포-wise 정확도에 실제로 큰 분산이 존재하지 않음을 시사한다.
- 바이어스 없는 추정량은 CIFAR-10의 분포-wise 분산이 수렴 후 약 0.033%까지, ImageNet은 약 0.034%까지 낮아질 수 있음을 보인다.
- 앙상블 보정은 분류 작업에서 실행 간 양의 테스트 세트 분산을 시사한다.
- BERT-Large 미세조정은 BERT-Base보다 분포-wise 분산이 훨씬 높게 나타나 모델 크기가 불안정성에 영향을 준다는 것을 시사한다.
- 분포 이동이 있는 테스트 세트는 실행 간 분산이 도메인 내 세트보다 더 크게 나타나며, 데이터 증강은 분산을 감소시킨다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.