[논문 리뷰] One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization
피드포워드 방식은 단일 이미지를 보기 조건부 2D 확산 모델과 일반화 가능한 SDF 기반 재구성을 결합하여 per-shape 최적화를 피하고 약 45초 만에 전체 360° 텍스처드 3D 메시로 변환합니다.
Single image 3D reconstruction is an important but challenging task that requires extensive knowledge of our natural world. Many existing methods solve this problem by optimizing a neural radiance field under the guidance of 2D diffusion models but suffer from lengthy optimization time, 3D inconsistency results, and poor geometry. In this work, we propose a novel method that takes a single image of any object as input and generates a full 360-degree 3D textured mesh in a single feed-forward pass. Given a single image, we first use a view-conditioned 2D diffusion model, Zero123, to generate multi-view images for the input view, and then aim to lift them up to 3D space. Since traditional reconstruction methods struggle with inconsistent multi-view predictions, we build our 3D reconstruction module upon an SDF-based generalizable neural surface reconstruction method and propose several critical training strategies to enable the reconstruction of 360-degree meshes. Without costly optimizations, our method reconstructs 3D shapes in significantly less time than existing methods. Moreover, our method favors better geometry, generates more 3D consistent results, and adheres more closely to the input image. We evaluate our approach on both synthetic data and in-the-wild images and demonstrate its superiority in terms of both mesh quality and runtime. In addition, our approach can seamlessly support the text-to-3D task by integrating with off-the-shelf text-to-image diffusion models.
연구 동기 및 목표
- 범주에 상관없이 일반적인 단일 이미지에서 3D 재구성 솔루션을 motivate한다.
- 강력한 2D 확산 priors를 활용하여 3D 리프팅을 위한 다중 뷰 예측을 생성한다.
- 피드-포워드이고 최적화가 필요 없는 360° 메시 재구성 파이프라인을 개발한다.
- 입력 이미지에 최대한 밀접하게 맞추면서 기하학적 품질과 3D 일관성을 향상시킨다.
제안 방법
- 단일 입력 이미지로부터 다중 뷰 이미지를 생성하기 위해 뷰 조건부 2D 확산 모델 (Zero123)을 사용한다.
- 입력 뷰 고도를 추정하고 다중 뷰 세트의 카메라 포즈를 구성한다.
- 비용-볼륨 기반의 일반화 가능한 신경 표면 재구성(SparseNeuS)을 적용하여 한 번의 패스에서 텍스처링된 3D 메쉬를 생성한다.
- 일관되지 않은 다중 뷰 예측을 다루기 위해 2단계 소스 뷰 선택과 정답-예측 혼합 감독으로 훈련한다.
- Zero123 뷰포인트를 재구성 좌표계에 맞추기 위한 고도 추정 모듈을 도입한다.
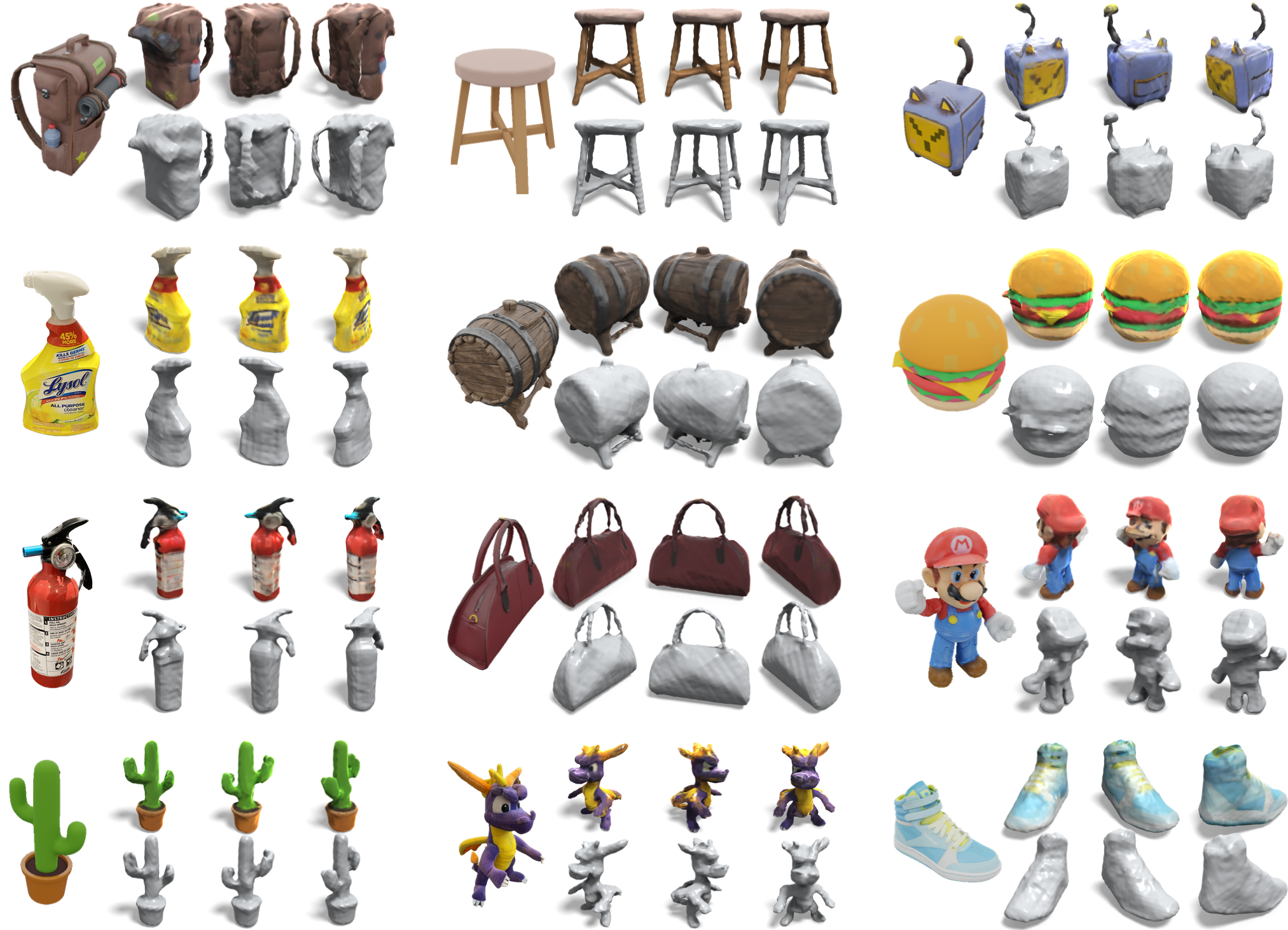
실험 결과
연구 질문
- RQ1단일 이미지로 per-shape 최적화 없이 고품질의 텍스처링된 360° 메쉬로 리프팅할 수 있는가?
- RQ2보이지 않는 객체 범주에서 robust한 3D 재구성을 위해 2D 확산 priors를 효과적으로 어떻게 활용할 수 있는가?
- RQ3불완전한 다중 뷰 예측을 단일 전방향 패스로 재구성과 일치시키기 위한 학습 전략과 자세 추정 메커니즘은 무엇이 필요한가?
주요 결과
- 이 방법은 per-shape 최적화 없이 단일 이미지에서 약 45초 만에 전체 360° 텍스처링된 메쉬를 재구성한다.
- 2단계 뷰 선택 및 깊이 감독이 있는 SparseNeuS를 사용하면 예측 뷰에서 NeRF/SDF 최적화보다 360° 기하학 및 3D 일관성이 더 좋아진다.
- 고도 추정은 일관된 카메라 포즈를 가능하게 할 만큼 정확하여 올바른 3D 재구성에 중요하다.
- 이 접근법은 경쟁력 있는 제로샷 및 최적화 기반 기준선 대비 기하학적 적합도와 입력 이미지에의 준수성을 유지하면서 실행 시간도 경쟁력 있게 달성한다.
- 일반 프레임워크를 오프더셋 2D 텍스트-투-이미지 확산 모델과 결합하여 텍스트-투-3D로 확장될 수 있다.
![Figure 2: Our method consists of three primary components: (a) Multi-view synthesis : we use a view-conditioned 2D diffusion model, Zero123 [ 36 ] , to generate multi-view images in a two-stage manner. The input of Zero123 includes a single image and a relative camera transformation, which is parame](https://ar5iv.labs.arxiv.org/html/2306.16928/assets/figures/pipeline.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.