[논문 리뷰] OpenAssistant Conversations -- Democratizing Large Language Model Alignment
The paper releases OpenAssistant Conversations, a large, multilingual, human-generated dataset for aligning LLMs, and demonstrates its usefulness by training and evaluating SFT, RM, and RLHF models on open architectures.
Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT. Alignment techniques such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains. However, state-of-the-art alignment techniques like RLHF rely on high-quality human feedback data, which is expensive to create and often remains proprietary. In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages in 35 different languages, annotated with 461,292 quality ratings, resulting in over 10,000 complete and fully annotated conversation trees. The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers. Models trained on OpenAssistant Conversations show consistent improvements on standard benchmarks over respective base models. We release our code and data under a fully permissive licence.
연구 동기 및 목표
- LLM 정렬을 위한 고품질 인간 피드백 데이터에 대한 접근성을 대폭 확장하기 위해 방대한 오픈 데이터세트를 공개한다.
- 데이터세트의 안전성, 윤리성, 모더레이션 영향성을 평가한다.
- SFT, 보상 모델(RM), RLHF 기반 모델을 오픈 아키텍처 상에서 학습·평가하여 데이터세트의 활용성을 입증한다.
제안 방법
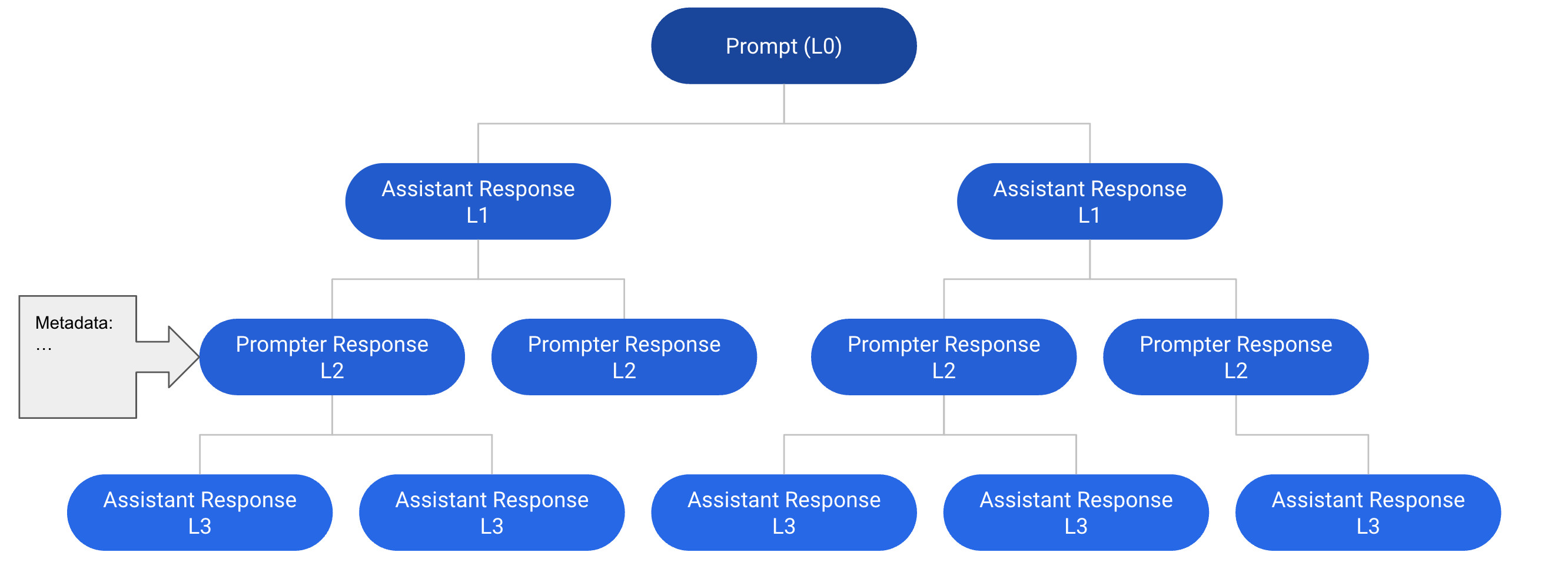
- OpenAssistant Conversations 데이터세트에는 161,443개의 메시지, 66,497개의 트리, 35개 언어, 461,292개의 품질 등급이 포함되어 있다.
- 크라우드소싱을 통한 다섯 가지 작업 유형으로 데이터 수집: prompting, as assistant로서의 reply, as prompter로서의 reply, labeling, ranking.
- 트리 상태 기계가 대화 트리의 생성, 성장, 완료를 관리하며, 보상, 리더보드, 인간 검토를 통한 모더레이션 및 품질 관리가 이루어진다.
- Pythia, Falcon, LLaMA와 같은 오픈 모델에서 SFT 모델, 보상 모델(RM), 및 RLHF 모델을 학습시키고 표준 벤치마크로 평가한다.
- 대 baselines 대비 OpenAssistant Conversations를 활용한 모델이 여러 벤치마크에서 우수한 성능을 보임.
실험 결과
연구 질문
- RQ1큰 규모의 개방형 인간 주석 대화 데이터가 LLM 정렬 기반 미세조정의 개선을 이끌 수 있는가?
- RQ2OpenAssistant Conversations로 학습된 SFT, RM, RLHF 모델이 기준 벤치마크에서 베이스라인과 비교해 어떤 성능 차이를 보이는가?
- RQ3이러한 데이터세트의 안전성, 독성, 모더레이션 특성은 어떠하며 자동 독성 측정지표가 인간 평가와 얼마나 일치하는가?
- RQ4자원봉사자 주도 개방 데이터 수집 과정에서 생기는 편향이나 한계는 무엇이며 모델 행태에 어떤 영향을 주는가?
- RQ5재현성 및 책임 있는 연구를 극대화하기 위해 데이터와 모델을 어떻게 공개해야 하는가?
주요 결과
- OpenAssistant Conversations는 161,443개의 메시지(요청자 91,829명; 도우미 69,614명), 66,497개의 트리, 35개 언어, 461,292개의 품질 등급을 포함한다.
- 이 데이터로 학습된 모델은 표준 벤치마크에서 해당 기본 모델들보다 일관된 개선를 보인다.
- RLHF는 SFT에 비해 일부 벤치마크에서 성능을 향상시키지만 모든 작업에서 균일하지는 않으며 데이터세트와 평가의 뉘앙스를 시사한다.
- 자동 독성 측정치(Detoxify)는 인간 레이블과 어느 정도 상관관계가 있으며, 모더레이션은 독성 콘텐츠를 크게 감소시키지만 비독성 메시지가 다른 이유로도 제거될 수 있다.
- 데이터세트와 모델은 개방형 연구를 가능하게 하는 관대 한 라이선스로 배포되며, 편향과 안전성 고려 사항을 인식한다.
- 사용자 연구 및 인구통계 분석은 일부 차원에서 기여자 간 균질성을 드러내고 uneven 참여로 인한 편향 가능성을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.