[논문 리뷰] Overcoming catastrophic forgetting with hard attention to the task
논문은 거의 이진(attention) 마스크를 층당 학습하는 작업 기반 하드 어텐션 메커니즘(HAT)을 도입하여 이전 작업의 정보를 보존하면서 새로운 작업을 학습하고, 망각을 크게 줄이며 모델 압축을 가능하게 한다.
Catastrophic forgetting occurs when a neural network loses the information learned in a previous task after training on subsequent tasks. This problem remains a hurdle for artificial intelligence systems with sequential learning capabilities. In this paper, we propose a task-based hard attention mechanism that preserves previous tasks' information without affecting the current task's learning. A hard attention mask is learned concurrently to every task, through stochastic gradient descent, and previous masks are exploited to condition such learning. We show that the proposed mechanism is effective for reducing catastrophic forgetting, cutting current rates by 45 to 80%. We also show that it is robust to different hyperparameter choices, and that it offers a number of monitoring capabilities. The approach features the possibility to control both the stability and compactness of the learned knowledge, which we believe makes it also attractive for online learning or network compression applications.
연구 동기 및 목표
- 순차적 작업 학습에서의 재앙적 망각을 동기 부여하고 해결한다.
- 작업 식별에 조건화된 경량의 학습 가능한 하드 어텐션 메커니즘을 개발한다.
- 그라디언트 업데이트를 제약하여 오래된 작업 재학습 없이 동시 학습을 가능하게 한다.
- 모델 희소성을 촉진하고 실제 배치를 위한 모니터링/압축 기능을 제공한다.
제안 방법
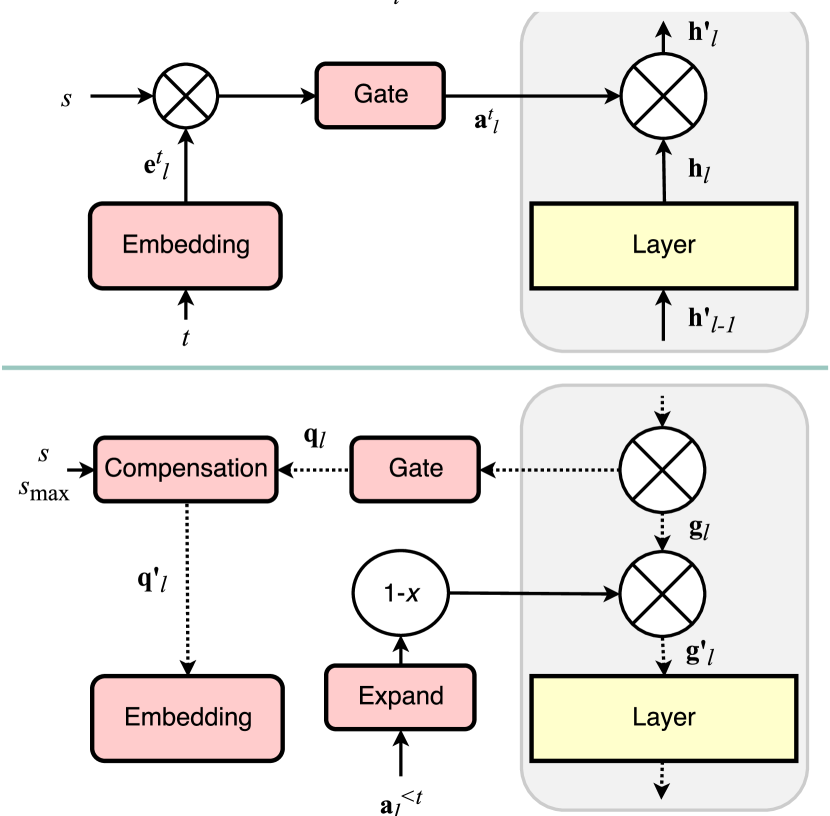
- 스케일링 매개변수 s를 가진 시그모이드 게이트를 사용하여 미분 가능한 태스크 임베딩 e_l^t로부터 도출된 층별 하드 어텐션 마스크 a_l^t를 도입한다.
- 과거 작업들에 대한 원소별 최댓값을 취하여 중요한 유닛을 보존하기 위해 누적 어텐션 a^≤t를 계산한다.
- 이전 작업에 중요한 유닛의 업데이트를 패널티하는 연결당 게이팅 항을 이용하여 a^≤t로 그라디언트를 수정한다.
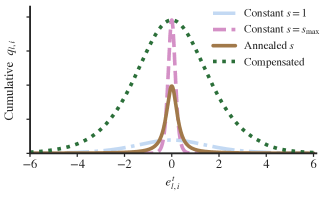
- 학습 에폭에 걸쳐 게이팅 파라미터 s를 어닐링하여 가소성과 안정성의 균형을 맞추고, 효과적인 학습 신호를 유지하기 위해 임베딩 그라디언트 보상(보정)을 수행한다.
- 주목(attention) 가중 L1 정규화 항을 추가하여 across tasks에서 유닛의 희소한 사용을 촉진한다(압축 가능 매개변수 c).
- 표준화된 아키텍처와 평가 프로토콜을 사용하여 8개의 다양한 이미지 데이터셋에서 HAT을 기반선(EWC, SI, LWF, LFL, PathNet, PNN, IMM 변형)과 비교한다.
실험 결과
연구 질문
- RQ1다양한 작업 시퀀스에서 HAT가 최신기술 베이스라인에 비해 재앙적 망각을 얼마나 효과적으로 줄이는가?
- RQ2망각 감소가 하이퍼파라미터 선택 및 작업 순서에 대해 얼마나 강건한가?
- RQ3HAT가 용량 사용량, 가중치 재사용 등의 모니터링 기능을 제공하고 정확도를 해치지 않으면서 모델 압축을 지원할 수 있는가?
- RQ4여러 평가 설정(다중 작업, 증분 클래스, 순열화된 데이터셋)에서 HAT의 성능은 어떠한가?
주요 결과
- HAT는 t≥2 작업에서 베이스라인을 일관되게 능가하며, 주된 8-작업 시퀀스에서 ρ≤2는 -0.02, ρ≤8은 -0.06를 달성하며(베이스라인에 비해 55%-75%의 망각 감소).
- 8개 작업에서 평균적으로 설정에 따라 망각을 45%에서 75%까지 감소시키며, 많은 베이스라인보다 분산이 작다.
- HAT는 네트워크 용량 사용 및 가중치 재사용에 대한 모니터링을 가능하게 하며 원래 크기의 1%–21%로의 압축을 지원하면서도 높은 정확도를 유지한다.
- 추가 설정들(증분 클래스, 순열 MNIST, 분할 MNIST)에서 HAT는 강력한 베이스라인에 비해 두드러진 개선을 달성했다(예: CIFAR 증분 클래스: 약 55% 망각 감소; 순열 MNIST: 약 52% 감소; 분할 MNIST: 약 80% 감소).
- HAT의 두 하이퍼파라미터(안정성 s_max과 압축성 c)는 광범위한 범위에서 견고한 성능을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.