[논문 리뷰] Perception Test: A Diagnostic Benchmark for Multimodal Video Models
본 논문은 기억, 추상화, 물리, 의미를 비디오, 오디오, 텍스트 전반에 걸쳐 평가하는 현실 세계 다중모달 비디오 벤치마크 Perception Test를 소개하며, 묘사적·설명적·예측적·반사실적 추론과 밀집 주석, 보유된 테스트 서버를 제공합니다.
We propose a novel multimodal video benchmark - the Perception Test - to evaluate the perception and reasoning skills of pre-trained multimodal models (e.g. Flamingo, SeViLA, or GPT-4). Compared to existing benchmarks that focus on computational tasks (e.g. classification, detection or tracking), the Perception Test focuses on skills (Memory, Abstraction, Physics, Semantics) and types of reasoning (descriptive, explanatory, predictive, counterfactual) across video, audio, and text modalities, to provide a comprehensive and efficient evaluation tool. The benchmark probes pre-trained models for their transfer capabilities, in a zero-shot / few-shot or limited finetuning regime. For these purposes, the Perception Test introduces 11.6k real-world videos, 23s average length, designed to show perceptually interesting situations, filmed by around 100 participants worldwide. The videos are densely annotated with six types of labels (multiple-choice and grounded video question-answers, object and point tracks, temporal action and sound segments), enabling both language and non-language evaluations. The fine-tuning and validation splits of the benchmark are publicly available (CC-BY license), in addition to a challenge server with a held-out test split. Human baseline results compared to state-of-the-art video QA models show a substantial gap in performance (91.4% vs 46.2%), suggesting that there is significant room for improvement in multimodal video understanding. Dataset, baseline code, and challenge server are available at https://github.com/deepmind/perception_test
연구 동기 및 목표
- 사전 학습된 다중모달 모델의 다양 한 지각 기술에 대한 전이 성능을 평가(제로샷, 몇 샷, 또는 제한된 파인튜닝 포함).
- 메모리, 추상화, 물리, 의미를 탐색하기 위한 밀집 주석의 현실 세계 비디오 데이터셋 제공.
- 다양한 애노테이션 형식(추적, 구간, Q&A)을 통해 모델 편향 및 교차 작업 상관관계 분석 가능하도록 공개 학습/검증 분할 및 보유 테스트 서버 제공.
- 여러 애노테이션 유형을 통한 모델 편향 및 실패 모드에 대한 인사이트 제공
제안 방법
- 다양한 기술을 탐구하기 위해 37개의 실제 세계 스크립트 비디오를 설계하고 언어 편향을 피하기 위한 변형 도입.
- 비디오를 여섯 가지 유형의 라벨로 주석화: 객체 트랙, 포인트 트랙, 시간적 액션 구간, 시간적 소리 구간, mc-vQA, 그리고 근거 기반 vQA.
- 작업별 평가 지표를 갖춘 여섯 가지 계산 작업(트래킹, 로컬라이제이션, 비디오 QA) 정의.
- 일반화 능력을 평가하기 위해 제로샷 또는 몇 샷 설정을 사용하는 per-task 베이스라인 제공.
- 재현 가능한 평가를 돕기 위한 오픈소스 비디오, 주석 및 챌린지 서버 공개.
- 모델 성능을 인간 능력과 맥락화하기 위한 mc-vQA에 대한 인간 베이스라인 포함

실험 결과
연구 질문
- RQ1사전 학습된 다중모달 비디오 모델이 제로샷, 몇 샷, 또는 제한된 파인튜닝(regime)에서 기억, 추상화, 물리, 의미 작업으로 일반화할 수 있는가?
- RQ2다양한 추론 유형(묘사적, 설명적, 예측적, 반사실적) 및 모달리티(video, audio, text) 간 모델 성능 차이는 어떠한가?
- RQ3현실 세계 진단 벤치마크에서 인간 성능과 최첨단 모델 간의 차이는 무엇인가?
- RQ4추적(트래킹), 구간, QA를 포함한 결합 주석이 모델의 편향과 실패 모드에 대해 어떤 인사이트를 제공하는가?
주요 결과
| Task | Output | Metric | Baseline | Score |
|---|---|---|---|---|
| 객체 추적 | box track | Avg. IoU | SiamFC [8] | 0.67 |
| 포인트 추적 | point track | Avg. Jaccard | TAP-Net [19] | 0.401 |
| 시간적 동작 위치 추정 | list of action segments | mAP | ActionFormer [57] | 15.56 |
| 시간적 소리 로컬라이제이션 | list of sound segments | mAP | ActionFormer [57] | 15.46 |
| 다지선다형 비디오QA | answer (1 out of 3) | top-1 accuracy | SeViLA [55] | 46.2 |
| 근거 기반 비디오QA | list of box tracks | HOTA | MDETR [34] + Stark [52] | 0.1 |
- 11.6k real-world videos (23s average) with dense, multi-type annotations enable thorough multimodal evaluation.
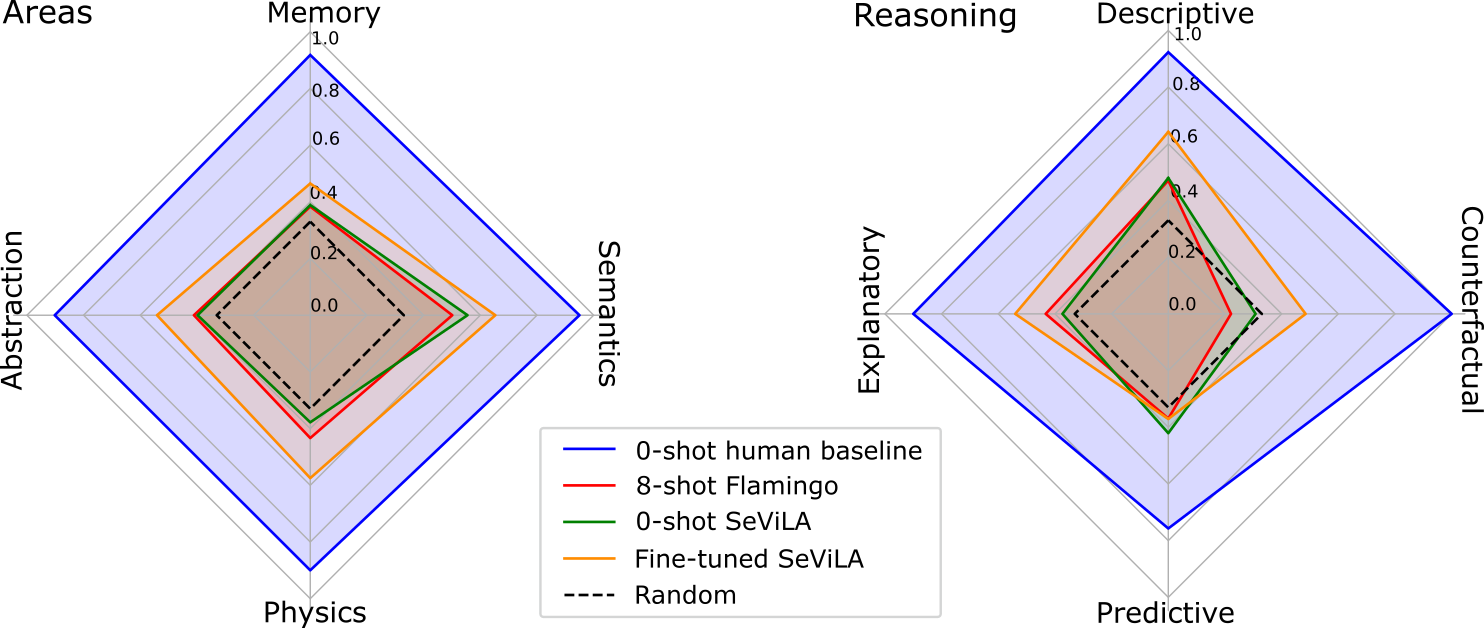
- 사람은 mc-vQA에서 91.4%를 달성하는 반면 최첨단 모델은 제로샷/몇 샷 설정에서 46.2%로 뒤처져 개선 여지가 크다.
- Perception Test는 기억, 물리, 추상화 영역에서 모델의 약점을 드러내며 일부 작업에서 단순 베이스라인보다 낮은 성능을 보인다.
- Baseline 결과는 작업별 최고를 보인다: 객체 추적 IoU 0.67, 포인트 추적 Jaccard 0.401, 액션 로컬라이제이션 mAP 15.56, 소리 로컬라이제이션 mAP 15.46, mc-vQA 정확도 46.2, 근거 기반 vQA IoU 0.1.
- 데이터셋은 일반화 중심의 평가를 지원하며, 학습/검증 분할과 보유 테스트 서버를 통해 작업 간 전이 능력을 탐색한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.