[논문 리뷰] pixelNeRF: Neural Radiance Fields from One or Few Images
pixelNeRF는 픽셀-정렬된 이미지 특징에 조건을 걸고 여러 뷰를 집계하여 테스트 시 최적화 없이도 한 장 또는 몇 장의 입력 이미지로부터 새로운 시점을 합성할 수 있는 이미지-조건의 피드포워드 NeRF를 학습한다.
We propose pixelNeRF, a learning framework that predicts a continuous neural scene representation conditioned on one or few input images. The existing approach for constructing neural radiance fields involves optimizing the representation to every scene independently, requiring many calibrated views and significant compute time. We take a step towards resolving these shortcomings by introducing an architecture that conditions a NeRF on image inputs in a fully convolutional manner. This allows the network to be trained across multiple scenes to learn a scene prior, enabling it to perform novel view synthesis in a feed-forward manner from a sparse set of views (as few as one). Leveraging the volume rendering approach of NeRF, our model can be trained directly from images with no explicit 3D supervision. We conduct extensive experiments on ShapeNet benchmarks for single image novel view synthesis tasks with held-out objects as well as entire unseen categories. We further demonstrate the flexibility of pixelNeRF by demonstrating it on multi-object ShapeNet scenes and real scenes from the DTU dataset. In all cases, pixelNeRF outperforms current state-of-the-art baselines for novel view synthesis and single image 3D reconstruction. For the video and code, please visit the project website: https://alexyu.net/pixelnerf
연구 동기 및 목표
- 매우 적은 입력 뷰로부터의 새로운 시점 합성을 촉진하고 가능하게 하기 위한 목적은 여러 장면에 걸친 장면 사전을 학습하는 것이다.
- 보이는 물체와 범주에 대해 이전에 각 장면별로 최적화하던 것을 일반화 가능한 피드포워드 모델로 대체한다.
- 시공간에서 픽셀 정렬된 이미지 특징을 뷰 공간에서 조건으로 사용하여 공간 정렬을 보존한다.
- 테스트 시점에 최적화 없이 가변 개수의 입력 뷰를 허용한다.]
- method:[
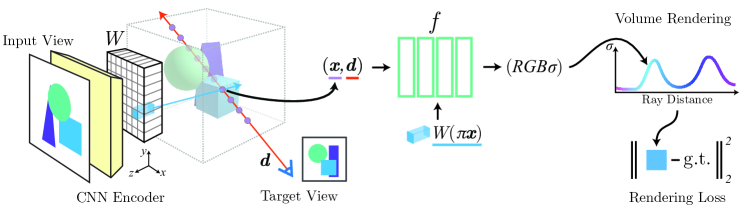
- Compute a fully convolutional image feature grid from input images and sample per-pixel features for query points via projection and bilinear interpolation.
- Condition the NeRF network on spatial image features by adding them as a residual to each layer of the NeRF MLP.
- For multiple input views, encode each view into a feature volume, project to each view, process separately with an initial NeRF block, then aggregate via averaging before final layers to predict density and color.
- Operate in camera/view space rather than a canonical scene space to improve generalization to unseen categories and multi-object scenes.
- Train end-to-end with a volume rendering loss comparing rendered and ground-truth images, without requiring explicit 3D supervision.
- Extend from single-view to multi-view inputs by aggregating information across views, enabling few-shot reconstruction.
제안 방법
- Compute a fully convolutional image feature grid from input images and sample per-pixel features for query points via projection and bilinear interpolation.
- Condition the NeRF network on spatial image features by adding them as a residual to each layer of the NeRF MLP.
- For multiple input views, encode each view into a feature volume, project to each view, process separately with an initial NeRF block, then aggregate via averaging before final layers to predict density and color.
- Operate in camera/view space rather than a canonical scene space to improve generalization to unseen categories and multi-object scenes.
- Train end-to-end with a volume rendering loss comparing rendered and ground-truth images, without requiring explicit 3D supervision.
- Extend from single-view to multi-view inputs by aggregating information across views, enabling few-shot reconstruction.
실험 결과
연구 질문
- RQ1하나의 입력 이미지 또는 소수의 입력 이미지로도 다수의 장면에 대해 학습했을 때 장면의 일관된 NeRF 표현을 예측할 수 있는가?
- RQ2픽셀-정렬된 이미지 특징으로 NeRF를 조건화하는 것이 명시적 3D 감독 없이도 본 적 없는 카테고리 및 다중 객체 장면으로 일반화할 수 있는가?
- RQ3뷰 공간 조건화와 다중 뷰 집계가 ShapeNet 및 실제 세계 데이터셋의 새로운 시점 합성 품질에 어떤 영향을 미치는가?
- RQ4테스트 시점에 최적화 없이 가변 개수의 입력 뷰를 지원할 수 있는가?
주요 결과
- PixelNeRF는 SRN 및 DVR 기준선에 비해 few-shot 새로운 시점 합성 벤치마크에서 최첨단(또는 유사한) 성능을 달성한다.
- 합성 데이터와 제한된 장면에도 불구하고 본 적 없는 객체 카테고리 및 실제 이미지(DTU)에 일반화한다.
- 지역적이고 픽셀 정렬된 이미지 특징을 사용하고 뷰 방향을 포함시키는 것이 전역 잠재 코드보다 재구성 품질과 디테일을 향상시킨다.
- 다중 뷰 조건화는 다중 객체 장면에서 정확한 360도 재구성을 가능하게 하며, 자동차 이미지에 대해 시뮬레이션-실제 간 전이를 시연한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.