[논문 리뷰] Plan-Seq-Learn: Language Model Guided RL for Solving Long Horizon Robotics Tasks
PSL은 LLM 기반의 상위 수준 계획을 시각 기반 시퀀싱 및 강화학습(RL)과 결합하여, 미리 정의된 기술 라이브러리 없이 처음부터 긴 시나리오의 로봇 작업을 해결합니다. 25개 이상 작업에서 최대 10단계에 걸쳐 강력한 결과를 달성합니다.
Large Language Models (LLMs) have been shown to be capable of performing high-level planning for long-horizon robotics tasks, yet existing methods require access to a pre-defined skill library (e.g. picking, placing, pulling, pushing, navigating). However, LLM planning does not address how to design or learn those behaviors, which remains challenging particularly in long-horizon settings. Furthermore, for many tasks of interest, the robot needs to be able to adjust its behavior in a fine-grained manner, requiring the agent to be capable of modifying low-level control actions. Can we instead use the internet-scale knowledge from LLMs for high-level policies, guiding reinforcement learning (RL) policies to efficiently solve robotic control tasks online without requiring a pre-determined set of skills? In this paper, we propose Plan-Seq-Learn (PSL): a modular approach that uses motion planning to bridge the gap between abstract language and learned low-level control for solving long-horizon robotics tasks from scratch. We demonstrate that PSL achieves state-of-the-art results on over 25 challenging robotics tasks with up to 10 stages. PSL solves long-horizon tasks from raw visual input spanning four benchmarks at success rates of over 85%, out-performing language-based, classical, and end-to-end approaches. Video results and code at https://mihdalal.github.io/planseqlearn/
연구 동기 및 목표
- 고정된 기술 라이브러리 없이 LLM 계획을 활용하여 RL을 지도함으로써 긴 시점 로봇 작업 완성을 가능하게 한다.
- 추상적 언어 계획과 저수준 제어를 비전 기반 시퀀싱 모듈 및 모션 플래닝을 통해 연결한다.
- 스테이지 간 공유 정책 및 커리큘럼과 같은 단계 종료 기준으로 학습 속도와 안정성을 향상시킨다.
- 순수 시각 입력만을 사용하여 25개 이상 작업, 최대 10단계의 벤치마크에서 최첨단 성능을 입증한다.
제안 방법
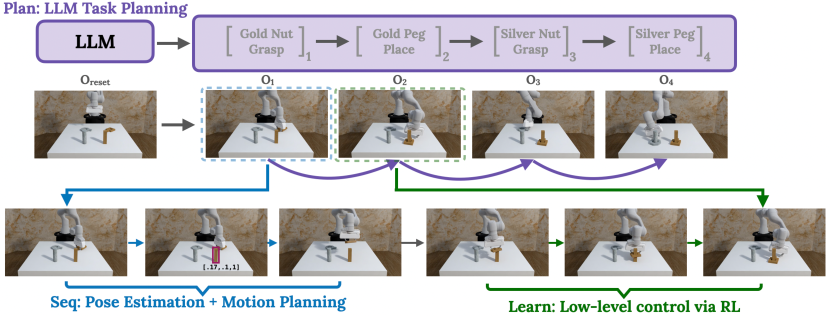
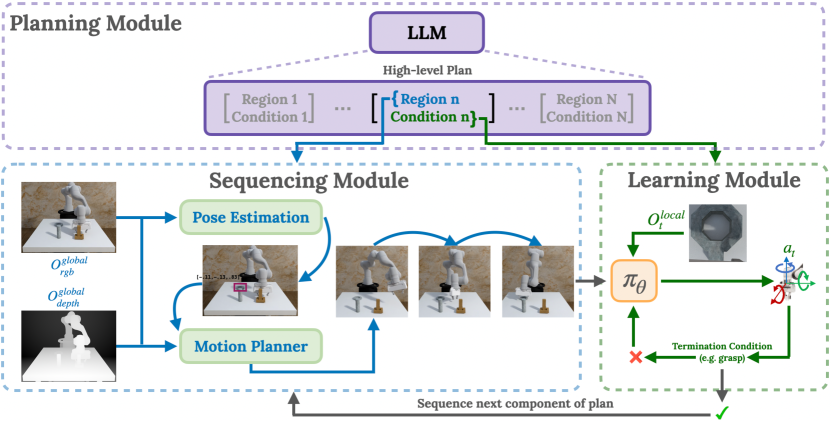
- LLM 계획(Plan)을 통해 언어 생성된 영역-단계 쌍으로 작업을 분해한다.
- RGB-D 관찰로부터 목표 영역을 추정하고 모션 플래닝으로 목표 자세를 계산하기 위해 비전 기반 시퀀싱 모듈을 사용한다(Seq).
- 모든 단계에 걸쳐 하나의 RL 정책을 학습시켜 지역 상호작용 전략을 학습한다(Learn).
- 계획 실행 중 흔들림을 방지하고 커리큘럼을 안내하기 위해 단계 종료 조건을 적용한다.
- DRQ-v2로 학습하고 로컬 관측치를 활용하여 데이터 효율성과 일반화를 향상한다.
- 장단계 전체에서 정책 및 가치 함수를 공유하여 긴 호라이즌 계획오류를 다룬다.
실험 결과
연구 질문
- RQ1사전에 정의된 기술 라이브러리 없이 긴 시점 로봇 작업에 대해 유용한 제로샷 고수준 계획을 LLM이 제공할 수 있는가?
- RQ2LLM 계획과 비전 기반 시퀀싱 및 단일 RL 정책의 결합이 긴 시점 작업에서 학습 효율성과 작업 성공률을 향상시키는가?
- RQ3로컬 관측치와 단계 종료 신호를 사용하는 것이 학습 속도와 자세 노이즈에 대한 로버스트니스에 어떤 영향을 미치는가?
- RQ4이 PSL 프레임워크가 최대 10단계의 다단계 작업으로 다양한 벤치마크에 확장될 수 있는가?
주요 결과
| 작업 | E2E | RAPS | TAMP | SayCan | PSL |
|---|---|---|---|---|---|
| RS-Bread | 0.52 ± 0.49 | 0.32 ± 0.44 | 0.90 ± 0.01 | 0.93 ± 0.09 | 1.0 ± 0.0 |
| RS-Can | 0.32 ± 0.44 | 0.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.0 ± 0.0 |
| RS-Milk | 0.02 ± 0.04 | 0.00 ± 0.00 | 0.85 ± 0.06 | 0.90 ± 0.05 | 1.0 ± 0.0 |
| RS-Cereal | 0.00 ± 0.00 | 0.00 ± 0.00 | 1.00 ± 0.00 | 0.63 ± 0.09 | 1.0 ± 0.0 |
| RS-NutRound | 0.06 ± 0.13 | 0.00 ± 0.00 | 0.40 ± 0.30 | 0.56 ± 0.25 | 0.98 ± 0.04 |
| RS-NutSquare | 0.02 ± 0.045 | 0.00 ± 0.00 | 0.35 ± 0.20 | 0.27 ± 0.21 | 0.97 ± 0.02 |
- PSL은 시각 입력만으로 최대 10단계까지의 네 벤치마크에서 85% 이상 성공을 달성한다.
- Robosuite의 2단계 작업에서 PSL은 기준선(E2E, RAPS, SayCan, TAMP)이 미치지 못하는 1.0의 성공에 도달하고 PSL은 평균 거의 1.0에 근접하며 타 플랫폼은 훨씬 낮다.
- 다단계 작업에서 PSL은 엔드 투 엔드 및 계층형 RL 기준선을 현저히 능가하여 다른 방법이 하락하는 곳에서도 높은 성공을 유지한다.
- 계획(모션 플래닝)과 상호작용(RL)을 분리함으로써 장애물 존재 및 접촉이 많은 작업을 효과적으로 다룬다.
- 단계 종료 신호와 단계 간 공유 정책이 학습 속도와 자세 추정 노이즈에 대한 로버스트성을 크게 향상시킨다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.