[논문 리뷰] Progressive Prompts: Continual Learning for Language Models
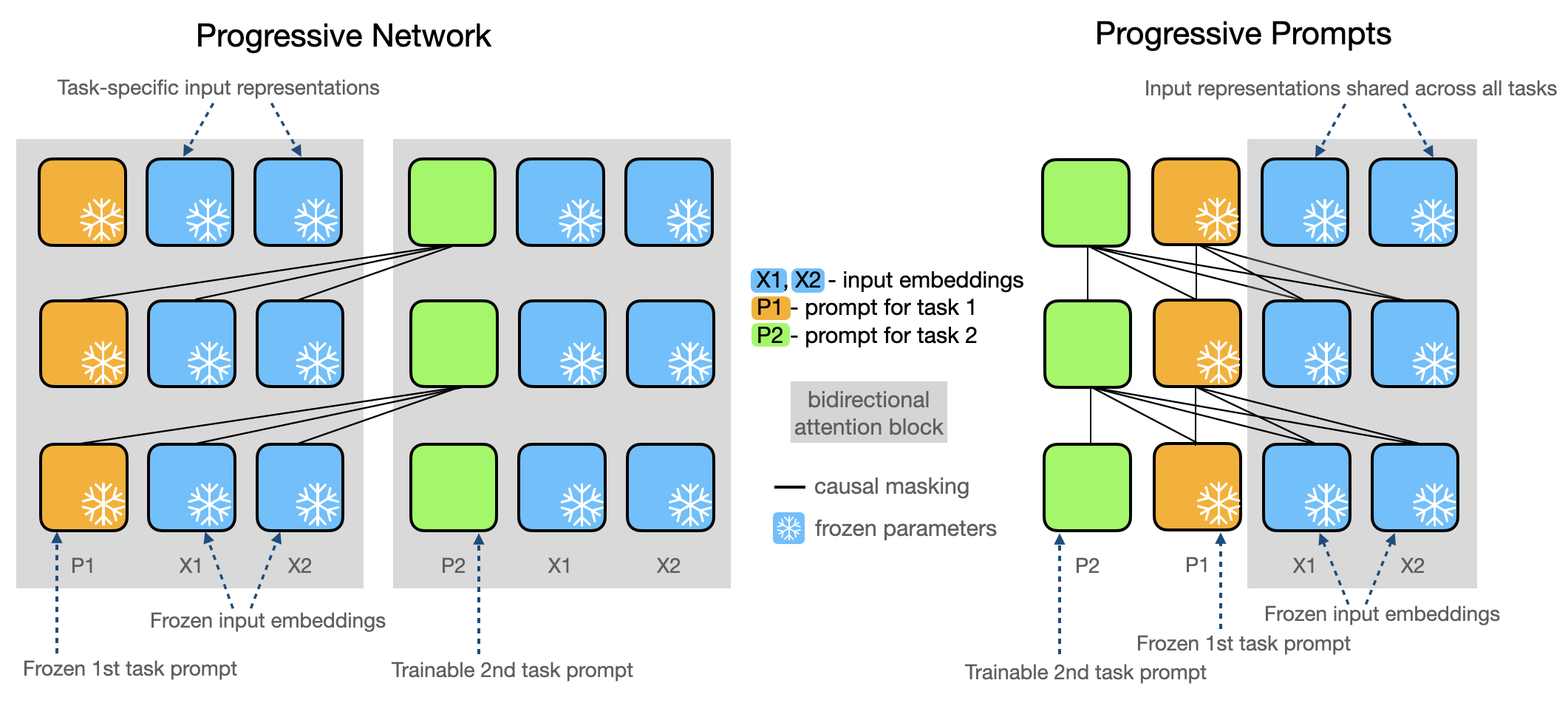
Progressive Prompts는 작업별로 새로운 소프트 프롬프트를 학습하고 이를 이전 프롬프트와 점진적으로 연결(concatenate)하는 방식으로 기본 모델을 고정된 상태로 유지하며 언어 모델의 메모리 효율적 연속 학습 방법을 도입하여 강한 순방향 전달과 잊힘 없음(no forgetting)을 달성합니다.
We introduce Progressive Prompts - a simple and efficient approach for continual learning in language models. Our method allows forward transfer and resists catastrophic forgetting, without relying on data replay or a large number of task-specific parameters. Progressive Prompts learns a new soft prompt for each task and sequentially concatenates it with the previously learned prompts, while keeping the base model frozen. Experiments on standard continual learning benchmarks show that our approach outperforms state-of-the-art methods, with an improvement >20% in average test accuracy over the previous best-preforming method on T5 model. We also explore a more challenging continual learning setup with longer sequences of tasks and show that Progressive Prompts significantly outperforms prior methods.
연구 동기 및 목표
- 언어 모델에서 연속 학습을 촉진하고 재해석적 잊힘(catas Trop hic forgetting)과 순방향 전달(forward transfer)을 다룹니다.
- 재생(replay)이나 대규모 매개변수 증가 없이 작업별 프롬프트를 사용하는 메모리 효율적 방법을 제안합니다.
- BERT와 T5의 표준 CL 벤치마크 및 더 긴 작업 시퀀스에서의 효과를 입증합니다.
- 훈련 안정화를 위한 프롬프트 임베딩 재매개변화 기법을 보여줍니다.
제안 방법
- 들어오는 각 작업 T_k에 대해 별도의 소프트 프롬프트 P_k를 학습합니다.
- 새 프롬프트를 이전에 학습된 모든 프롬프트와 순차적으로 연결(concatenate)하고, 기본 모델은 고정합니다.
- 작업 T_k에 대해 새로운 프롬프트 매개변수 θ_{P_k}만 학습합니다.
- 훈련의 안정화를 위해 프롬프트 임베딩 P_k → P_k' = MLP(P_k) + P_k로 재매개변화하는 잔차(MLP)를 사용합니다.
- 훈련 후 MLP를 제거하지만 향후 사용을 위해 투사된 P_k'를 남깁니다.
- 데이터 재생 없이 트랜스포머 모델(BERT 및 T5)에 이 접근법을 적용하고 평가합니다.
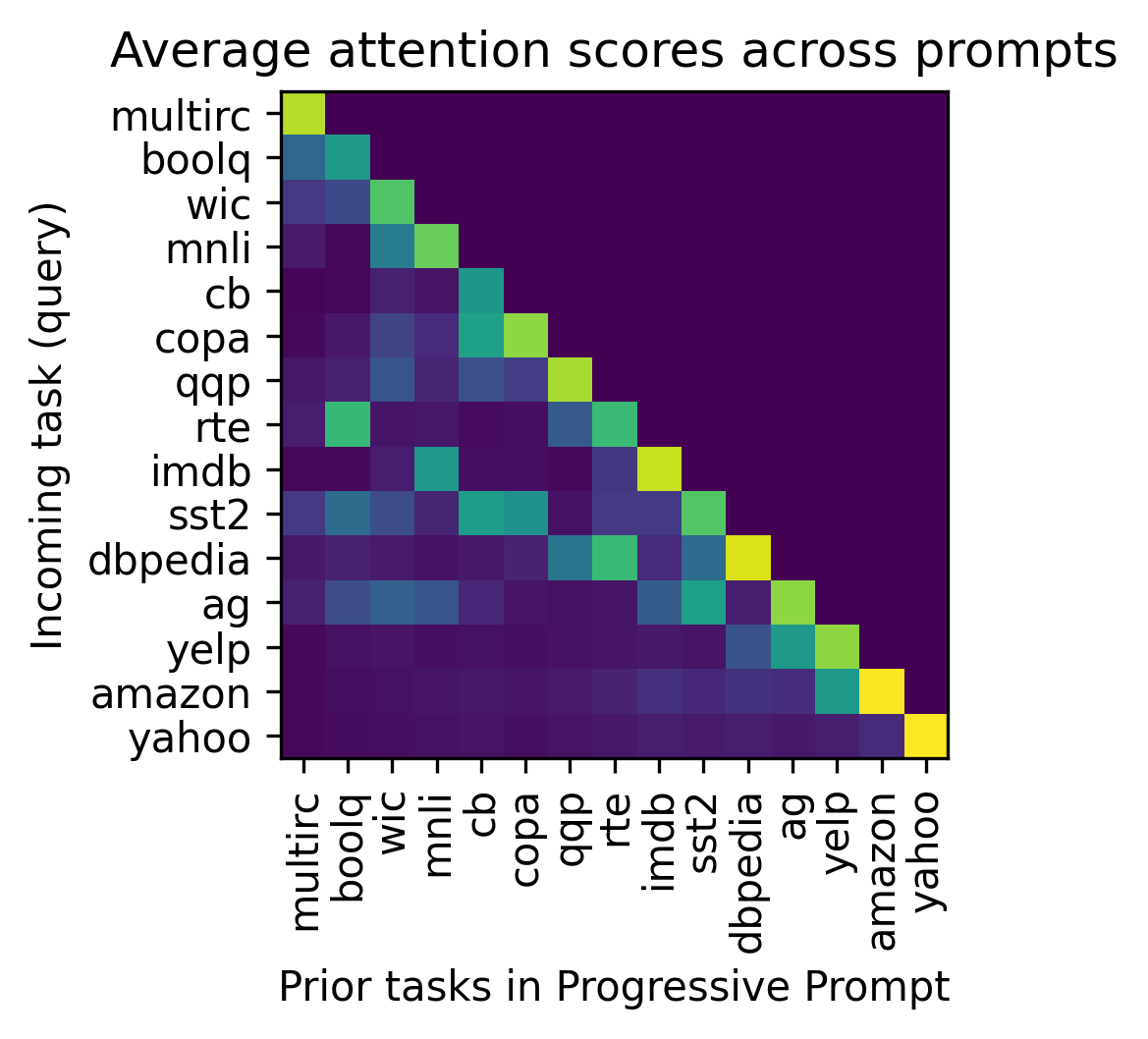
실험 결과
연구 질문
- RQ1Progressive Prompts가 연속된 작업 시퀀스에서 재해석적 잊힘(catas Trop hic forgetting)을 방지합니까?
- RQ2Progressive Prompts가 기본 모델의 재학습 없이 미래 작업의 학습을 개선하기 위한 순방향 전달을 달성할 수 있습니까?
- RQ3프롬프트 임베딩 재매개변화가 LMs의 연속 학습에서 안정성과 성능에 어떤 영향을 미칩니까?
주요 결과
- Progressive Prompts는 BERT와 T5 모두의 표준 텍스트 분류 벤치마크에서 SOTA 지속적 학습 방법보다 우수합니다.
- T5에서 Progressive Prompts는 페어-샷 설정에서 이전 최적 방법 대비 평균 정확도 증가가 20% 이상 달성합니다.
- 더 긴 작업 시퀀스(15작업)에서 Progressive Prompts는 BERT와 T5 모두에서 이전 접근법을 크게 능가합니다.
- 잔차 MLP를 이용한 임베딩 재매개변화는 파라미터 수를 장기적으로 증가시키지 않으면서 프롬프트 튜닝의 안정성과 성능을 향상시킵니다.
- 이 방법은 모델에 구애받지 않으며 데이터 재생이나 다수의 작업별 매개변수를 저장할 필요가 없습니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.