[논문 리뷰] Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models
Prometheus 2는 직접 평가와 쌍대 순위 평가를 모두 수행하는 오픈 소스 평가자 LMs를 제시하며, 다른 평가 형식으로 학습된 모델들의 가중치를 병합함으로써 이전의 열린 평가자들보다 인간과 독점형 LMs와의 합의도가 더 높아진다.
Proprietary LMs such as GPT-4 are often employed to assess the quality of responses from various LMs. However, concerns including transparency, controllability, and affordability strongly motivate the development of open-source LMs specialized in evaluations. On the other hand, existing open evaluator LMs exhibit critical shortcomings: 1) they issue scores that significantly diverge from those assigned by humans, and 2) they lack the flexibility to perform both direct assessment and pairwise ranking, the two most prevalent forms of assessment. Additionally, they do not possess the ability to evaluate based on custom evaluation criteria, focusing instead on general attributes like helpfulness and harmlessness. To address these issues, we introduce Prometheus 2, a more powerful evaluator LM than its predecessor that closely mirrors human and GPT-4 judgements. Moreover, it is capable of processing both direct assessment and pair-wise ranking formats grouped with a user-defined evaluation criteria. On four direct assessment benchmarks and four pairwise ranking benchmarks, Prometheus 2 scores the highest correlation and agreement with humans and proprietary LM judges among all tested open evaluator LMs. Our models, code, and data are all publicly available at https://github.com/prometheus-eval/prometheus-eval.
연구 동기 및 목표
- 독점형 모델에 의존하지 않고 LM 출력물을 평가하기 위한 개방적이고 투명한 평가자를 개발하도록 동기를 부여한다.
- 직접 평가와 쌍대 순위 평가라는 두 가지 일반적인 평가 형식을 모두 처리할 수 있는 통합 평가자 LM을 개발한다.
- 다른 형식으로 학습된 평가자들을 결합하기 위한 데이터 및 학습 레시피(가중치 병합)를 제안한다.
- 다양한 평가 기준을 갖춘 세밀한 쌍대 순위 데이터세트인 Preference Collection을 도입한다.
- 벤치마크 전반에서 인간 및 독점형 평가자(judges)와 높은 상관관계를 달성함을 입증한다.
제안 방법
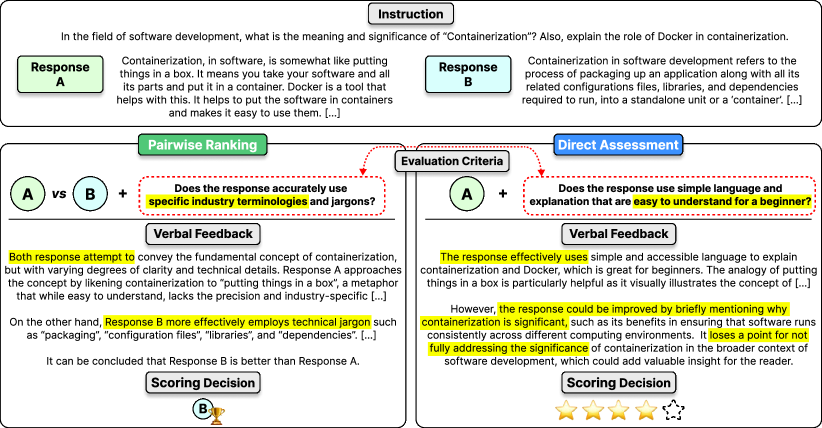
- 참조 답안, 구두 피드백, 평가 기준 등 명시적 입력 구성 요소를 포함한 직접 평가 및 쌍대 순위 평가 파이프라인을 공식화한다.
- 두 가지 데이터셋을 구성한다: Feedback Collection(직접 평가) 및 Preference Collection(1K 평가 기준이 포함된 쌍대 순위).
- 다른 형식으로 학습된 평가자를 융합하기 위한 가중치 병합(theta_final = alpha * theta_d + (1 - alpha) * theta_p)을 제안하고, 단일 형식 및 공동 학습 기준선과 비교한다.
- 대체 병합 전략(Task Arithmetic, TIES, DARE)을 탐색하고, 선형 병합이 Prometheus 2에 효과적임을 보이며, 최상의 형식 간 성능을 위해 alpha를 조정한다.
- Baseline 및 독점 LMs에 대해 네 가지 직접 평가 벤치마크와 네 가지 쌍대 순위 벤치마크에서 Prometheus 2를 평가한다.
실험 결과
연구 질문
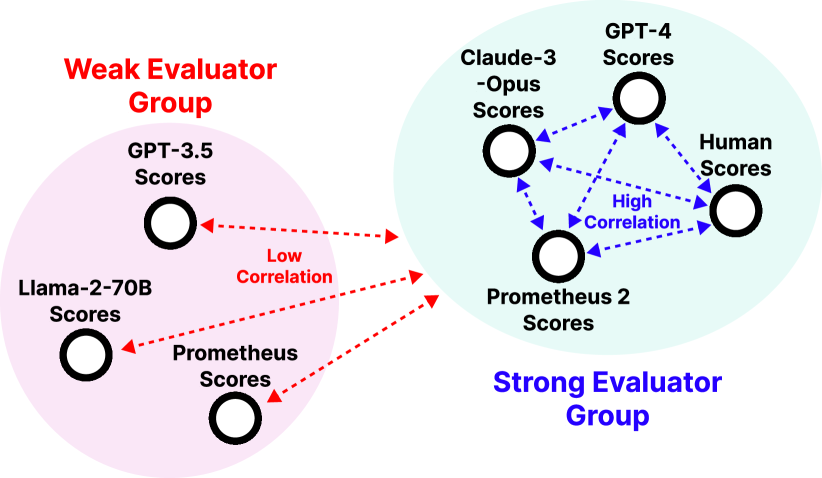
- RQ1오픈 소스 평가자 LM이 직접 평가와 쌍대 순위 평가 모두에서 인간 판단 및 독점형 LM 심판들과 높은 정렬도를 달성할 수 있는가?
- RQ2직접 평가와 쌍대 순위로 각각 학습된 평가자들의 가중치 병합이 단일 형식 또는 공동 학습된 평가자보다 더 나은가?
- RQ3다양하고 기준이 풍부한 데이터셋(Preference Collection)이 평가 신뢰도 향상에 어떤 역할을 하는가?
- RQ4Prometheus 2의 도메인 내외 평가 설정에서의 강건성은 어느 정도인가?
- RQ5한 평가 형식으로의 학습이 다른 형식으로 긍정적으로 이전되는가, 그 정도는 어느 정도인가?
주요 결과
- Prometheus 2 (7B & 8x7B)는 테스트된 오픈 평가자들 중 네 가지 직접 평가 벤치마크와 네 가지 쌍대 순위 벤치마크에서 인간 및 독점형 LMs와의 상관관계가 가장 높다.
- 가중치 병합은 다수의 벤치마크에서 단일 형식 및 공동 학습 평가자를 능가하여 형식 통합으로 긍정적 작업 전이가 있음을 시사한다.
- Preference Collection은 1K 기준으로 미세한 평가를 가능하게 하여 사용자 정의 표준에 따라 평가하는 모델의 능력을 향상시킨다.
- Prometheus 2-8x7B는 도메인 외 테스트에서 이전의 오픈 평가자에 비해 독점형 LMs와의 성능 차이를 대략 절반 정도로 줄인다.
- 직접 평가와 쌍대 순위 형식에서의 가중치를 병합해 사용하면 평가 형식 간의 일관성이 향상되어 견고함을 입증한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.