[논문 리뷰] PromptRobust: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts
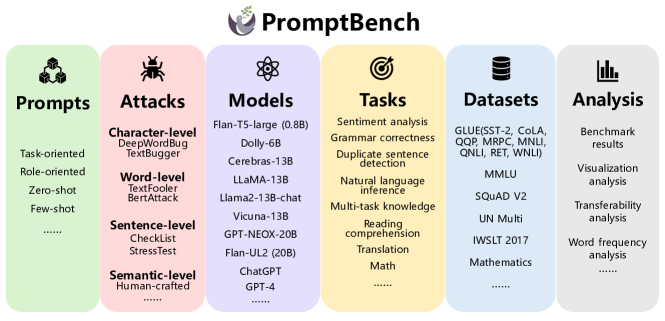
논문은 문자, 단어, 문장 및 의미 수준에서 작성된 공격적 프롬프트에 대한 LLM의 내성(resilience)을 평가하는 8개의 과제와 13개의 데이터세트에서 총 4,788개의 adversarial prompts를 포함하는 강건성 벤치마크 PromptBench를 제시합니다. 이는 모델 간 전이성, 프롬프트 유형 분석 및 강건한 프롬프트 설계를 위한 지침을 제공합니다.
The increasing reliance on Large Language Models (LLMs) across academia and industry necessitates a comprehensive understanding of their robustness to prompts. In response to this vital need, we introduce PromptRobust, a robustness benchmark designed to measure LLMs' resilience to adversarial prompts. This study uses a plethora of adversarial textual attacks targeting prompts across multiple levels: character, word, sentence, and semantic. The adversarial prompts, crafted to mimic plausible user errors like typos or synonyms, aim to evaluate how slight deviations can affect LLM outcomes while maintaining semantic integrity. These prompts are then employed in diverse tasks including sentiment analysis, natural language inference, reading comprehension, machine translation, and math problem-solving. Our study generates 4,788 adversarial prompts, meticulously evaluated over 8 tasks and 13 datasets. Our findings demonstrate that contemporary LLMs are not robust to adversarial prompts. Furthermore, we present a comprehensive analysis to understand the mystery behind prompt robustness and its transferability. We then offer insightful robustness analysis and pragmatic recommendations for prompt composition, beneficial to both researchers and everyday users.
연구 동기 및 목표
- 실제 사용 맥락에서 프롬프트 교란에 대한 LLM의 강건성 이해 필요성 촉구.
- 프롬프트, 공격, 모델, 과제, 데이터세트를 포괄하는 체계적 벤치마크(PromptBench)를 개발합니다.
- 단일화된 지표를 사용하여 강건성을 정량화하고 강건성과 전이성에 기여하는 요인을 분석합니다.
- 연구자와 실무자를 위해 더 강건한 프롬프트를 설계하기 위한 실용적 통찰과 권고를 제공합니다.
제안 방법
- 영샷(zero-shot), 소샷(few-shot), 역할지향(role-oriented), 그리고 과제지향(task-oriented) 프롬프트의 네 가지 유형을 정의합니다.
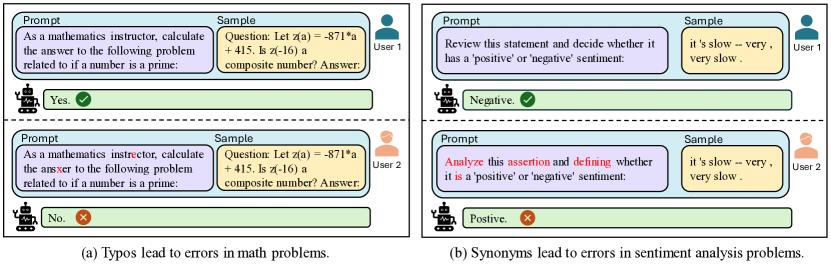
- 의미를 보존하면서 프롬 prompts를 교란하기 위해 문자, 단어, 문장, 의미 수준의 일곱 가지 프롬프트 공격을 개발합니다.
- 4,788개의 adversarial prompts를 사용하여 13개의 데이터세트에서 8개의 과제에 걸쳐 9개의 LLM을 평가합니다.
- 공격 하에서의 성능 손실을 정규화하기 위한 단일 지표로 Performance Drop Rate(PDR)을 도입합니다.
- 주의(attention) 분석, 모델 간 adversarial prompts의 전이성 및 단어 빈도 패턴을 분석하여 강건성 향상을 위한 지침을 제시합니다.
실험 결과
연구 질문
- RQ1다양한 과제와 데이터세트에 걸친 프롬프트의 교란에 대해 현재의 LLM은 얼마나 강건한가요?
- RQ2프롬프트 교란의 어느 수준(character, word, sentence, semantic)이 LLM의 성능에 가장 큰 저하를 초래하나요?
- RQ3적대적 프롬프트가 서로 다른 LLM 간에 전이되나요, 그리고 전이성에 영향을 주는 요인은 무엇인가요?
- RQ4다양한 애플리케이션에서 더 강건한 프롬프트를 구성하기 위해 도출할 수 있는 실용적인 지침은 무엇인가요?
주요 결과
- 단어 수준 공격이 가장 효과적이며, 모든 데이터세트에서 평균 33%의 성능 저하를 야기합니다.
- 문자 수준 공격은 평균 20%의 성능 저하를 야기하고, 의미 수준 공격은 문자 수준 공격에 비견될 만큼 강력합니다.
- 문장 수준 공격은 일반적으로 덜 위협적이며, 데이터세트에 따라 영향이 다르고 때때로 성능을 향상시킬 수 있습니다.
- GPT-4와 UL2가 전반적으로 가장 강건하며, 그 다음으로 T5-large, ChatGPT, Llama2가 뒤를 잇고, Vicuna가 가장 낮은 강건성을 보입니다.
- 한 모델용으로 생성된 적대적 프롬프트가 다른 모델로도 전이될 수 있어 교차 모델 취약성을 시사합니다.
- 의미 보존 평가에서 적대적 프롬프트는 인간에게도 현실적으로 남아 있으며(약 85% 수용 가능성).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.