[논문 리뷰] Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
이 논문은 픽셀 수준의 사전 과제 작업—특히 픽셀 간 전파 일관성—을 도입하여 공간적으로 민감한 밀도 높은 특징 표현을 학습하는 새로운 비지도 시각 표현 학습 방법인 PixPro를 제안한다. 동일한 픽셀의 표준 특징과 이를 부드럽게 전파한 버전의 특징 간 일관성을 유도함으로써 PixPro는 객체 검출 및 세분화와 같은 후행 밀도 예측 작업에서 최신 기술 수준의 전이 성능을 달성하며, 인스턴스 수준의 대비 학습 방법보다 Pascal VOC에서 2.6 AP 향상되고 COCO에서 0.8–1.0 mAP 향상된다.
Contrastive learning methods for unsupervised visual representation learning have reached remarkable levels of transfer performance. We argue that the power of contrastive learning has yet to be fully unleashed, as current methods are trained only on instance-level pretext tasks, leading to representations that may be sub-optimal for downstream tasks requiring dense pixel predictions. In this paper, we introduce pixel-level pretext tasks for learning dense feature representations. The first task directly applies contrastive learning at the pixel level. We additionally propose a pixel-to-propagation consistency task that produces better results, even surpassing the state-of-the-art approaches by a large margin. Specifically, it achieves 60.2 AP, 41.4 / 40.5 mAP and 77.2 mIoU when transferred to Pascal VOC object detection (C4), COCO object detection (FPN / C4) and Cityscapes semantic segmentation using a ResNet-50 backbone network, which are 2.6 AP, 0.8 / 1.0 mAP and 1.0 mIoU better than the previous best methods built on instance-level contrastive learning. Moreover, the pixel-level pretext tasks are found to be effective for pre-training not only regular backbone networks but also head networks used for dense downstream tasks, and are complementary to instance-level contrastive methods. These results demonstrate the strong potential of defining pretext tasks at the pixel level, and suggest a new path forward in unsupervised visual representation learning. Code is available at \url{https://github.com/zdaxie/PixPro}.
연구 동기 및 목표
- 현재 인스턴스 수준의 대비 학습 방법이 객체 검출 및 세분화와 같은 밀도 예측 작업에 최적화되지 않은 표현을 생성하는 한계를 해결한다.
- 이미지 수준의 방법보다 픽셀 수준에서 사전 과제 작업을 정의할 경우 더 공간적으로 민감한 표현을 얻을 수 있는지 탐색한다.
- 밀도 예측 작업에서 사용되는 백본 네트워크뿐 아니라 헤드 네트워크까지도 사전 학습하는 자기지도 학습 프레임워크를 개발한다.
- 픽셀 수준과 인스턴스 수준의 사전 과제 작업 간 상호보완성의 잠재력을 탐구하여 후행 전이 성능 향상에 기여한다.
- 특히 준지도 학습에서의 성능 향상 측면에서, 저데이터 환경에서 픽셀 수준 사전 학습의 효과를 입증한다.
제안 방법
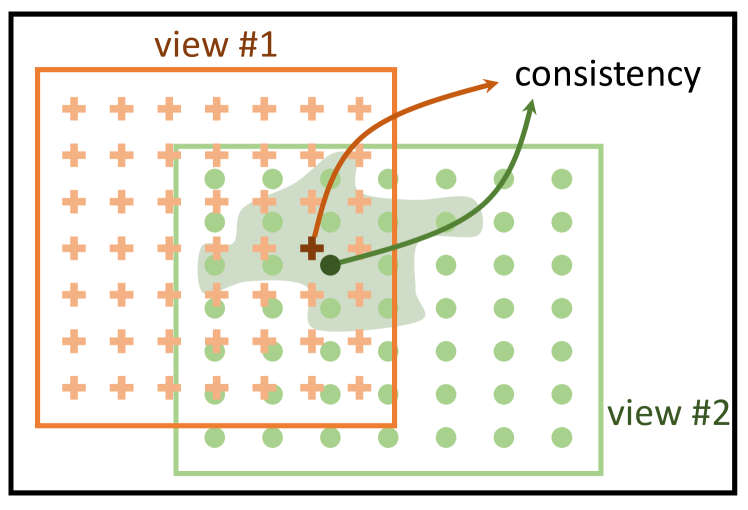
- 각 픽셀을 고유한 클래스로 간주하고, 동일한 픽셀의 특징을 두 개의 무작위 컷에서 형성된 양성 쌍을 기반으로 하는 픽셀 수준의 대비 학습 방법인 PixContrast를 제안한다.
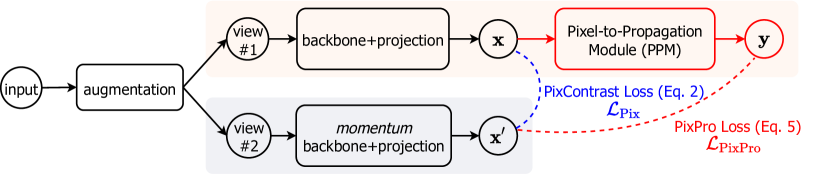
- 표준 백본과 픽셀 전파 모듈을 갖춘 두 개의 비대칭 스트림을 사용하는 픽셀-전파 일관성 방법인 PixPro를 도입한다. 전파 모듈은 유사한 픽셀을 기반으로 특징을 부드럽게 한다.
- 픽셀 간 유사도를 기반으로 특징 가중치를 계산하는 전파 모듈을 설계하여 유사한 픽셀을 필터링하고 특징을 부드럽게 하여 원본 특징과 일관된 양성 쌍을 생성한다.
- 표준 표현과 전파된 표현 간의 특징 일관성을 유도하는 대비 손실을 사용하여 음성 쌍을 명시적으로 모델링할 필요 없이 모델을 훈련시킨다.
- 제안된 픽셀 수준의 사전 과제 작업을 인스턴스 수준의 대비 학습(SimCLR*)과 결합하여 공간 민감성과 분류 능력의 상호보완적 강점을 활용한다.
- 백본 네트워크뿐 아니라 FPN 및 검출 헤드와 같은 헤드 네트워크까지도 동일한 픽셀 수준의 사전 과제 작업을 사용하여 사전 학습함으로써 후행 밀도 예측 작업의 초기화 품질을 향상시킨다.
실험 결과
연구 질문
- RQ1픽셀 수준에서 사전 과제 작업을 정의할 경우 객체 검출 및 세분화와 같은 밀도 예측 작업에 더 나은 표현을 제공할 수 있는가?
- RQ2직접적인 픽셀 수준의 대비 학습에 비해 픽셀-전파 일관성은 후행 성능 및 표현 품질 측면에서 어떻게 비교되는가?
- RQ3플랙스 수준의 사전 과제 작업이 일반적으로 인스턴스 수준의 대비 학습에서 사전 학습되지 않는 헤드 네트워크의 사전 학습에 얼마나 기여하는가?
- RQ4픽셀 수준과 인스턴스 수준의 사전 과제 작업을 결합할 경우 전이 성능 향상에 상호보완적인 효과가 있는가?
- RQ5제한된 레이블 데이터가 있는 준지도 학습 환경에서 픽셀 수준 사전 학습은 얼마나 효과적인가?
주요 결과
- PixPro는 Faster R-CNN R50-C4를 사용한 Pascal VOC 객체 검출에서 60.2 mAP를 달성하여 이전 최고 성능 방법보다 2.6 AP 향상되었다.
- COCO 객체 검출에서 PixPro는 FPN 기반으로 41.4 mAP, C4 기반으로 40.5 mAP를 기록하여 각각 이전 최고 기록보다 0.8 mAP 및 1.0 mAP 향상되었다.
- SimCLR*와 같은 인스턴스 수준의 대비 학습과 결합할 경우, Pascal VOC에서 58.7 mAP, COCO에서 40.9 mAP를 달성하여 상호보완적 성과를 입증하였다.
- FPN 및 검출 헤드를 포함한 헤드 네트워크의 사전 학습은 COCO 객체 검출에서 FCOS에 대해 1.2 mAP 향상으로 이어졌으며, 종단 간 사전 학습의 이점을 보여주었다.
- COCO에서 1%의 레이블 데이터로 준지도 객체 검출을 수행한 결과, PixPro를 사용할 경우 14.8 mAP를 달성하여 이전 비지도 방법보다 +3.9 mAP 향상되었다.
- COCO에서 픽셀 수준 과제 작업을 추가로 사용한 사전 학습은 1% 데이터 기준 +0.7 mAP, 10% 데이터 기준 +0.2 mAP 향상으로 이어졌으며, 저데이터 환경에서의 강력한 이점을 보여주었다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.