[논문 리뷰] ProxylessNAS: Direct Neural Architecture Search on Target Task and\n Hardware
ProxylessNAS는 대상 작업과 하드웨어에서 직접 신경망 아키텍처를 학습하여 메모리 및 컴퓨트 소모를 줄이고, 프록시 작업 없이도 큰 탐색 공간과 하드웨어 인식 특화를 가능하게 한다.
Neural architecture search (NAS) has a great impact by automatically\ndesigning effective neural network architectures. However, the prohibitive\ncomputational demand of conventional NAS algorithms (e.g. $10^4$ GPU hours)\nmakes it difficult to \\emph{directly} search the architectures on large-scale\ntasks (e.g. ImageNet). Differentiable NAS can reduce the cost of GPU hours via\na continuous representation of network architecture but suffers from the high\nGPU memory consumption issue (grow linearly w.r.t. candidate set size). As a\nresult, they need to utilize~\\emph{proxy} tasks, such as training on a smaller\ndataset, or learning with only a few blocks, or training just for a few epochs.\nThese architectures optimized on proxy tasks are not guaranteed to be optimal\non the target task. In this paper, we present \\emph{ProxylessNAS} that can\n\\emph{directly} learn the architectures for large-scale target tasks and target\nhardware platforms. We address the high memory consumption issue of\ndifferentiable NAS and reduce the computational cost (GPU hours and GPU memory)\nto the same level of regular training while still allowing a large candidate\nset. Experiments on CIFAR-10 and ImageNet demonstrate the effectiveness of\ndirectness and specialization. On CIFAR-10, our model achieves 2.08\\% test\nerror with only 5.7M parameters, better than the previous state-of-the-art\narchitecture AmoebaNet-B, while using 6$\\times$ fewer parameters. On ImageNet,\nour model achieves 3.1\\% better top-1 accuracy than MobileNetV2, while being\n1.2$\\times$ faster with measured GPU latency. We also apply ProxylessNAS to\nspecialize neural architectures for hardware with direct hardware metrics (e.g.\nlatency) and provide insights for efficient CNN architecture design.\n
연구 동기 및 목표
- 대규모 데이터셋(ImageNet 등)에서 프록시 작업 없이 직접 NAS를 통해 최적화하는 것을 목표로 한다.
- 블록을 반복하지 않는 큰 탐색 공간을 가능하게 하고, 메모리/컴퓨트를 일반 학습 수준으로 줄인다.
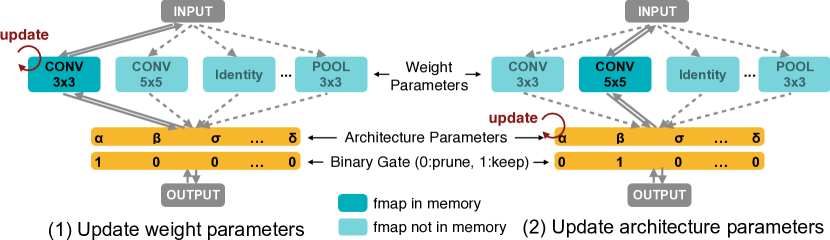
- 메모리 사용량을 낮추기 위해 이진화된 아키텍처 매개변수를 통한 경로 수준 프루닝을 도입한다.
- 미분 불가능한 하드웨어 메트릭(예: 대기 시간)을 미분 가능 모델링 또는 REINFORCE 기반 방법으로 처리한다.
- GPU, CPU, 모바일 등 서로 다른 하드웨어에 대한 대기 시간 인식 목표로 아키텍처 특수화를 시연한다.
제안 방법
- 모든 후보 경로를 혼합 연산으로 포함하는 과다 매개변수화된 네트워크를 구성한다.
- 런타임에 하나의 경로만 활성화되도록 아키텍처 매개변수를 이진화하여 메모리를 표준 학습 수준으로 감소시킨다.
- 매개변수 아키텍처를 고정하고 가중치 매개변수를 학습시키며, 메모리를 작게 유지하기 위해 두 경로 샘플링을 통해 그래디언트 기반 추정(BinaryConnect 영감)으로 아키텍처 매개변수를 업데이트한다.
- 경로별 대기 시간을 예측하여 미분 가능 정규화 항으로 모형화하고, 대기 시간 가중치 λ2와 함께 손실에 기대값을 더한다.
- 미분 불가능한 대기 시간 목표를 사용할 때 아키텍처 매개변수를 위한 대체 REINFORCE 기반 업데이트를 제공한다.
- CIFAR-10과 ImageNet에서 평가하고, 모바일, GPU, CPU에 대한 하드웨어 인식 탐색을 포함한다.

실험 결과
연구 질문
- RQ1NAS가 프록시 작업 없이도 대규모 작업(예: ImageNet)에서 직접 아키텍처를 최적화할 수 있는가?
- RQ2모든 블록을 학습 가능하게 허용하는 것이(반복 모티프 제약 없음) 성능과 효율성을 향상시키는가?
- RQ3큰 경로 기반 탐색 공간을 탐색하면서도 메모리와 계산량을 일반 학습 수준으로 유지할 수 있는가?
- RQ4레이턴시를 미분 가능 목표로 얼마나 효과적으로 통합하여 하드웨어 인식 아키텍처를 생성할 수 있는가?
- RQ5GPU, CPU, 모바일 간에 하드웨어 전문화된 아키텍처가 차이를 보이며 NAS가 이를 포착할 수 있는가?
주요 결과
| 모델 | 매개변수 | 테스트 에러 (%) |
|---|---|---|
| Proxyless-G (ours) + c/o | 5.7M | 2.08 |
| Proxyless-R (ours) + c/o | 5.7M | 2.30 |
- CIFAR-10에서 ProxylessNAS은 5.7M 파라미터로 2.08% 테스트 에러를 달성 (약 6배 더 많은 파라미터를 가진 AmoebaNet-B를 능가).
- ImageNet에서 Proxyless-G는 top-1 75.1%를 달성하고 MobileNetV2보다 1.2× 빠른 대기 시간, 이전 방법들보다 200× 낮은 탐색 비용.
- Proxyless-G (mobile)은 74.6%의 top-1과 78 ms 모바일 대기 시간을 달성하여 유사한 대기 시간 제약하에서 MobileNetV2를 능가.
- Proxyless-NAS는 GPU, CPU, 모바일에 대한 하드웨어 전문 아키텍처를 찾아 플랫폼별로 뚜렷한 아키텍처 선호도를 보임(예: GPU: 얕고 넓음; CPU: 더 깊고 좁음).
- 레이턴시 인식 탐색(레이턴시 정규화 포함)은 레이턴시-무시 접근법보다 더 나은 정확도-대기 시간 트레이드오프를 제공한다.
- 경로 이진화를 통한 메모리 감소와 블록 반복 없이 큰 아키텍처 탐색 공간을 가능하게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.