[논문 리뷰] Pruning vs Quantization: Which is Better?
본 논문은 신경망 압축을 위해 가지치기(pruning)와 양자화(quantization)를 광범위하게 비교하고, 대부분의 경우 양자화가 가지치기보다 일반적으로 우수하다는 점을 밝혀내며, 특히 중간 정도의 압축에서 그렇다; 가지치기는 매우 높은 압축 비율에서만 도움이 될 수 있다.
Neural network pruning and quantization techniques are almost as old as neural networks themselves. However, to date only ad-hoc comparisons between the two have been published. In this paper, we set out to answer the question on which is better: neural network quantization or pruning? By answering this question, we hope to inform design decisions made on neural network hardware going forward. We provide an extensive comparison between the two techniques for compressing deep neural networks. First, we give an analytical comparison of expected quantization and pruning error for general data distributions. Then, we provide lower bounds for the per-layer pruning and quantization error in trained networks, and compare these to empirical error after optimization. Finally, we provide an extensive experimental comparison for training 8 large-scale models on 3 tasks. Our results show that in most cases quantization outperforms pruning. Only in some scenarios with very high compression ratio, pruning might be beneficial from an accuracy standpoint.
연구 동기 및 목표
- 모델 압축에 대해 하드웨어 편향 없이 가지치기와 양자화를 공정하게 비교하는 동기를 부여한다.
- 동일한 압축 비율 하에서 가지치기와 양자화의 오차를 분석적으로 및 경험적으로 벤치마크한다.
- 이론적 한계와 실제 네트워크에 대한 실험을 포함하여 층별 및 전체 모델 평가를 제공한다.
제안 방법
- 대칭 균일 양자화로 양자화 시 가중치 오차 및 그에 따른 MSE/ SNR 동작을 모델링한다.
- 마그니튜드 가지치기를 가지치기 방법으로 정의하고 이를 양자화의 클리핑과의 오차 유사성으로 도출한다.
- PTQ 층 출력 오차의 하한을 계산하는 혼합정수 이차계획법을 도출한다.
- 희소성 마스크를 이용한 가지치기에 대한 정확한 해를 비교적 차원에서 가지치기 솔루션으로 제공한다.
- 여러 아키텍처에 대해 분포, 단일 층 PTQ, 전체 모델 미세조정을 포함한 광범위한 실험을 수행한다.
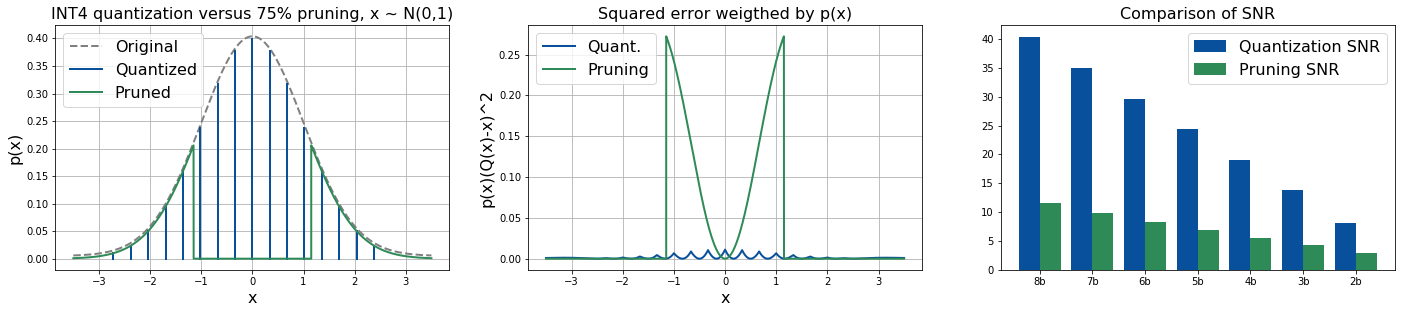
실험 결과
연구 질문
- RQ1동일한 압축 비율에서 어떤 기술—가지치기 또는 양자화—가 출력 정확도와 오차를 더 높게/낮게 하는가?
- RQ2데이터 분포(Gaussian 대 꼬리가 두꺼운 분포)가 가지치기와 양자화의 상대적 성능에 어떤 영향을 미치는가?
- RQ3층별 양자화 및 가지치기 오차에 대한 엄밀한 이론적 한계는 무엇이며 이를 실험 결과와 어떻게 비교되는가?
- RQ4가지치기 또는 양자화 후 미세조정이 학습된 표현을 역전시키는가, 아니면 보존하는가, 그리고 이것이 성능에 어떻게 영향을 미치는가?
- RQ5저장소 및 계산 측면에서 가지치기와 양자화의 실제 하드웨어 영향은 무엇인가?
주요 결과
| 모델 | 원본 | 양자화 8비트 | 양자화 7비트 | 양자화 6비트 | 양자화 5비트 | 양자화 4비트 | 양자화 3비트 | 양자화 2비트 | 가지치기 8비트 | 가지치기 7비트 | 가지치기 6비트 | 가지치기 5비트 | 가지치기 4비트 | 가지치기 3비트 | 가지치기 2비트 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Resnet-18 | 69.7 | 70.5 | 70.5 | 70.6 | 70.3 | 70.0 | 68.9 | 67.3 | 70.3 | 70.1 | 69.9 | 69.5 | 69.3 | 68.3 | 66.8 |
| Resnet-50 | 76.1 | 76.4 | 76.4 | 76.4 | 76.3 | 76.2 | 75.5 | 72.3 | 76.6 | 76.4 | 76.2 | 76.1 | 75.9 | 75.4 | 74.3 |
| MobileNet-V2 | 71.7 | 71.9 | 72.0 | 71.7 | 71.6 | 70.9 | 68.6 | 59.1 | 68.1 | 65.6 | 61.9 | 56.3 | 48.0 | 34.0 | 21.2 |
| EfficientNet | 75.4 | 75.2 | 75.3 | 75.0 | 74.6 | 74.0 | 71.5 | 60.9 | 72.5 | 70.9 | 68.1 | 63.6 | 56.4 | 44.5 | 27.1 |
| MobileNet-V3 | 67.4 | 67.7 | 67.6 | 67.1 | 66.3 | 64.7 | 60.8 | 50.5 | 65.6 | 64.4 | 62.4 | 60.2 | 56.1 | 31.7 | 0.0 |
| ViT | 81.3 | 81.5 | 81.4 | 81.4 | 81.0 | 80.4 | 78.4 | 72.2 | 76.6 | 76.6 | 76.2 | 73.1 | 72.4 | 71.5 | 69.4 |
| DeepLab-V3 | 72.9 | 72.3 | 72.3 | 72.4 | 71.9 | 70.8 | 63.2 | 17.6 | 65.2 | 62.8 | 56.8 | 47.7 | 32.9 | 18.6 | 10.0 |
| EfficientDet | 40.2 | 39.6 | 39.6 | 39.6 | 39.2 | 37.8 | 33.5 | 15.5 | 34.5 | 33.0 | 30.9 | 27.9 | 24.2 | 17.9 | 8.0 |
- 중간 수준의 압축에서 가중치 분포와 실제 모델 텐서에 대해 양자화가 일반적으로 가지치기보다 더 높은 SNR을 생성한다.
- 매우 높은 압축(대략 값당 2–3비트) 및 극단적 희소성에서만 가지치기가 양자화에 비해 우세해진다.
- 46개 모델의 실제 모델 텐서 전반에서 가중치 분포의 첨도(kurtosis)가 가지치기가 양자화보다 우수할 수 있는 시점을 나타내며, 일반적으로 첨도가 높을수록 양자화가 더 우세한 경향이 있지만 극단적 압축에서는 예외가 있다.
- 경쟁력 있는 QAT 및 가지치기 방법을 사용한 전체 모델 미세조정에서 양자화 인식 학습(QAT)은 동일한 압축 비율에서 대개 가지치기보다 정확도를 보존하거나 향상시킨다.
- 비구조적 가지치기는 가지치기 성능의 상한을 제공하며, 하드웨어 고려사항은 실제 이익을 감소시키는 경향이 있어 양자화를 지지하는 근거를 강화한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.