[논문 리뷰] QLoRA: Efficient Finetuning of Quantized LLMs
QLoRA는 Low Rank Adapters를 사용하여 양자화된 4비트 LMs를 미세조정하고 16비트 성능과 일치시키되 훨씬 적은 메모리를 사용하여 대형 모델을 단일 GPU에서 학습 가능하게 한다.
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.
연구 동기 및 목표
- 매우 큰 언어 모델(LLMs)의 메모리 효율적인 미세조정을 촉진한다.
- 성능을 유지하기 위해 4비트 NF4 양자화와 Low Rank Adapters를 결합하는 것을 제안한다.
- 7B–65B 모델 및 다수의 명령 따르기 벤치마크에서 확장성을 보여준다.
- 데이터 품질과 데이터셋 크기의 차이를 분석하고 인간 및 GPT-4 평가를 사용하여 챗봇 성능을 평가한다.
제안 방법
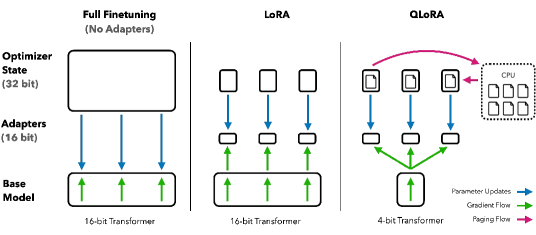
- 메모리 사용량을 줄이기 위해 사전 학습된 가중치를 4비트 NF4로 Double Quantization과 함께 양자화한다.
- 양자화된 가중치를 통해 그래디언트를 역전파하여 모든 트랜스포머 층에 삽입된 LoRA 어댑터를 학습한다.
- 학습 중 메모리 급증을 처리하기 위해 Paged Optimizers와 NVIDIA 통합 메모리를 사용한다.
- LoRA 매개변수만 업데이트하는 동안 순전파/역전파를 위해 BF16으로 디퀀타이즈를 해제하는 계산 경로를 유지한다.
- 여러 모델 크기와 데이터세트에서 전체 16비트 미세조정 및 16비트 LoRA 기준선과 비교 평가한다.
실험 결과
연구 질문
- RQ1LoRA 어댑터와 함께 사용할 때 4비트 NF4 양자화와 Double Quantization이 전체 16비트 미세조정 성능을 유지할 수 있는가?
- RQ27B–65B 모델 크기 및 명령 데이터셋에서 정확도와 메모리 효율성 측면에서 QLoRA의 확장성은 어떤가?
- RQ3데이터 품질과 데이터셋 선택이 지침 튜닝과 챗봇 능력에 있어서 데이터셋 크기보다 더 큰 영향을 미치는가?
- RQ4Vicuna/OASST1 벤치마크에서 QLoRA로 학습된 챗봇의 순위를 매길 때 GPT-4와 인간 평가 간의 비교는 어떠한가?
주요 결과
| 모델 / 데이터셋 | 매개변수 수 | 모델 비트 | 메모리 | ChatGPT 대 시스템 | 시스템 대 ChatGPT | 평균 | 95% 신뢰구간 |
|---|---|---|---|---|---|---|---|
| GPT-4 | - | - | - | 119.4% | 110.1% | 114.5% | 2.6% |
| Bard | - | - | - | 93.2% | 96.4% | 94.8% | 4.1% |
| Guanaco 65B | 65B | 4-bit | 41 GB | 96.7% | 101.9% | 99.3% | 4.4% |
| Alpaca 65B | 65B | 4-bit | 41 GB | 63.0% | 77.9% | 70.7% | 4.3% |
| FLAN v2 65B | 65B | 4-bit | 41 GB | 37.0% | 59.6% | 48.4% | 4.6% |
| Guanaco 33B | 33B | 4-bit | 21 GB | 96.5% | 99.2% | 97.8% | 4.4% |
| Open Assistant 33B | 33B | 16-bit | 66 GB | 91.2% | 98.7% | 94.9% | 4.5% |
| Vicuna 13B | 13B | 16-bit | 26 GB | 91.2% | 98.7% | 94.9% | 4.5% |
| Guanaco 13B | 13B | 4-bit | 10 GB | 87.3% | 93.4% | 90.4% | 5.2% |
| Alpaca 13B | 13B | 4-bit | 10 GB | 63.8% | 76.7% | 69.4% | 4.2% |
| HH-RLHF 13B | 13B | 4-bit | 10 GB | 55.5% | 69.1% | 62.5% | 4.7% |
| Unnatural Instr. 13B | 13B | 4-bit | 10 GB | 50.6% | 69.8% | 60.5% | 4.2% |
| Chip2 13B | 13B | 4-bit | 10 GB | 49.2% | 69.3% | 59.5% | 4.7% |
| Longform 13B | 13B | 4-bit | 10 GB | 44.9% | 62.0% | 53.6% | 5.2% |
| Self-Instruct 13B | 13B | 4-bit | 10 GB | 38.0% | 60.5% | 49.1% | 4.6% |
| FLAN v2 13B | 13B | 4-bit | 10 GB | 32.4% | 61.2% | 47.0% | 3.6% |
- NF4 + Double Quantization을 사용한 QLoRA는 학술 벤치마크에서 16비트 전체 미세조정 및 16비트 LoRA 성능과 일치한다.
- NF4는 제로샷 및 미세조정 작업에서 FP4 및 Int4보다 우수하며, Double Quantization은 성능 저하 없이 메모리를 줄인다.
- Guanaco 모델(7B–65B)은 Vicuna 벤치마크에서 가까운 ChatGPT 성능을 달성하고, Guanaco 65B는 GPT-4 평가 Vicuna 결과에서 ChatGPT의 99.3%에 도달한다.
- 4비트 QLoRA는 65B 모델을 단일 48GB GPU에서, 33B를 21GB에서 미세조정 가능하게 하며, 전체 16비트 미세조정 대비 상당한 메모리 절약을 제공한다.
- 데이터세트의 품질은 명령 수행 및 챗봇 성능에 있어 크기보다 더 중요하며, 강한 MMLU 성능이 항상 더 우수한 챗봇 성능을 의미하진 않는다.
- GPT-4 기반 평가가 대회 형식의 챗봇 비교에서 인간 판단과 크게 일치하는 경향이 있지만, 해석에 주의가 필요한 중요한 불일치가 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.