[논문 리뷰] Query-Dependent Video Representation for Moment Retrieval and Highlight Detection
이 논문은 텍스트 쿼리 컨텍스트를 영상 표현에 주입하는 쿼리 의존형 DETR인 QD-DETR을 제시하며, 음수 쌍 학습과 입력 적응형 주목도 예측기를 통해 순간 검색 및 하이라이트 탐지에서 최첨단 성능을 달성한다.
Recently, video moment retrieval and highlight detection (MR/HD) are being spotlighted as the demand for video understanding is drastically increased. The key objective of MR/HD is to localize the moment and estimate clip-wise accordance level, i.e., saliency score, to the given text query. Although the recent transformer-based models brought some advances, we found that these methods do not fully exploit the information of a given query. For example, the relevance between text query and video contents is sometimes neglected when predicting the moment and its saliency. To tackle this issue, we introduce Query-Dependent DETR (QD-DETR), a detection transformer tailored for MR/HD. As we observe the insignificant role of a given query in transformer architectures, our encoding module starts with cross-attention layers to explicitly inject the context of text query into video representation. Then, to enhance the model's capability of exploiting the query information, we manipulate the video-query pairs to produce irrelevant pairs. Such negative (irrelevant) video-query pairs are trained to yield low saliency scores, which in turn, encourages the model to estimate precise accordance between query-video pairs. Lastly, we present an input-adaptive saliency predictor which adaptively defines the criterion of saliency scores for the given video-query pairs. Our extensive studies verify the importance of building the query-dependent representation for MR/HD. Specifically, QD-DETR outperforms state-of-the-art methods on QVHighlights, TVSum, and Charades-STA datasets. Codes are available at github.com/wjun0830/QD-DETR.
연구 동기 및 목표
- MR/HD 작업에서 진정한 쿼리 기반 영상 표현의 필요성 제시
- 텍스트 쿼리를 영상 인코딩에 크게 통합하는 검출-트랜스포머 기반 모델 개발
- 음성 영상-쿼리 쌍을 구성하고 활용하여 구별 가능 학습 촉진
- 쿼리-영상 쌍마다 saliency 기준을 조정하는 입력 적응형 주목도 예측기 도입
제안 방법
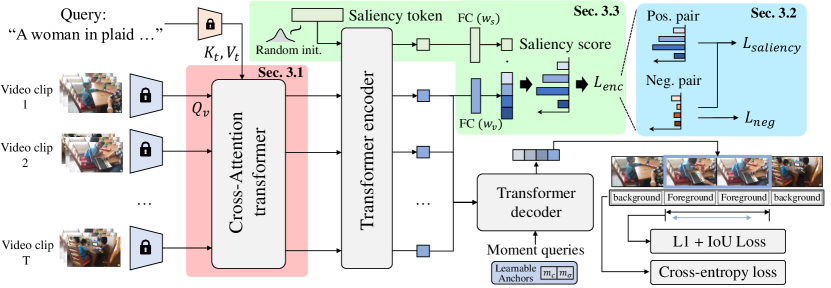
- 인코더 입력에 교차 주의를 삽입하여 영상 클립과 텍스트 쿼리 특징을 융합
- 비관련 쿼리-영상 쌍을 억제하기 위해 음수 쌍으로 학습
- clip 주목도를 계산하기 위한 입력 적응형 예측기로 주목도 토큰 사용
- 타임 로컬라이제이션을 위한 동적 앵커 모먼트를 쿼리로 하는 DETR 유사 디코더 구현
- L1 및 일반화 IoU 손실로 MR 최적화, 마진 랭킹 및 랭크 어웨어 대조손실로 HD 최적화
- MR/HD를 함께 및 각각 벤치마크에서 평가

실험 결과
연구 질문
- RQ1쿼리 의존형 영상 표현이 쿼리 비의존적 baselines에 비해 순간 검색 및 하이라이트 탐지 성능을 개선하는가?
- RQ2음수 쌍 학습이 주목도 추정 및 모먼트 로컬라이제이션에 미치는 영향은 무엇인가?
- RQ3입력 적응형 주목도 예측기가 다양한 쿼리에서 주목도 회귀에 어떤 영향을 미치는가?
- RQ4제안된 구성요소들이 표준 MR/HD 데이터셋에서 최첨단 성능을 내는가?
주요 결과
- QD-DETR은 비디오 단독 입력 및 비디오+오디오 입력 모두에서 QVHighlights에서 최첨단 방법을 능가한다.
- QVHighlights에서 V를 사용한 경우 MR mAP가 62.40으로 다양한 지표에서, HIT@1의 mAP도 62.40으로 달성; V+A를 사용하면 MR mR이 63.06, HIT@1 변형은 62.87에 도달한다.
- TVSum 및 Charades-STA에서 QD-DETR는 기준선 대비 강력한 개선을 보이며 다수의 피처 백본에서 RS 지표를 상향 해결
- 어레이먼트 연구에서 교차-주목 인코딩, 음수 쌍 학습, 적응형 주목도 예측기가 MR/HD 성능에 실질적으로 기여하며, 더 깊은 자기 주의만으로는 기여도가 낮은 경우보다 큰 기여를 보임
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.