[논문 리뷰] Qwen2 Technical Report
Qwen2는 0.5B에서 72B dense 모델과 57B MoE를 포함한 오픈-웨이트(Open-weight) LLM 계열을 도입하며, 긴 컨텍스트 능력, 다국어 지원, 명령-미세조정을 갖춰, 언어, 코딩, 수학, 추론 벤치마크에서 독점 모델 및 공개 벤치라인에 비해 경쟁력 있는 성능을 달성한다.
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
연구 동기 및 목표
- 넓은 규모 범위(0.5B–72B dense, 57B MoE)를 갖춘 오픈-웨이트 LLM의 발전.
- 아키텍처 및 데이터 개선을 통해 긴 컨텍스트 처리와 다국어 능력을 향상.
- 확장 가능한 데이터 전략을 사용한 감독 미세조정과 RLHF를 통해 인간 선호에 모델을 정렬.
- 언어, 코딩, 수학, 추론 벤치마크에서 독점 모델 대비 경쟁력 있는 성능을 입증.
- 커뮤니티 연구와 배치를 촉진하기 위해 가중치와 도구에 대한 오픈 액세스를 제공.
제안 방법
- 긴 컨텍스트를 위해 Grouped Query Attention (GQA) 및 Dual Chunk Attention (DCA)을 사용하는 Transformer 기반 dense 및 mixture-of-experts 아키텍처를 활용.
- 안정성을 위해 Rotary Position Embeddings (RoPE)와 RMSNorm 및 pre-normalization을 갖춘 SwiGLU 활성화 사용.
- dense 모델은 >7 trillion tokens의 대형 다국어 코퍼스에서 학습; MoE는 추가 업사이클링 데이터 수신.
- 문맥 길이를 32,768 토큰으로 확장하고 YARN 및 Dual Chunk Attention를 통해 최대 131,072 토큰의 시퀀스를 가능하게 한다.
- RLHF를 위한 감독 미세조정과 Direct Preference Optimization (DPO)를 통한 후-학습, 정렬 비용 감소를 위한 Online Merging Optimizer를 추가.
- 고품질 시연 및 선호 데이터 세트를 구축하기 위해 협력적 데이터 주석 작성 및 자동화된 데이터 합성을 활용.
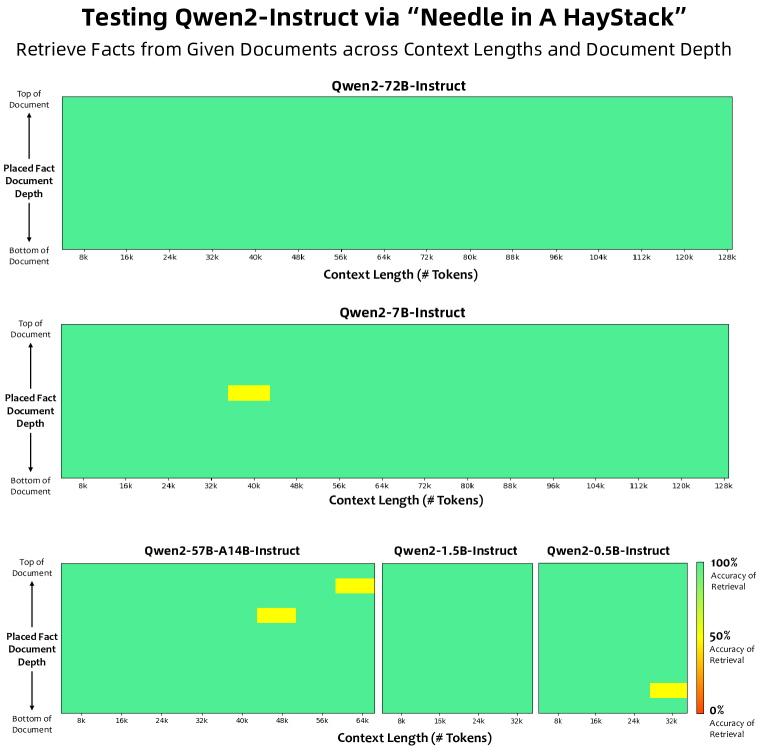
실험 결과
연구 질문
- RQ1Qwen2 dense 및 MoE 모델이 지식, 코딩, 수학, 추론, 다국어 벤치마크에서 공개 및 독점 기준선과 비교해 어떤 성능을 보이나요?
- RQ2긴 컨텍스트 학습과 데이터 확장이 모델의 능력과 신뢰성에 어떤 영향을 미치나요?
- RQ3확장 가능한 얼라인먼트(SFT + RLHF with DPO and online optimization)가 모든 언어에서 안전하고 정직하며 유용한 지시 수행 모델을 만들 수 있나요?
- RQ4Qwen2-MoE에서 미세한 MoE 라우팅 및 전문가 초기화의 트레이드오프와 효율성은 무엇인가요?
- RQ5가중치와 도구의 오픈 소스화가 다국어, 코딩, 추론 작업의 연구 및 배치를 얼마나 가속화하나요?
주요 결과
- Qwen2-72B는 기본 모델로 MMLU에서 84.2, GPQA에서 37.9, HumanEval에서 64.6, GSM8K에서 89.5, BBH에서 82.4를 달성한다.
- Qwen2-72B-Instruct는 MT-Bench에서 9.1, Arena-Hard에서 48.1, LiveCodeBench에서 35.7을 달성한다.
- Qwen2-57B-A14B MoE는 토큰당 14B 매개변수를 활성화하는 동시에 30B dense 모델의 성능과 맞먹거나 상회하며 강력한 코딩 및 수학 결과를 보인다.
- Qwen2는 영어, 중국어, 스페인어, 프랑스어, 독일어, 아랍어, 러시아어, 한국어, 일본어, 태국어, 베트남어 등을 포함한 약 30개 언어에 대해 강력한 다국어 능력을 보여준다.
- 더 작은 0.5B 및 1.5B 모델도 경쟁력 있는 성능을 보이며, 1.5B가 수학 및 중국어 이해에서 몇몇 기준선보다 우수하다.
- 오픈 가중치 및 보충 자료가 연구와 배치를 지원하기 위해 Hugging Face, ModelScope, GitHub에서 공개적으로 이용 가능하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.