[논문 리뷰] RAB: Provable Robustness Against Backdoor Attacks
이 논문은 백도어(오염) 공격에 대해 훈련 데이터에 대한 난수 스무딩을 사용하여 인증 가능한 강건성(training framework)을 제공하는 RAB를 제안하며, 이론적 보장과 효율적인 구현, 그리고 광범위한 벤치마크를 포함한다.
Recent studies have shown that deep neural networks (DNNs) are vulnerable to adversarial attacks, including evasion and backdoor (poisoning) attacks. On the defense side, there have been intensive efforts on improving both empirical and provable robustness against evasion attacks; however, the provable robustness against backdoor attacks still remains largely unexplored. In this paper, we focus on certifying the machine learning model robustness against general threat models, especially backdoor attacks. We first provide a unified framework via randomized smoothing techniques and show how it can be instantiated to certify the robustness against both evasion and backdoor attacks. We then propose the first robust training process, RAB, to smooth the trained model and certify its robustness against backdoor attacks. We prove the robustness bound for machine learning models trained with RAB and prove that our robustness bound is tight. In addition, we theoretically show that it is possible to train the robust smoothed models efficiently for simple models such as K-nearest neighbor classifiers, and we propose an exact smooth-training algorithm that eliminates the need to sample from a noise distribution for such models. Empirically, we conduct comprehensive experiments for different machine learning (ML) models such as DNNs, support vector machines, and K-NN models on MNIST, CIFAR-10, and ImageNette datasets and provide the first benchmark for certified robustness against backdoor attacks. In addition, we evaluate K-NN models on a spambase tabular dataset to demonstrate the advantages of the proposed exact algorithm. Both the theoretic analysis and the comprehensive evaluation on diverse ML models and datasets shed light on further robust learning strategies against general training time attacks.
연구 동기 및 목표
- 백도어 공격에 대한 인증 가능한 강건성 부족 문제를 해결한다.
- 난수 스무딩을 훈련 시_attack에 확장하는 통합 프레임워크를 개발한다.
- 백도어에 대해 강건성을 인증하는 RAB라는 강건한 학습 파이프라인을 제안한다.
- 이론적 경계(상한/하한)를 제시하고 이러한 경계의 타당성을 입증한다.
- 다양한 모델과 데이터셋에 대해 벤치마킹하여 기본적인 강건성 벤치마크를 확립한다.
제안 방법
- 테스트 입력과 학습 데이터를 모두 무작위화하는 스무딩된 분류기를 정의한다.
- Neyman–Pearson 보조정리를 사용하여 일반적이고 촘촘한 강건성 조건(Theorem 1)을 도출한다.
- 가우시안 및 균일 스무딩으로 프레임워크를 구체화하여 백도어 강건성을 인증한다(GaussianCorollary 1).
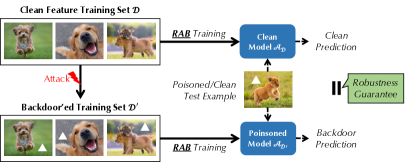
- RAB 학습을 제안한다: N개의 스무딩된 학습 세트를 생성하고, N개의 모델을 학습한 뒤 출력을 집계한다.
- 강건성 경계가 타이트하다는 것을 증명한다(Theorem 2).
- K-최근접 이웃(K-NN)을 위한 정확하고 효율적인 스무딩 알고리즘을 개발한다(몬테카를로 샘플링 불필요).
실험 결과
연구 질문
- RQ1ML 모델의 백도어(오염) 공격에 대한 강건성을 인증할 수 있는가?
- RQ2백도어 강건성을 인증하기 위해 스무딩 분포를 어떻게 선택할 수 있으며, 그에 따른 노름/경계는 무엇인가?
- RQ3강건성 경계가 타이트한가, 어떤 조건에서인가?
- RQ4K-NN과 같은 특정 모델 계통에 대해 어떻게 효율적으로 강건성을 인증할 수 있는가?
- RQ5실제 데이터셋에서 DNN, SVM, K-NN 간에 인증된 강건성 경계가 어떻게 유지되는가?
주요 결과
- 일반 ML 모델에 대한 백도어 공격에 대한 최초의 인증 가능한 강건성 경계.
- 강건성 경계가 타이트함(Theorem 2).
- 샘플링을 피하는 K-NN 모델용 정확하고 효율적인 스무딩 알고리즘이 제공된다.
- 광범위한 실험은 MNIST, CIFAR-10, ImageNette에서 DNN, SVM, K-NN 간의 강건성 경계를 시연하여 인증된 백도어 강건성의 벤치마크를 확립한다.
- Spambase 실험은 정확한 K-NN 스무딩 알고리즘의 이점을 보여준다.
- 코드와 평가 프로토콜이 재현 가능한 연구를 가능하게 공개적으로 공개된다.
![Figure 2 : An illustration of the RAB robust training process. Given a poisoned training set $\mathcal{D}+\Delta$ and a training process $\mathcal{A}$ vulnerable to backdoor attacks, RAB generates $N$ smoothed training sets $\{\mathcal{D}_{i}\}_{i\in[N]}$ and trains $N$ different classifiers $\mathc](https://ar5iv.labs.arxiv.org/html/2003.08904/assets/x2.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.