[논문 리뷰] RAG-Driver: Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model
RAG-Driver는 다중 모달 대형 언어 모델에 검색 augmented in-context learning(RA-ICL)을 도입하여 파인 튜닝 없이도 보지 못한 환경에 대한 강력한 제로샷 일반화를 바탕으로 운전 행동 설명, 정당화, 및 다음 제어 신호 예측을 제공한다.
We need to trust robots that use often opaque AI methods. They need to explain themselves to us, and we need to trust their explanation. In this regard, explainability plays a critical role in trustworthy autonomous decision-making to foster transparency and acceptance among end users, especially in complex autonomous driving. Recent advancements in Multi-Modal Large Language models (MLLMs) have shown promising potential in enhancing the explainability as a driving agent by producing control predictions along with natural language explanations. However, severe data scarcity due to expensive annotation costs and significant domain gaps between different datasets makes the development of a robust and generalisable system an extremely challenging task. Moreover, the prohibitively expensive training requirements of MLLM and the unsolved problem of catastrophic forgetting further limit their generalisability post-deployment. To address these challenges, we present RAG-Driver, a novel retrieval-augmented multi-modal large language model that leverages in-context learning for high-performance, explainable, and generalisable autonomous driving. By grounding in retrieved expert demonstration, we empirically validate that RAG-Driver achieves state-of-the-art performance in producing driving action explanations, justifications, and control signal prediction. More importantly, it exhibits exceptional zero-shot generalisation capabilities to unseen environments without further training endeavours.
연구 동기 및 목표
- 다중 모달 LLM 내에서 RA-ICL을 활용하여 엔드투엔드 자율주행의 설명가능성과 일반화 부족 문제를 해결한다.
- 검색된 전문가 시연에 기반한 운전 결정으로 행동 설명, 정당화, 제어 신호 예측을 개선한다.
- 추가 학습 없이 보이지 않는 환경에 강력한 제로샷 일반화를 보여준다.
- 드라이빙 설명 벤치마크에서의 최첨단 성능과 경쟁력 있는 제어 예측 정확도를 달성한다.
제안 방법
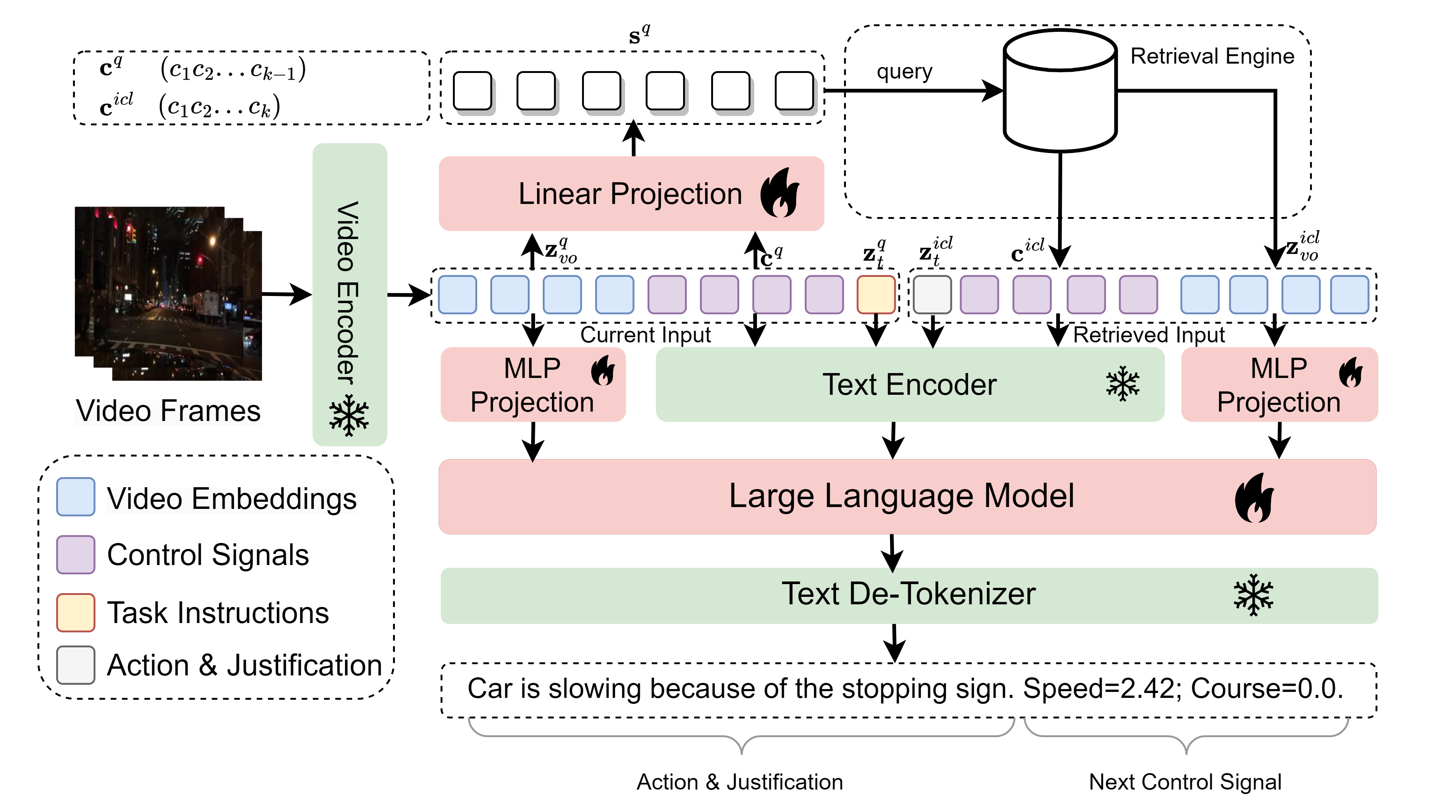
- 비디오 입력과 텍스트 지시로부터 운전 행동 설명, 정당화, 그리고 다음 제어 신호를 공동으로 예측하기 위해 멀티모달 LLM 백본(Vicuna 1.5)을 사용한다.
- 음성-언어 토큰과의 정렬을 위한 두 층 MLP 투사기가 있는 사전 학습 비디오 인코더(LanguageBind)을 채택하여 교차 모달 바인딩을 수행한다.
- 전문가의 설명과 정당화로 주석된 하이브리드 임베딩(비디오 + 제어 신호) 메모리 데이터베이스를 구성하고, 검색을 위해 Triplet 손실로 하이브리드 임베딩 공간을 학습한다.
- RA-ICL을 구현하기 위해 메모리에서 두 개의 유사한 운전 경험을 검색하여 쿼리에 접두사로 추가하고, 추론 중 암묵적 메타 최적화를 가능하게 하기 위해 MLLM으로 처리한다.
- 두 단계로 학습한다: (i) VIDAL-10M에서 시각-언어 정렬을 통한 사전 학습, (ii) 세 가지 작업(Action Explanation, Action Justification, Next Control Signal Prediction)을 위한 16K QA 페어로 구성된 BDD-X를 사용한 지도형 인-컨텍스트 지시 튜닝.
- RA-ICL을 구현하기 위해 하이브리드 임베딩 공간에서 코사인 유사도를 계산하여 RA-ICL에 가장 관련성이 높은 두 샘플을 검색한다.
실험 결과
연구 질문
- RQ1추적 학습 없이도 RA-ICL이 검색 augmented MLLM으로 운전 결정에 대한 설명가능성(행동 설명 및 정당화)을 개선하여 낯선 환경에서의 일반화를 가능하게 하는가?
- RQ2전 retrieved 전문가 시연으로 근거를 두는 것이 엔드-투-엔드 운전 작업에서 다음 제어 신호 예측(코스와 속도)의 정확성을 향상시키는가?
- RQ3운전 시나리오에서 검색에 대한 하이브리드(비디오 + 제어) 임베딩 대 시각적 전용 임베딩의 영향은 무엇인가?
- RQ4운전 작업용 MLLMs에서 효과적인 인-컨텍스트 학습을 위해 지도형 미세 조정이 필요한가, 아니면 메모리와 프롬프트가 있으면 제로샷 RA-ICL로 충분한가?
- RQ5RA-ICL이 제로샷으로 기존 방법에 비해 분포 밖 운전 환경에 얼마나 잘 일반화되는가?
주요 결과
- RAG-Driver는 BDD-X 벤치마크에서 최첨단 내적 운전 설명 성능을 달성한다.
- BDD-X에서 단독으로 학습된 경우에도 전문 제조사 및 일부 MLLM 기반 방법과 비교해 향상된 또는 경쟁력 있는 행동 설명 및 정당화를 산출한다.
- 하이브리드 검색을 통한 RA-ICL은 기반선(DriveGPT4 포함)보다 교정 허용오차 수준 및 RMSE에 걸쳐 제어 신호 예측(코스 및 속도)을 크게 향상시킨다.
- 변형 연구에서 하이브리드 유사도(하이브리드 비디오 + 제어)가 시각적 전용 유사도보다 우수하며, 학습 시점과 추론 시점의 ICL 모두 유익하다는 것을 보여준다.
- 메모리 데이터베이스를 이용한 BDD-X로 구성한 강력한 제로샷 일반화를 보여주며 낯선 환경(Spoken-SAX)에서 robust 일반화를 시연한다.
- qualitatively, 어두운 야간 및 악천후 조건에서도 이해하기 쉽고 인간이 이해할 수 있는 설명 및 정당화를 제공하여 실용적 설명가능성을 뒷받침한다.
![Figure 2 : Video Encoder architecture. Video is first split into $k\times 32\times 32$ patches concatenated in time, where these patches are linear projected to video embedding. Then, the model is trained with video-language contrastive learning (CLIP4clip) [ 49 ] to obtain language-align video repr](https://ar5iv.labs.arxiv.org/html/2402.10828/assets/images/RAGDriver_ViT.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.