[논문 리뷰] ReactionT5: a large-scale pre-trained model towards application of limited reaction data
ReactionT5는 T5를 기반으로 한 두 단계의 사전 학습 Transformer로 화합물과 ORD를 이용해 미세 조정 데이터가 제한된 상황에서 수율과 생성물 예측을 가능하게 한다. 분류되지 않은 ORD 화합물을 복원한 후 일반화 성능이 우수하고 경쟁력 있는 성능을 보인다.
Transformer-based deep neural networks have revolutionized the field of molecular-related prediction tasks by treating molecules as symbolic sequences. These models have been successfully applied in various organic chemical applications by pretraining them with extensive compound libraries and subsequently fine-tuning them with smaller in-house datasets for specific tasks. However, many conventional methods primarily focus on single molecules, with limited exploration of pretraining for reactions involving multiple molecules. In this paper, we propose ReactionT5, a novel model that leverages pretraining on the Open Reaction Database (ORD), a publicly available large-scale resource. We further fine-tune this model for yield prediction and product prediction tasks, demonstrating its impressive performance even with limited fine-tuning data compared to traditional models. The pre-trained ReactionT5 model is publicly accessible on the Hugging Face platform.
연구 동기 및 목표
- 다중 분자 반응에서 단일 분자 목표를 넘어서 확장 가능한 사전 학습 모델의 필요성에 대한 동기 제시.
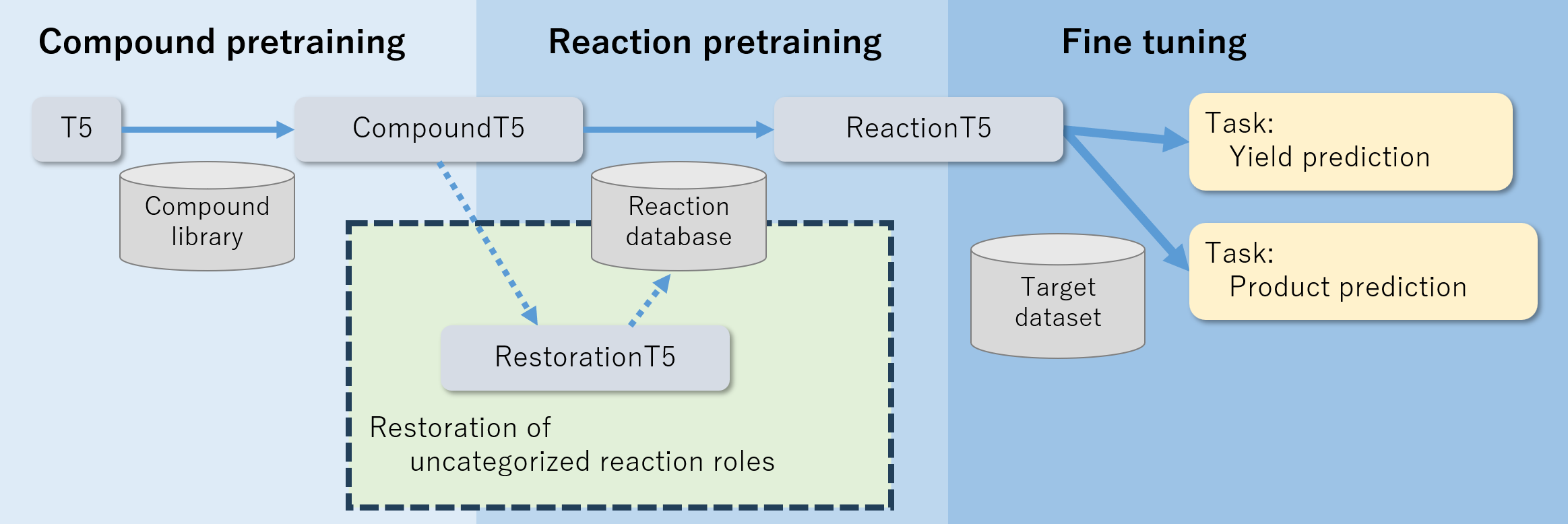
- ZINC 및 ORD 데이터 사용으로 CompoundT5를 거쳐 ReactionT5를 구성하는 두 단계의 사전 학습 파이프라인 개발.
- 제한된 미세 조정 데이터로도 생성물 및 수율 예측에 대한 모델의 효과성 시연.
제안 방법
- T5 아키텍처를 텍스트-투-텍스트 문제로 반응 작업 형식화.
- 1단계: ZINC의 SMILES를 사용한 span-masked language modeling으로 CompoundT5 구축 – 화합물 사전학습.
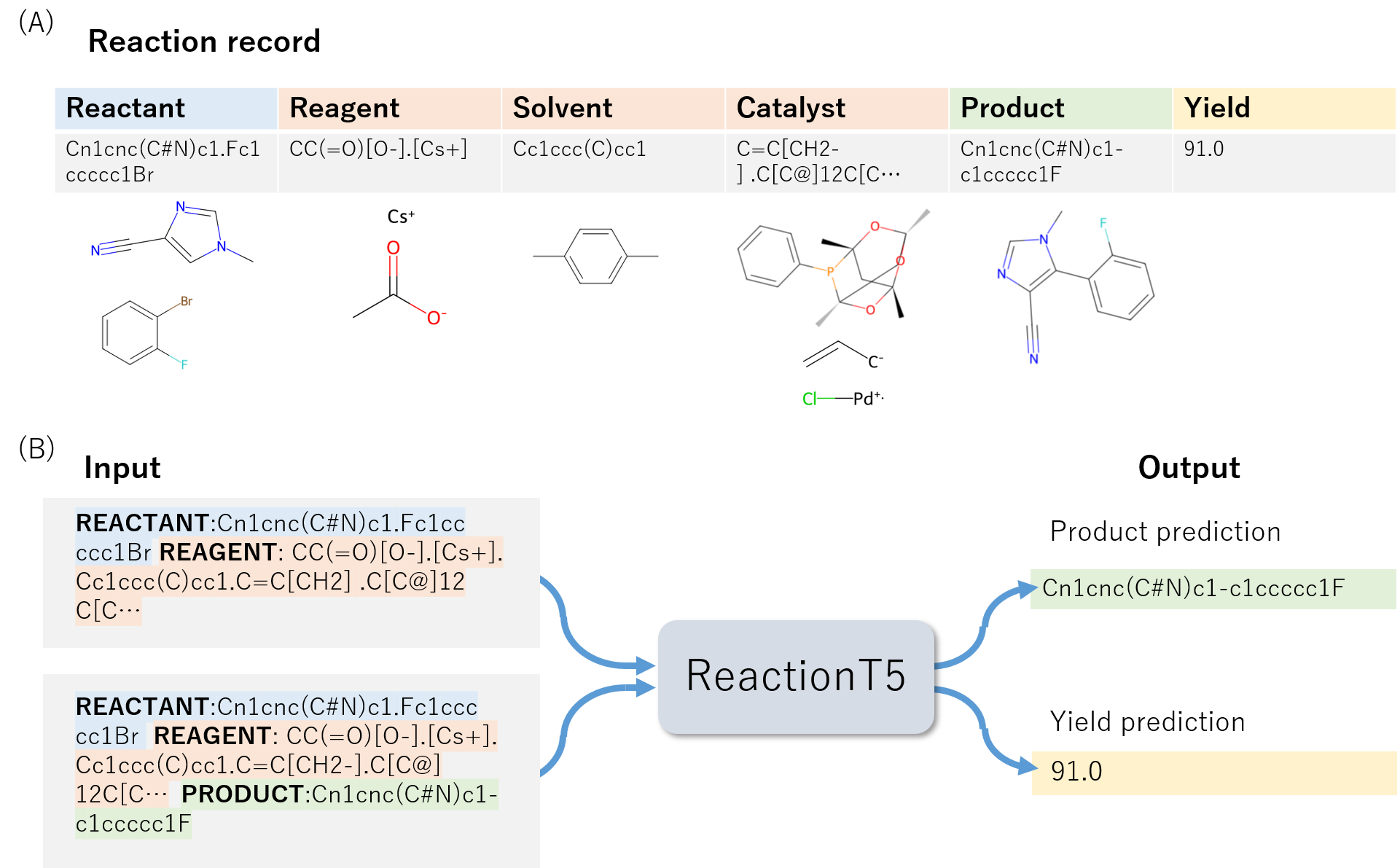
- 2단계: ORD 데이터의 여섯 가지 반응 역할(반응물, 시약, 용매, 촉매, 생성물, 수율)을 사용한 반응 사전학습으로 ReactionT5 구축.
- 미분류 ORD 화합물 분류 및 누락된 역할 복원을 위한 RestorationT5 도입.
- 대상 데이터 세트(USTPO를 이용한 생성물 예측 및 Buchwald–Hartwig C–N 크로스 커플링을 이용한 수율 예측)에 대한 ReactionT5 미세 조정.
- 생성물 예측에 대해 빔 서치 크기 10 사용 및 정확도 향상을 위한 길이 제약 최적화
실험 결과
연구 질문
- RQ1두 단계 사전 학습 Transformer(CompoundT5 → ReactionT5)가 소량의 대상 데이터에서 생성물 및 수율 예측을 향상시킬 수 있는가?
- RQ2 uncategorized ORD 화합물을 복원하는 것이 최소한의 미세 조정으로도 생성물 예측 성능을 향상시키는가?
- RQ3ReactionT5가 제로샷 및 저데이터 미세 조정 시나리오에서 전통적 모델과 비교하여 어떤 성능을 보이는가?
주요 결과
| 모델 | 학습 | 테스트 | Top1 | Top2 | Top3 | Top5 | 무효성 |
|---|---|---|---|---|---|---|---|
| Seq-to-seq | USPTO | USPTO | 80.3 | 84.7 | 86.2 | 87.5 | - |
| WLDN | USPTO | USPTO | 85.6 | 90.5 | 92.8 | 93.4 | - |
| Mol Transformer | USPTO | USPTO | 88.8 | 92.6 | - | 94.4 | - |
| T5Chem | USPTO | USPTO | 90.4 | 94.2 | - | 96.4 | - |
| CompoundT5 | USPTO | USPTO | 88.0 | 92.4 | 93.9 | 95.0 | 7.5 |
| ReactionT5(ORD) | - | USPTO | 0.0 | 0.0 | 0.0 | 0.0 | 0.6 |
| ReactionT5(ORD) | USPTO200 | USPTO | 0.0 | 0.0 | 0.0 | 0.0 | 4.2 |
| ReactionT5(restored ORD) | - | USPTO | 0.0 | 0.0 | 0.0 | 0.0 | 1.1 |
| ReactionT5(restored ORD) | USPTO200 | USPTO | 85.5 | 91.7 | 93.5 | 94.9 | 12.0 |
- ORD에서 복원된 uncategorized ORD 데이터를 사용한 ReactionT5 사전 학습은 제한된 USPTO 데이터로 미세 조정할 때 경쟁력 있는 생성물 예측 성능을 달성한다.
- 최소 30–200개의 USPTO 반응만으로도 생성물 예측에서 Top1 정확도 80% 이상을 달성하여 전체 데이터로 학습한 모델에 근접한 성능을 보인다.
- ORD에서 학습된 ReactionT5는 특히 외부 Test 1–4 데이터셋에서 수율 예측 태스크에 대해 강한 일반화 성능을 보여준다.
- RestorationT5는 ORD 기반 생성물 예측을 최소한의 추가 미세 조정으로 개선한다.
- 제로샷 ReactionT5는 수율 예측 태스크에서 30% 데이터로 학습된 일부 베이스라인보다 우수한 성능을 보일 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.