[논문 리뷰] Real-Time Detection and Analysis of Vehicles and Pedestrians using Deep Learning
본 논문은 도심 유사 데이터를 대상으로 실시간 차량 및 보행자 탐지를 위해 YOLOv8과 RT-DETR 모델을 비교하고, 기본선에서 YOLOv8m이 가장 강력하며 증강 후에는 YOLOv8l이 강력한 기반을 보이며, RT-DETR 변형도 경쟁력이 있다.
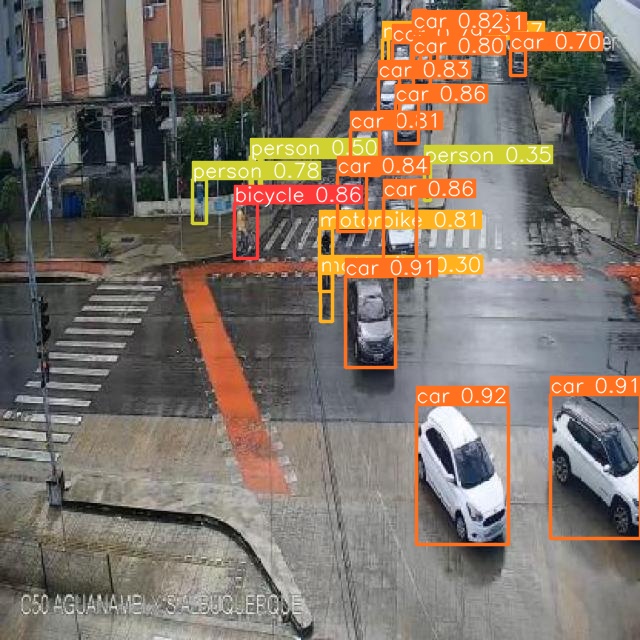
Computer vision, particularly vehicle and pedestrian identification is critical to the evolution of autonomous driving, artificial intelligence, and video surveillance. Current traffic monitoring systems confront major difficulty in recognizing small objects and pedestrians effectively in real-time, posing a serious risk to public safety and contributing to traffic inefficiency. Recognizing these difficulties, our project focuses on the creation and validation of an advanced deep-learning framework capable of processing complex visual input for precise, real-time recognition of cars and people in a variety of environmental situations. On a dataset representing complicated urban settings, we trained and evaluated different versions of the YOLOv8 and RT-DETR models. The YOLOv8 Large version proved to be the most effective, especially in pedestrian recognition, with great precision and robustness. The results, which include Mean Average Precision and recall rates, demonstrate the model's ability to dramatically improve traffic monitoring and safety. This study makes an important addition to real-time, reliable detection in computer vision, establishing new benchmarks for traffic management systems.
연구 동기 및 목표
- 다양한 도시 환경에서 실시간 차량 및 보행자 탐지를 위한 빠르고 정확한 딥 러닝 프레임워크를 개발한다.
- 트래픽 데이터에서 단일 단계 탐지기(YOLOv8 변형)와 트랜스포머 기반 탐지기(RT-DETR)를 평가한다.
- 기본선 및 증강 데이터 세트에서 성능을 평가하고 보행자 중심 결과를 살펴본다.
제안 방법
- 프리 공개 교통 영상에서 프레임 샘플링하여 6개 클래스에 걸친 3,388개 주석을 포함한 1,142장의 데이터셋을 만든다.
- 색조, 노출, 노이즈, 시어, 채도 및 흐림을 포함한 데이터 증강으로 데이터셋을 3,082장의 이미지를 확장한다.
- Baseline 및 augmented 데이터셋에서 YOLOv8(s, m, l, x) 및 RT-DETR(L, x) 모델 비교.
- 훈련: 배치 크기 8, 640x640 이미지, NVIDIA Tesla P1000에서 최대 100 에폭; 평가 지표로 mAP, 정밀도 및 재현율 사용.

실험 결과
연구 질문
- RQ1어떤 모델(YOLOv8 대 RT-DETR)이 실시간 차량 및 보행자 탐지에서 정확도와 속도 사이의 최적 트레이드오프를 제공하는가?
- RQ2데이터 증강이 모델 및 클래스(차량 대 보행자) 간 탐지 성능에 어떻게 영향을 주는가?
- RQ3기본선 및 증강 조건에서 각 클래스의 탐지 능력은 어떠하며 보행자 탐지는 차량 탐지에 비해 어떻게 다른가?
주요 결과
- YOLOv8m은 기본선에서 mAP 0.898, 정밀도 0.861, 재현율 0.867로 가장 높은 성능을 보인다.
- RT-DETR-x는 기본선에서 경쟁력 있는 mAP 0.878과 강한 정밀도 0.886 및 재현율 0.850을 보인다.
- 증강 데이터에서 YOLOv8l은 최고 mAP 0.909를 달성하며 정밀도 0.884와 재현율 0.861을 기록한다.
- 증강 데이터에서 보행자 탐지는 YOLOv8l이 mAP 0.822, 정밀도 0.909, 재현율 0.687(모델에 따라 다름)로 나타난다.
- 테스트 시 추론 속도: YOLOv8 계열은 40 FPS로 동작하며 RT-DETR은 25 FPS로 실시간 교통 모니터링에 적합하다는 것을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.