[논문 리뷰] RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion
RealmDreamer는 2D 확산 사전지식을 사용하여 3D 가우시안 스플래팅 모델을 초기화하고 텍스트에서 전방향 3D 씬을 생성하며, 다뷰 데이터 없이도 고충실도 기하학과 시차를 생성합니다.
We introduce RealmDreamer, a technique for generating forward-facing 3D scenes from text descriptions. Our method optimizes a 3D Gaussian Splatting representation to match complex text prompts using pretrained diffusion models. Our key insight is to leverage 2D inpainting diffusion models conditioned on an initial scene estimate to provide low variance supervision for unknown regions during 3D distillation. In conjunction, we imbue high-fidelity geometry with geometric distillation from a depth diffusion model, conditioned on samples from the inpainting model. We find that the initialization of the optimization is crucial, and provide a principled methodology for doing so. Notably, our technique doesn't require video or multi-view data and can synthesize various high-quality 3D scenes in different styles with complex layouts. Further, the generality of our method allows 3D synthesis from a single image. As measured by a comprehensive user study, our method outperforms all existing approaches, preferred by 88-95%. Project Page: https://realmdreamer.github.io/
연구 동기 및 목표
- 씬 규모의 3D 가우시안 스플래팅을 사용한 텍스트-투-3D 씬 합성을 시연한다.
- robust initialization 및 다중 뷰 일관성을 위해 2D 확산 사전을 활용한다.
- disoccluded 영역을 채우고 기하를 개선하기 위해 인페인팅과 깊이 확산 사전을 통합한다.
- 상세를 향상시키기 위해 샤프닝과 불투명도 규제화를 포함하는 미세 조정 단계를 제공한다.
제안 방법
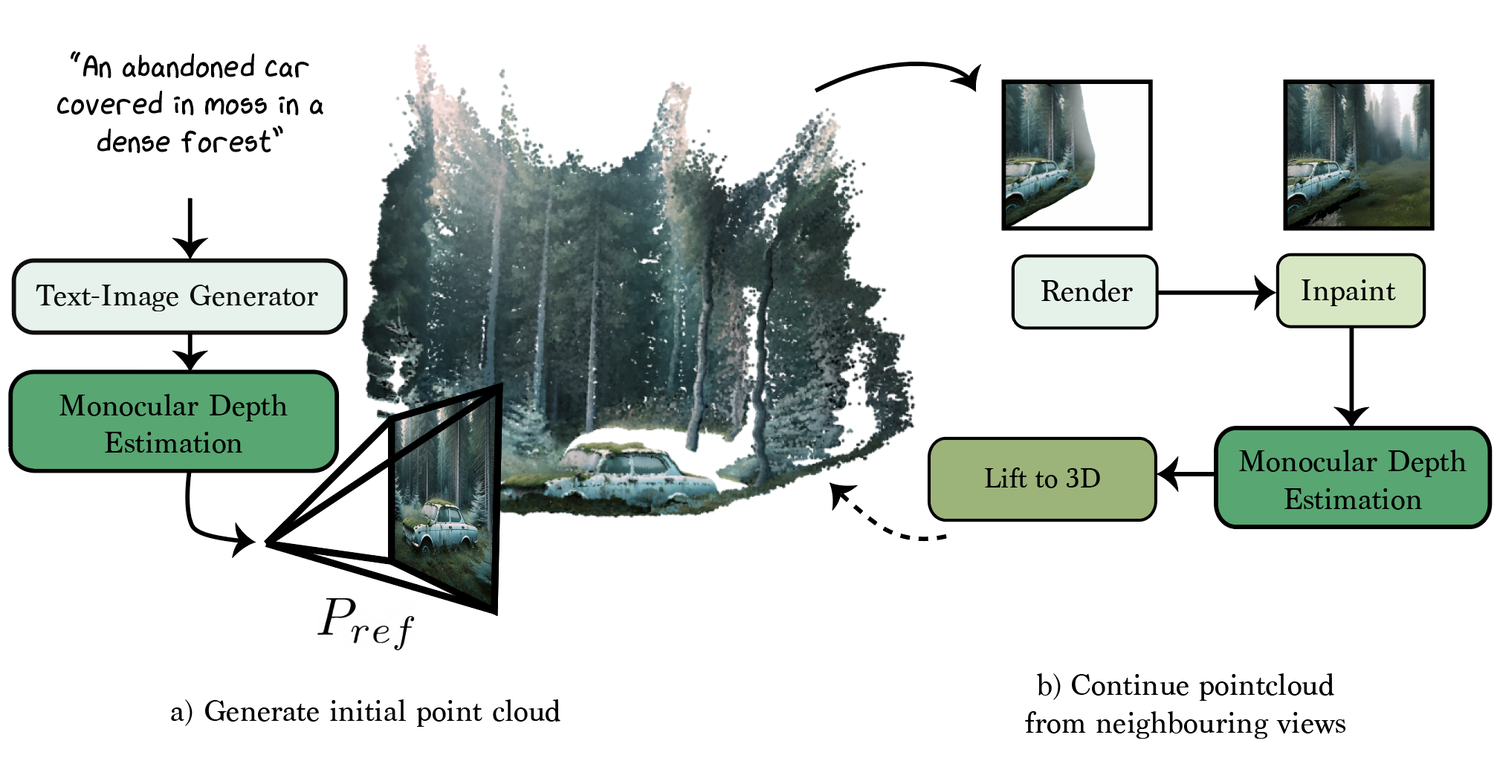
- 텍스트 프롬프트에서 2D 확산 사전 및 모노큘러 깊이를 사용하여 씬 수준 3D 가우시안 스플래팅 표현을 초기화하고, 오클루전 볼륨을 계산한 후 포인트 클라우드와 결합한다.
- 텍스트, 이미지 및 오클루전 마스크를 조건으로 하는 2D 인페인팅 확산 모델을 사용하여 씬 완성을 인페인팅 문제로 처리하고, 결합된 잠재공간 및 이미지 공간 손실 plus 지각 및 앵커 항으로 최적화한다.
- 깨끗한 인페인팅 샘플을 조건으로 사용하여 이미지-조건부 깊이 확산 모델에서 깊이 정보를 증류하고, 피어슨 상관에 기반한 깊이 손실을 최적화한다.
- 세부를 샤프닝하는 개인화된 텍스트-투-이미지 확산 모델로 미세 조정 단계를 수행하고, 이진 불투명도를 촉진하기 위한 불투명도 규제와 최종 렌더 품질을 향상시키는 샤프닝 필터를 샘플에 적용한다.
- 구현은 PyTorch3D, NeRFStudio, Stable Diffusion 2.0, Marigold 깊이 추정, DepthAnything 확장을 절대 깊이에 대해 활용한다.
![Figure 2 : Our method, compared to the state-of-the-art ProlificDreamer [ 66 ] , shows significant improvements. ProlificDreamer’s public results, with outward-looking cameras from a scene-independent sphere, result in poor depth quality. Even with a complex training trajectory, ProlificDreamer yiel](https://ar5iv.labs.arxiv.org/html/2404.07199/assets/figures/vsd_failure.png)
실험 결과
연구 질문
- RQ1텍스트 프롬프트만으로 비디오나 다중 뷰 데이터 없이 3D 씬 수준 생성을 어떻게 달성할 수 있는가?
- RQ22D 확산 사전(인페인팅 및 깊이)이 3D 가우시안 스플래팅 표현으로 증류되어 뷰 간 일관된 기하를 생성할 수 있는가?
- RQ3강건한 초기화와 이후의 인페인팅/깊이 증류가 씬의 충실도와 시차 현실성에 미치는 영향은 무엇인가?
- RQ4미세 조정 및 샤프닝 단계가 텍스트 프롬프트에 맞춰 정렬을 유지하면서 디테일을 향상시키는가?
- RQ5제안된 파이프라인을 사용하면 단일 이미지에서 3D 생성을 효과적으로 확장할 수 있는가?
주요 결과
- RealmDreamer는 시차 및 고충실도 기하를 갖춘 텍스트 기반 3D 씬 생성에서 최첨단의 정성적 결과를 달성한다.
- 기준치와 비교했을 때 더 일관된 기하와 더 선명한 렌더를 제공하며, 구름현상이나 과포화와 같은 잘못된 산출물이 적다.
- CLIP 기반 평가에서 RealmDreamer가 Text2Room, DreamFusion, ProlificDreamer보다 프롬프트와의 정렬이 더 높게 나타난다.
- 인페인팅 확산, 깊이 사전, 강건한 초기화 및 샤프닝의 중요성이 최종 품질에 기여한다는 것을 확인하는 애빌레이션 연구가 있다.
- 캡션이 달린 프롬프트와 함께 제공될 경우 단일 이미지에서도 3D 씬을 생성할 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.