[논문 리뷰] Reasoning before Comparison: LLM-Enhanced Semantic Similarity Metrics for Domain Specialized Text Analysis
이 논문은 GPT-4를 사용해 방사선 보고서에 대해 임상적으로 의미 있는 라벨을 생성하고 임베딩으로 의미적 유사성을 측정하며 ground truth에 대해 전통적인 어휘적 지표(ROUGE/BLEU)를 능가한다.
In this study, we leverage LLM to enhance the semantic analysis and develop similarity metrics for texts, addressing the limitations of traditional unsupervised NLP metrics like ROUGE and BLEU. We develop a framework where LLMs such as GPT-4 are employed for zero-shot text identification and label generation for radiology reports, where the labels are then used as measurements for text similarity. By testing the proposed framework on the MIMIC data, we find that GPT-4 generated labels can significantly improve the semantic similarity assessment, with scores more closely aligned with clinical ground truth than traditional NLP metrics. Our work demonstrates the possibility of conducting semantic analysis of the text data using semi-quantitative reasoning results by the LLMs for highly specialized domains. While the framework is implemented for radiology report similarity analysis, its concept can be extended to other specialized domains as well.
연구 동기 및 목표
- 의료 텍스트 분석에서 어휘적 유사성 지표(ROUGE/BLEU)의 한계를 동기 부여하고 이를 해결한다.
- GPT-4가 과제 기반 레이블을 생성하여 방사선 보고서를 의미적으로 비교하는 프레임워크를 제안한다.
- 레이블 해석가능성과 임상적 타당성을 개선하기 위해 인간 참여 루프(human-in-the-loop) 개념을 도입한다.
- MIMIC-CXR에서 CheXpert/NegBio 주석과 대조하여 의미-레이블 기반 유사성을 평가한다.
제안 방법
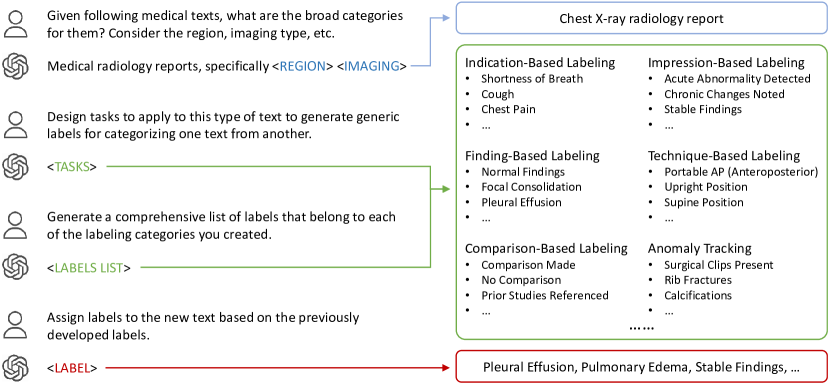
- 방사선 보고서의 제로샷 텍스트 식별에 GPT-4를 사용한다.
- 보고서에서 작업과 일반 라벨을 생성하도록 GPT-4를 사용하여 의미 범주화를 수행한다.
- 임상적 타당성을 확보하기 위해 인간 참여 검토를 통해 레이블을 생성한다.
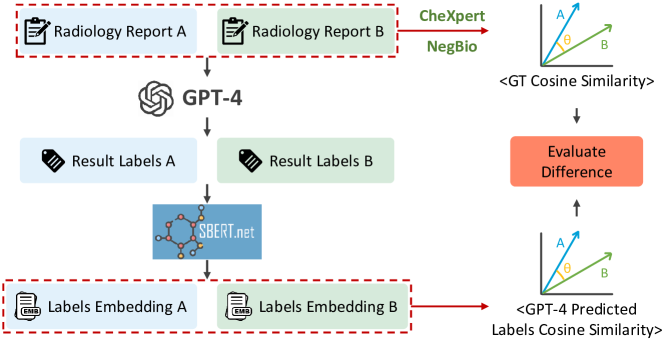
- GPT-4가 생성한 레이블을 all-mpnet-base-v2와 임베딩하고 코사인 유사성으로 의미적 유사성을 계산한다.
- GPT-4 레이블 기반 유사성을 CheXpert/NegBio 주석과 기존 ROUGE/BLEU 지표와 비교하여 62,500개의 보고서-쌍 비교에서 평가한다.
실험 결과
연구 질문
- RQ1GPT-4가 방사선 보고서를 실제 정답 발견과 의미적으로 정렬하는 임상적으로 의미 있는 레이블을 생성할 수 있는가?
- RQ2GPT-4가 생성한 레이블의 의미적 유사성이 전통적인 어휘 지표보다 실제 정답과 더 밀접하게 상관하는가?
- RQ3도메인 특화 의료 텍스트 분석에서 의미-레이블 유사성과 ROUGE/BLEU의 상대적 성능은 어떠한가?
주요 결과
- GPT-4가 생성한 유사성(GPT_sim)은 ROUGE 및 BLEU 지표보다 실제 정답과 더 가깝게 정렬된다.
- GPT_sim 평균 유사도 CheXpert/NegBio에 대해 각각: 0.1768 및 0.1793.
- ROUGE-1_F1, ROUGE-2_F1, ROUGE-L_F1 점수는 GT 비교에서 0.3654에서 0.5827까지의 범위를 보인다.
- BLEU 점수는 약 0.6 정도이지만 GPT_sim보다 실제 정답에서 더 큰 편차를 보인다.
- Ground-truth 기반 평가는 MIMIC-CXR 및 CheXpert/NegBio 라벨에서 파생된 62,500개의 보고서-쌍 비교를 사용했다.
- 본 방법론은 의료 텍스트의 의미를 전통적 어휘 지표에 비해 우수하게 포착한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.