[논문 리뷰] Recent Advances in Named Entity Recognition: A Comprehensive Survey and Comparative Study
이 설문조사는 그래프 기반, 트랜스포머 기반 모델, LLM, 저자원 방법을 포함한 최근 NER 접근법을 검토하고, 인기 프레임워크의 교차 데이터셋 비교를 제공합니다.
Named Entity Recognition seeks to extract substrings within a text that name real-world objects and to determine their type (for example, whether they refer to persons or organizations). In this survey, we first present an overview of recent popular approaches, including advancements in Transformer-based methods and Large Language Models (LLMs) that have not had much coverage in other surveys. In addition, we discuss reinforcement learning and graph-based approaches, highlighting their role in enhancing NER performance. Second, we focus on methods designed for datasets with scarce annotations. Third, we evaluate the performance of the main NER implementations on a variety of datasets with differing characteristics (as regards their domain, their size, and their number of classes). We thus provide a deep comparison of algorithms that have never been considered together. Our experiments shed some light on how the characteristics of datasets affect the behavior of the methods we compare.
연구 동기 및 목표
- NER 작업과 다양한 도메인에 걸친 응용을 정의한다.
- 현대의 NER 방법을 조사하고 분류하며, 트랜스포머 및 LLM에 중점을 둔다.
- 저자원/적은 주석 설정을 위해 설계된 방법들을 강조한다.
- 다양한 데이터셋에 걸친 인기 있는 NER 프레임워크의 실험적 비교를 제공한다.
제안 방법
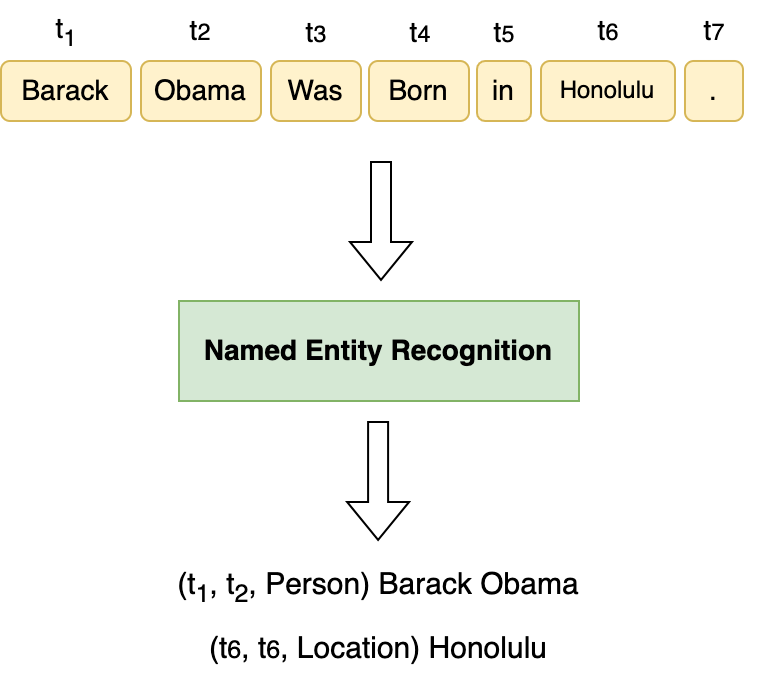
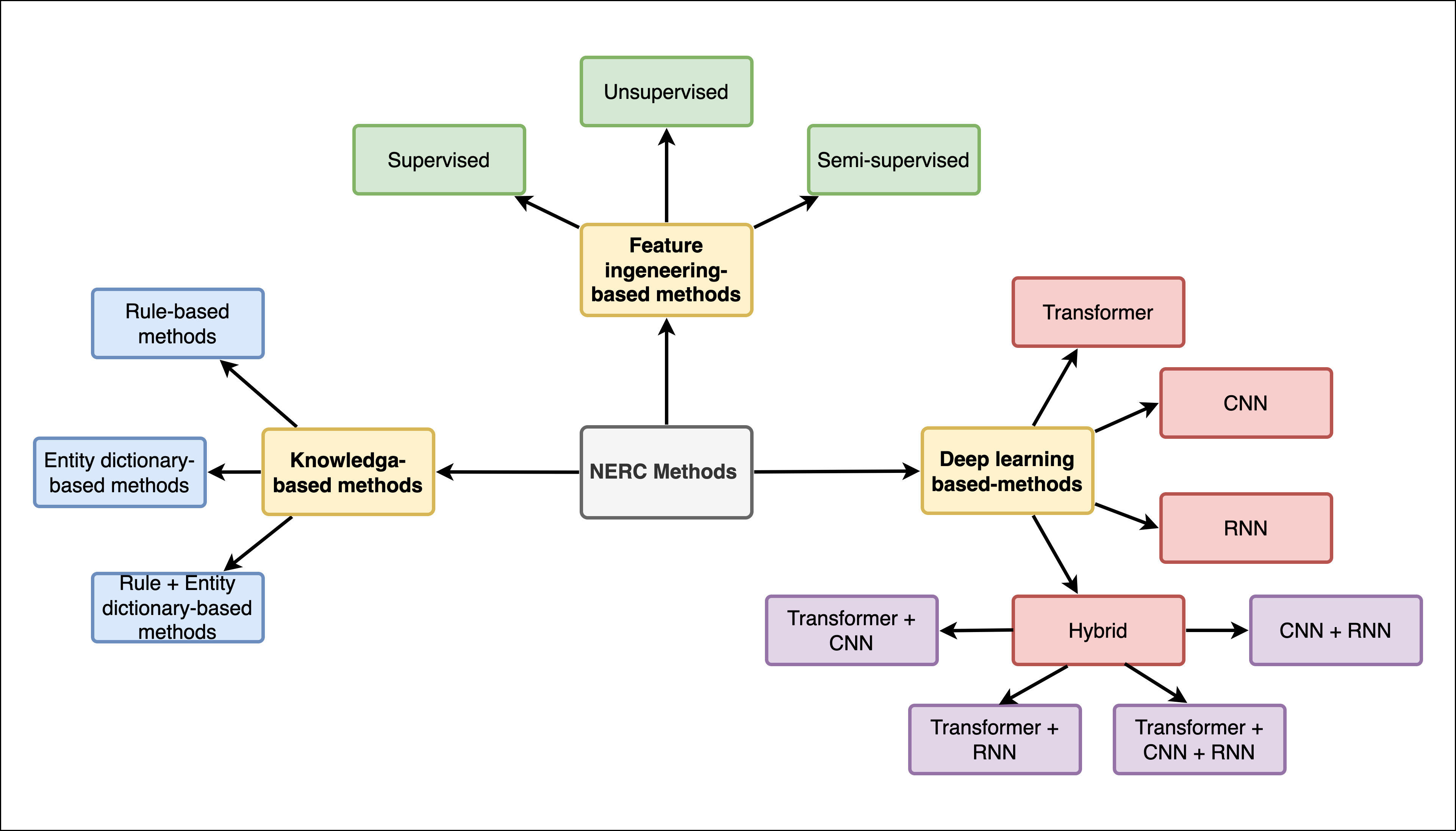
- 방법을 지식 기반, 특징 공학, 지도학습, 딥러닝(CNN/RNN/하이브리드), 트랜스포머 기반 인코더, 그리고 대형 언어 모델(LLM) 접근법으로 분류한다.
- 단어 및 문자 임베딩을 포함한 데이터 표현과 맥락 인코딩 전략(CNN, RNN, BiLSTM 및 트랜스포머)을 설명한다.
- 태그 디코딩 아키텍처(CRF, MLP, 포인터 네트워크)와 이들의 시퀀스 표기에 대한 영향을 논의한다.
- 트랜스포머 기반 모델(BERT, DistilBERT, RoBERTa)과 NER를 위한 적응, 다국어 및 도메인 특화 미세 조정 포함을 요약한다.
- LLM 기반 NER 접근법(텍스트 생성 프레이밍, 소수 샷 프롬프트)을 설명하고 관찰된 결과를 담은 연구 표를 제시한다.
실험 결과
연구 질문
- RQ1NER에서 지배적 방법론 트렌드(지식 기반, 지도학습, 딥러닝, 트랜스포머, LLM)는 무엇이며 어떻게 발전해 왔는가?
- RQ2데이터셋의 특성(도메인, 규모, 클래스 수)이 NER 방법의 상대적 성능에 어떻게 영향을 미치는가?
- RQ3저자원 또는 주석이 희소한 맥락에서의 NER의 도전과 효용은 무엇인가?
- RQ4트랜스포머 인코더와 LLM이 언어와 도메인에 걸쳐 NER 작업에서 전통적 아키텍처와 어떻게 비교되는가?
주요 결과
- 본 조사는 NER에서 트랜스포머 기반 인코더와 LLM의 부상하는 중요성을 강조한다.
- 저주석 설정에 맞춘 방법들을 강조하고 그들의 성능 영향에 대해 논의한다.
- 데이터셋 간 실험적 비교를 통해 데이터셋 특성이 방법의 효과에 어떤 영향을 미치는지 드러난다.
- LLM 기반 NER 접근법은 소수 샘플 및 저자원 시나리오에서 잠재력을 보여주며, 때때로 지도학습 기준선을 따라간다.
- NER를 위한 다양한 도구와 사전 학습 모델 자원이 평가 체계 및 말뭉치와 함께 검토된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.