QUICK REVIEW
[논문 리뷰] Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey
Bonan Min, Hayley Ross|arXiv (Cornell University)|2021. 11. 01.
Topic Modeling참고 문헌 182인용 수 161
한 줄 요약
대규모 사전학습 언어 모델(PLMs)이 사전 학습-미세조정, 프롬프팅, 텍스트 생성을 통해 NLP를 가능하게 하는 방식과 데이터 생성을 통한 보강 및 향후 방향에 대한 포괄적 고찰.
ABSTRACT
Large, pre-trained transformer-based language models such as BERT have drastically changed the Natural Language Processing (NLP) field. We present a survey of recent work that uses these large language models to solve NLP tasks via pre-training then fine-tuning, prompting, or text generation approaches. We also present approaches that use pre-trained language models to generate data for training augmentation or other purposes. We conclude with discussions on limitations and suggested directions for future research.
연구 동기 및 목표
- NLP에서 대규모 사전 학습 트랜스포머 모델로의 전환과 세 가지 주요 패러다임(사전 학습-그다음 미세조정, 프롬프트 기반 학습, 텍스트 생성으로서의 NLP)을 설명한다.
- 생성적 작업을 넘어 구문 분석, 정보 추출(IE), 질의응답(QA), TE, 그리고 감정 분석 등과 같은 작업에 PLMs가 어떻게 활용되는지 요약한다.
- 데이터 생성 접근법과 한계에 대해 논의하고 향후 연구 방향을 제시한다.
제안 방법
- 사전 학습-그다음 미세조정, 프롬프팅, 텍스트 생성의 세 가지 PLM 기반 패러다임과 데이터 생성 보완을 설명한다.
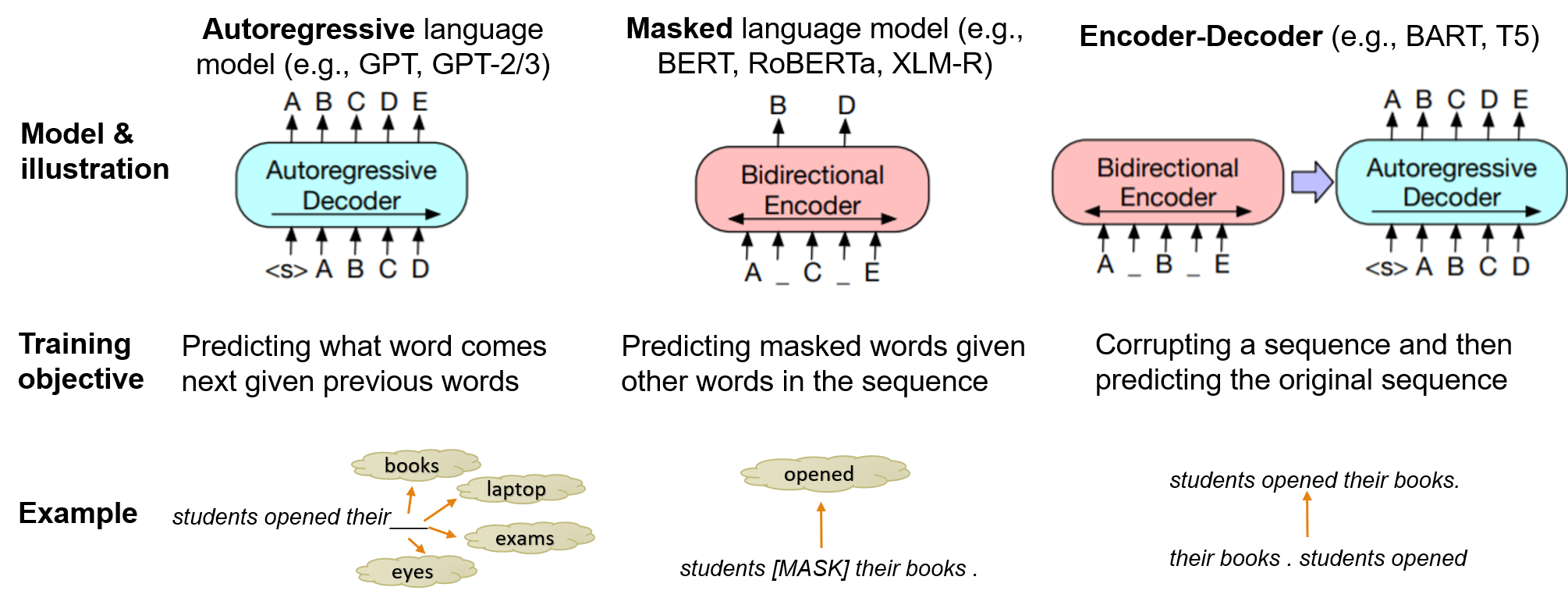
- 오토회귀(autoregressive), 마스크드 언어 모델(masked language models), 인코더-디코더의 모델 계층과 일반적인 사전 학습 목표를 상세히 설명한다.
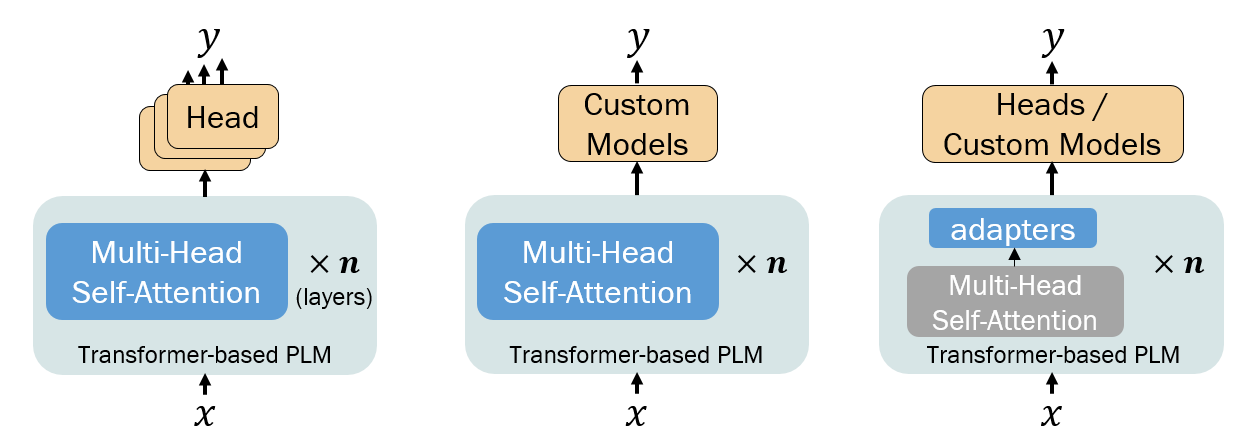
- 전체 미세조정, 어댑터 기반, 그리고 효율적인 미세조정 방법을 포함한 미세조정 전략을 요약한다.
- 데이터 원천, 규모 효과, 도메인 특화 사전 학습에 대해 논의한다.
- 프롬프트 설계 방법론과 적은 샷 학습 및 태스크 탐색에 대한 이점을 검토한다.
실험 결과
연구 질문
- RQ1NLP 작업을 해결하기 위한 지배적인 PLM 기반 패러다임은 무엇이며 접근 방식과 최적화에서 어떻게 차이가 나는가?
- RQ2모델 구조, 사전 학습 데이터, 그리고 미세조정 전략이 NLP 작업 전반의 성능에 어떤 영향을 미치는가?
- RQ3소수 샷 학습 및 태스크 정렬을 위한 PLM 활용에서 프롬프트의 역할은 무엇인가?
- RQ4PLMs를 어떻게 데이터 생성이나 훈련 보강에 활용할 수 있으며 한계는 무엇인가?
- RQ5NLP에서 PLMs의 현재 한계와 미래 방향은 무엇인가?
주요 결과
- PLMs는 세 가지 주요 패러다임을 통해 다양한 NLP 작업에서 최첨단 성능을 가능하게 한다: 사전 학습-그다음 미세조정, 프롬프트 기반 학습, 텍스트 생성을 통한 NLP.
- 오토회귀적(autoregressive), 마스킹(masked), 인코더-디코더(encoder-decoder) PLMs는 학습 목표와 다양한 작업 유형에 대한 적합성에서 차이를 보인다.
- 미세조정 전략은 전체 모델 튜닝에서 어댑터 및 매개변수 효율적 방법에 이르기까지 다양하며, 망각 억제와 훈련 비용 감소에 기여한다.
- 데이터 규모와 품질은 이익에 큰 영향을 주며, 모델 크기와 데이터세트 크기가 일반적으로 성능 향상을 주도한다; 데이터 정제는 매우 중요하다.
- 프롬프팅은 소수 샷 학습과 사전 학습 목표와의 더 나은 정렬을 가능하게 하며, 지시 기반 또는 시연 기반 프롬프트를 통해 무거운 미세조정 없이도 작업 성능을 향상시킨다.
- PLMs를 통한 데이터 생성은 대상 작업을 보조하기 위한 실버 데이터나 보조 맥락을 생성하는 보완적 접근이다.
- 한계로는 도메인 불일치, 확장성, 훈련 데이터 편향을 반영하는 잠재적 부정확성이 포함되며, 향후 방향은 효율성, 적응성, 견고성 향상이다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.