[논문 리뷰] Recent advances in text embedding: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark
본 조사는 MTEB에서 최상위 성능의 일반 텍스트 임베딩을 분석하고, 2023–2024년의 데이터, 손실 및 LLM 기반 접근법을 자세히 설명하며, 동향과 격차를 요약한다.
Text embedding methods have become increasingly popular in both industrial and academic fields due to their critical role in a variety of natural language processing tasks. The significance of universal text embeddings has been further highlighted with the rise of Large Language Models (LLMs) applications such as Retrieval-Augmented Systems (RAGs). While previous models have attempted to be general-purpose, they often struggle to generalize across tasks and domains. However, recent advancements in training data quantity, quality and diversity; synthetic data generation from LLMs as well as using LLMs as backbones encourage great improvements in pursuing universal text embeddings. In this paper, we provide an overview of the recent advances in universal text embedding models with a focus on the top performing text embeddings on Massive Text Embedding Benchmark (MTEB). Through detailed comparison and analysis, we highlight the key contributions and limitations in this area, and propose potentially inspiring future research directions.
연구 동기 및 목표
- MTEB 벤치마크가 우선순위로 삼는 일반 텍스트 임베딩을 검토하고 이를 검색, 분류, 클러스터링 및 기타 작업과의 관련성으로 동기를 부여한다.
- 문헌을 데이터 중심, 손실 중심, LLM 중심 가족으로 정리하여 일반 임베딩의 개발 방향을 명확히 한다.
- 주요 아키텍처들(GTE, BGE, E5, UAE, Multilingual-E5 등)과 데이터 품질, 다양성, 학습 신호가 성능에 미치는 영향을 요약한다.
- MTEB의 다중 작업, 다국어 평가 설정이 교차 작업 일반화에 맞춘 모델 설계를 어떻게 이끄는지 강조한다.
제안 방법
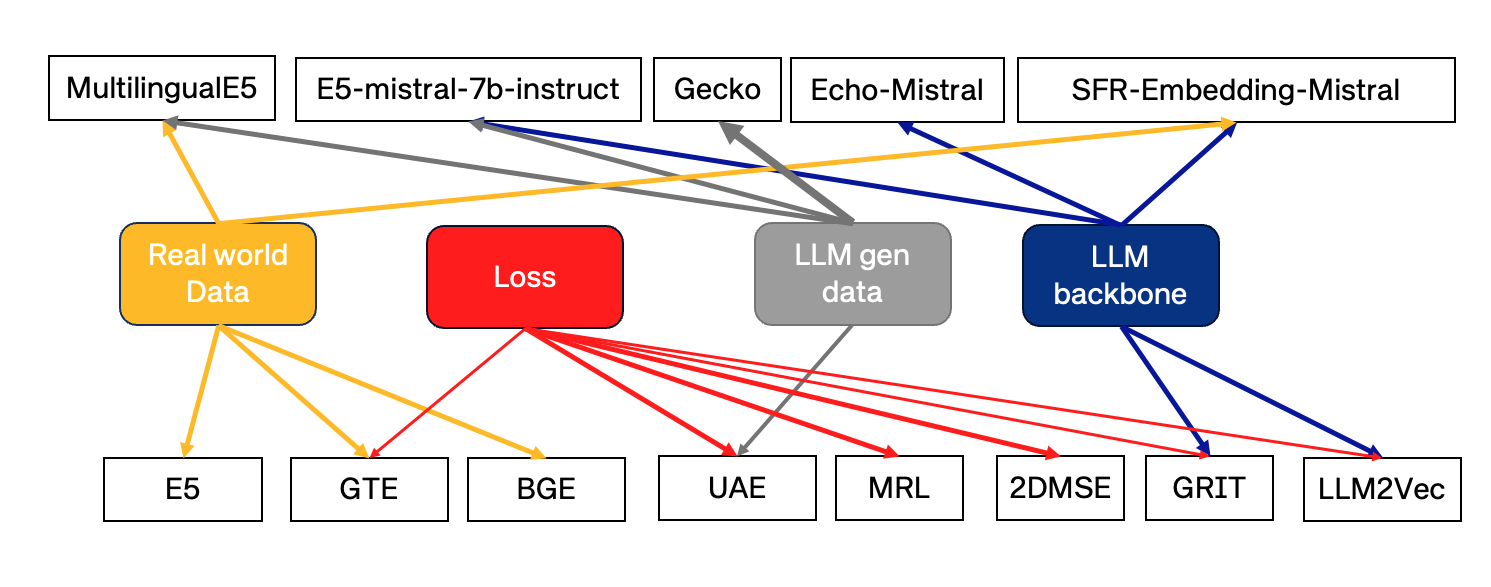
- 대규모의 다양하고 품질 높은 미세 튜닝 데이터를 포함한 데이터 중심 전략을 통해 보편 임베딩을 향상시키는 전략을 논의한다(예: CCPairs, CC 기반 소스, 다중 데이터셋 혼합).
- 대조 학습을 개선하고 그래디언트 문제를 다루는 손실 함수 혁신을 설명한다(예: 개선된 InfoNCE 변형, UAE의 각도 최적화).
- 사전 학습 및 미세 조정 단계에서 하드 네거티브, 배치 내 네거티브, 지식 증류의 역할을 설명한다.
- LLMs가 데이터 주석자 또는 백본으로 사용되어 보편성 및 다국어성을 향상시키는 방법을 요약한다(예: 합성 데이터, 지시 학습, 크로스 인코더 증류).
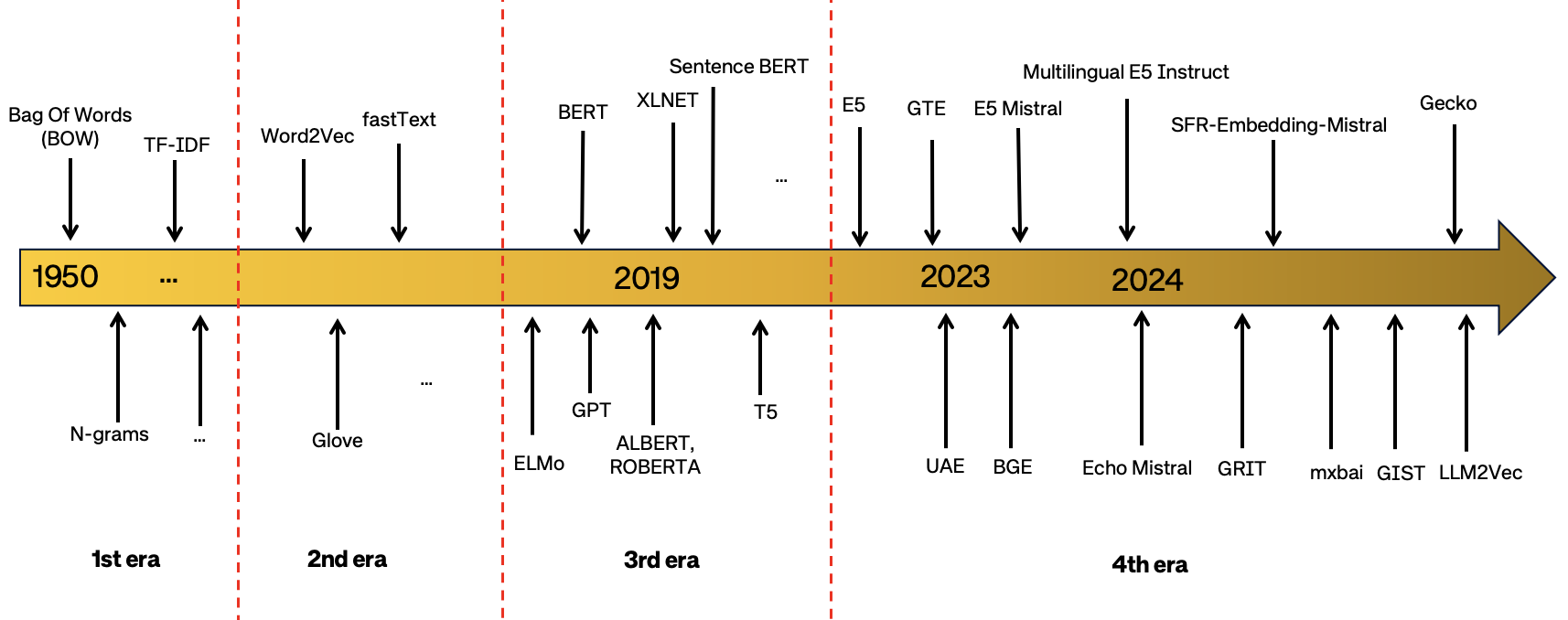
- 방법들에서 사용된 백본 모델과 학습 체계( BERT 계열, RoBERTa, 장기 의존 트랜스포머, 디코더 전용 LLM 등)를 요약한다.
실험 결과
연구 질문
- RQ1MTEB 맥락에서 보편 텍스트 임베딩이 무엇을 정의하며, 데이터, 손실, 모델 선택이 교차 작업 일반화에 어떤 영향을 미치는가?
- RQ2최고 성능 방법들이 58개 데이터셋과 112개 언어에서 성능을 향상시키기 위해 데이터 품질, 다양성, 합성 데이터를 어떻게 활용하는가?
- RQ3일반 임베딩을 위한 현재 데이터- 손실- 및 LLM 중심 접근법의 한계와 트레이드오프는 무엇인가?
- RQ4LLMs가 다양한 작업과 언어에 걸쳐 보편 임베딩을 향상시키기 위한 효과적인 백본 또는 주석자로서 어느 정도의 역할을 하는가?
- RQ5텍스트 임베딩의 보편성과 효율성을 더 향상시킬 수 있는 향후 방향은 무엇인가?
주요 결과
- MTEB의 최상위 모델은 광범위한 작업 커버리지를 달성하기 위해 대규모의 다양하고 고품질의 사전 학습 및 미세 조정 데이터를 의존한다.
- 손실 혁신과 그래디언트 문제 처리(예: 각도 최적화)가 최적화 및 임베딩 품질 향상에 기여한다.
- 배치 내 네거티브 샘플링과 하드 네거티브 샘플링, 크로스 인코더로부터의 증류가 검색 성능과 샘플-품질 임베딩을 향상시킨다.
- LLMs가 데이터 주석자와 백본 모델로서 다국어 및 다중 작업 성능을 향상시키기 위해 점점 더 많이 사용된다.
- Multilingual-E5 및 관련 모델은 다언어 데이터 혼합과 지시 데이터가 교차 언어 보편성에 기여하는 가치를 보여준다.
- 조사된 방법들은 일반 텍스트 임베딩에서 상당한 개선을 보여주지만, 보이지 않는 작업 및 도메인에 대한 일반화에는 여전히 도전이 남아 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.