[논문 리뷰] Reconstructing the Mind's Eye: fMRI-to-Image with Contrastive Learning and Diffusion Priors
MindEye는 fMRI 데이터를 해독하여 대조 학습과 확산 priors를 통해 뇌 활동을 CLIP 이미지 공간으로 매핑하여 이미지를 검색하고 재구성하며 최신의 검색 및 재구성 성능을 달성합니다.
We present MindEye, a novel fMRI-to-image approach to retrieve and reconstruct viewed images from brain activity. Our model comprises two parallel submodules that are specialized for retrieval (using contrastive learning) and reconstruction (using a diffusion prior). MindEye can map fMRI brain activity to any high dimensional multimodal latent space, like CLIP image space, enabling image reconstruction using generative models that accept embeddings from this latent space. We comprehensively compare our approach with other existing methods, using both qualitative side-by-side comparisons and quantitative evaluations, and show that MindEye achieves state-of-the-art performance in both reconstruction and retrieval tasks. In particular, MindEye can retrieve the exact original image even among highly similar candidates indicating that its brain embeddings retain fine-grained image-specific information. This allows us to accurately retrieve images even from large-scale databases like LAION-5B. We demonstrate through ablations that MindEye's performance improvements over previous methods result from specialized submodules for retrieval and reconstruction, improved training techniques, and training models with orders of magnitude more parameters. Furthermore, we show that MindEye can better preserve low-level image features in the reconstructions by using img2img, with outputs from a separate autoencoder. All code is available on GitHub.
연구 동기 및 목표
- 뇌 활동을 고차원 다중모달 임베딩(예: CLIP 이미지 공간)으로 매핑하여 이미지 재구성 및 검색이 가능함을 보인다.
- 두 작업을 동시에 최적화하도록 특화된 검색(검색) 및 재구성 하위 모듈을 개발한다.
- 매개변수가 많은(Multi-layer Perceptron) 백본이 데이터가 적은 환경에서도 과적합 없이 성능을 개선함을 보인다.
- 확산 priors를 활용하여 분리된 다중모달 임베딩을 정렬하고 고충실도 이미지 생성을 가능하게 한다.
- LAION-5B와 같은 대규모 후보 풀에서도 원본 이미지를 정확하게 검색할 수 있는 능력을 보여준다.
제안 방법
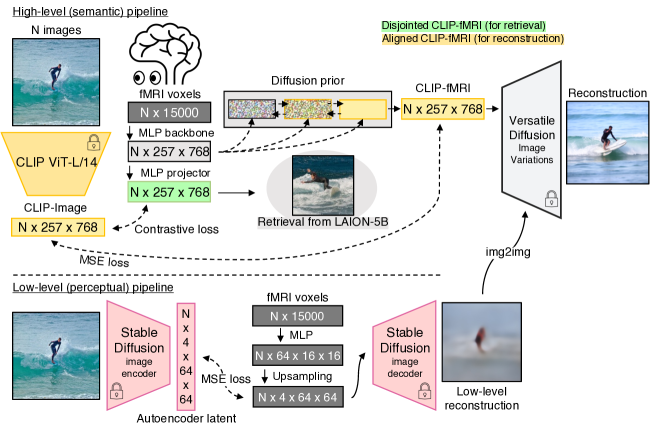
- 두 개의 병렬 파이프라인(고수준 시맨틱 → CLIP 이미지 공간, 저수준 지각적 → VAE 공간).
- 고수준 파이프라인은 fMRI 보폭을 CLIP 임베딩으로 매핑하는 MLP 백본을 사용하고, 재구성에는 확산 priors, 검색에는 프로젝터를 따른다.
- 저수준 파이프라인은 복셀을 Stable Diffusion의 VAE 임베딩으로 매핑하여 흐릿한 재구성을 생성하고 img2img 보완으로 개선된다.
- 훈련은 프로젝터에 대해 Bidirectional CLIP 손실(BiMixCo)을 사용하고, 확산 priors에 대해서는 MSE 손실을 사용하며 SoftCLIP을 증류에서 영감을 받은 소프트 타깃 신호로 사용한다.
- 확산 priors를 처음부터 학습시켜 뇌 임베딩을 CLIP 이미지 임베딩과 정렬한 뒤 사전학습된 이미지 생성기로 입력한다.
- 훈련은 BiMixCo와 SoftCLIP을 결합하며, 학습의 1/3 지점 이후 BiMixCo에서 SoftCLIP으로 전환되는 일정이다.
- 모델은 단일 A100 GPU로 240 에폭 학습이 가능하고, 모듈식 설계로 과적합 없이 큰 매개변수 수로 확장될 수 있다.
![Figure 1: Example images reconstructed from human brain activity corresponding to passive viewing of natural scenes. Reconstructions depict outputs from Versatile Diffusion [ 6 ] given CLIP fMRI embeddings generated by MindEye for Subject 1. See Figure 4 and Appendix A.4 for more samples.](https://ar5iv.labs.arxiv.org/html/2305.18274/assets/x1.png)
실험 결과
연구 질문
- RQ1뇌 활동을 CLIP 이미지 임베딩으로 매핑하여 정확한 이미지 재구성 및 검색이 가능함을 확인할 수 있는가?
- RQ2특화된 검색(대조 기반) 및 재구성(확산 기반) 하위 모듈이 통합 단일 공간 접근법보다 성능이 우수한가?
- RQ3대규모 매개변수 백본이 적은 데이터 환경에서 과적합 없이 성능을 향상시키는가?
- RQ4확산 priors가 뇌와 이미지 모달리티 간 임베딩 분리성을 완화하여 재구성 품질을 향상시키는가?
- RQ5뇌 기반 임베딩을 사용해 LAION-5B와 같은 대규모 후보 풀에서 원본 이미지를 정확히 검색할 수 있는가?
주요 결과
- MindEye는 이미지 검색과 뇌 검색 모두에서 최신 수준의 성능을 달성하며, Subject 1의 982-테스트 이미지 풀에서 상위 1위 검색 정확도가 90%를 넘는다.
- 고수준 시맨틱 파이프라인과 확산 priors의 결합이 Versatile Diffusion과 같은 사전학습된 이미지 생성기를 사용할 때 고품질 재구성을 보여준다.
- 잔차 블록이 있는 대형 MLP 백본은 검색 성능을 향상시키고, 모델 깊이가 증가함에 따라 스킵 연결이 중요해진다.
- BiMixCo와 SoftCLIP은 검색과 재구성 사이의 균형을 최적화하며, BiMixCo 단독은 검색에서 가장 강력한 성능을 보이고, 손실의 분리로 무게 조정이 용이하다.
- 저수준 재구성은 Stable Diffusion의 VAE 잠재공간으로 매핑하고 이후 img2img 보완을 통해 최첨단의 저수준 이미지 지표를 달성한다.
- 검색 임베딩은 미세한 예시 수준 정보를 보유하여 LAION-5B와 같은 대규모 후보 풀에서도 정확한 이미지 검색을 가능하게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.