[논문 리뷰] Redefining "Hallucination" in LLMs: Towards a psychology-informed framework for mitigating misinformation
논문은 LLM 오류에 대한 일반 용어 'hallucination'이 오해를 낳는다고 주장하고 심리학 기반 분류법(source amnesia, recency, availability, suggestibility, cognitive dissonance, confabulation)을 제시하며 메타인식에서 영감된 완화 전략을 제시한다.
In recent years, large language models (LLMs) have become incredibly popular, with ChatGPT for example being used by over a billion users. While these models exhibit remarkable language understanding and logical prowess, a notable challenge surfaces in the form of "hallucinations." This phenomenon results in LLMs outputting misinformation in a confident manner, which can lead to devastating consequences with such a large user base. However, we question the appropriateness of the term "hallucination" in LLMs, proposing a psychological taxonomy based on cognitive biases and other psychological phenomena. Our approach offers a more fine-grained understanding of this phenomenon, allowing for targeted solutions. By leveraging insights from how humans internally resolve similar challenges, we aim to develop strategies to mitigate LLM hallucinations. This interdisciplinary approach seeks to move beyond conventional terminology, providing a nuanced understanding and actionable pathways for improvement in LLM reliability.
연구 동기 및 목표
- LLMs에서 'hallucination'라는 용어를 비판적으로 평가하고 그것이 모델 출력 묘사에 얼마나 적합한지 평가한다.
- LLM 오류를 인지 편향 및 기억 현상에 매핑하는 심리학 기반 분류법을 제안한다.
- 인간의 메타인식 및 출처 모니터링에서 영감을 받은 구체적 완화 전략을 제안한다.
- LLM 신뢰성 향상을 위해 심리적 구성요소를 활용하는 타깃화된 완화 경로를 옹호한다.
제안 방법
- LLM hallucinations의 기존 정의와 분류 체계를 검토하고 종합한다.
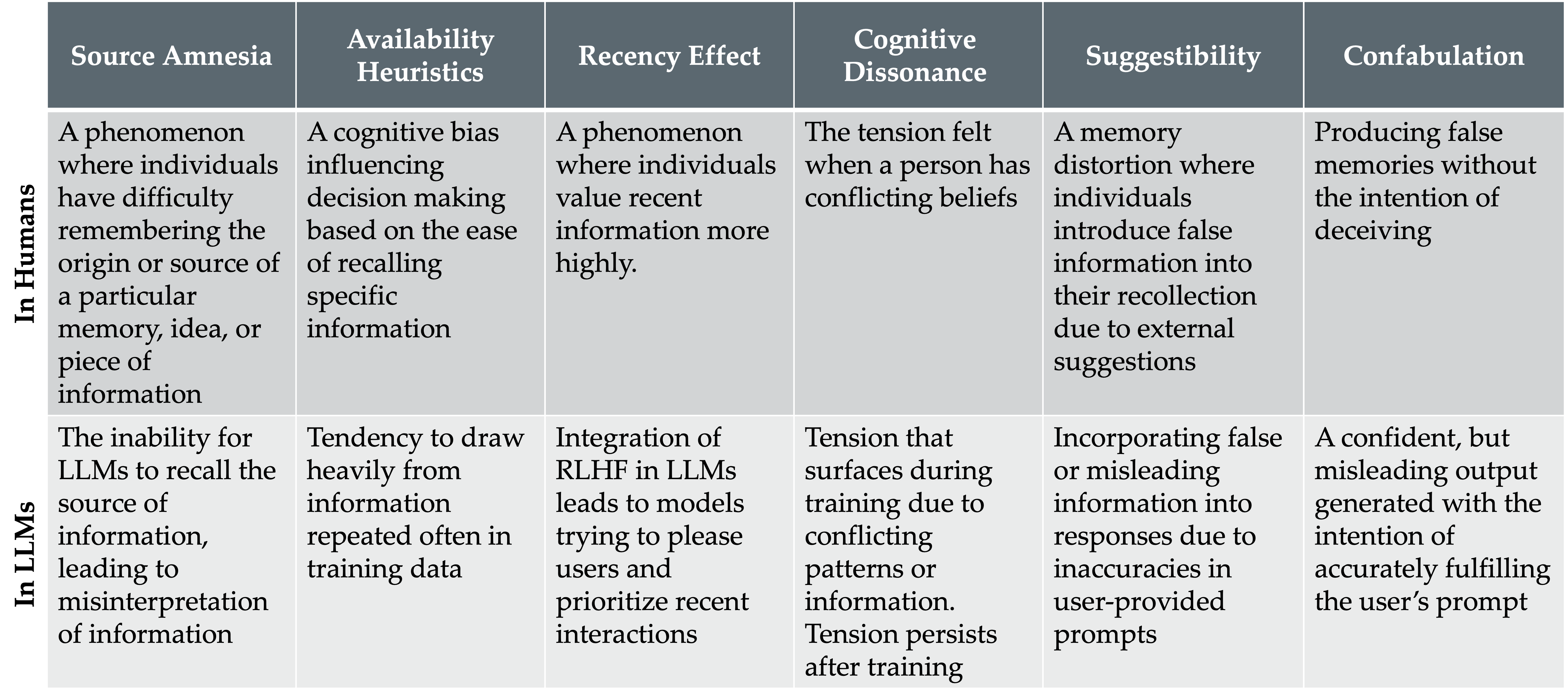
- 식별된 현상을 심리학적 개념에 매핑한다: source amnesia, recency effect, availability heuristics, suggestibility, cognitive dissonance, confabulation.
- 작업 특정 hallucination 라벨의 대안으로서 심리학 정보를 반영한 분류법을 옹호하고 설명한다.
- 향상된 출처 귀속, 출처 모니터링, 반성적 처리, 인위적 메타인식을 포함한 메타인식에서 영감을 받은 전략의 가능성을 논의한다.
- 제안된 완화를 위한 병행으로서 자기 성찰과 자기 탐구에 관한 관련 연구를 인용한다.

실험 결과
연구 질문
- RQ1LLM 출력에서 관찰되는 현상을 용어 'hallucination'이 얼마나 잘 포착하는가?
- RQ2심리학 기반의 분류법이 기존의 내재적/외재적 또는 작업 특이적 라벨보다 LLM 오류를 더 정확하게 분류할 수 있는가?
- RQ3사람의 메타인식에서 영감을 받은 어떤 완화 전략이 LLM 허위정보를 줄일 수 있는가?
- RQ4다양한 오류 유형과 가장 잘 맞는 심리적 구성요소는 무엇이며 타깃 수정을 안내하는가?
주요 결과
- 심리학 정보를 반영한 분류법이 LLM 오류 유형을 알려진 인지 편향과 기억 현상과 일치시킨다.
- source amnesia, recency effect, availability heuristics, suggestibility, cognitive dissonance, and confabulation이 서로 다르면서도 중첩되는 LLM 실패 모드에 매핑된다.
- 메타인식에서 영감을 받은 전략들(출처 귀속, 모니터링, 반성적 처리)이 LLM의 허위정보를 완화하기 위한 실용적인 방법으로 제시된다.
- 관련 연구의 자기성찰(self-reflection)과 자기 탐구(self-inquiry) 접근 방식은 hallucination과 유사한 출력 감소 가능성을 보여준다.
- 본 논문은 더욱 정확하고 표적화된 완화를 가능하게 하기 위해 'hallucination' 용어를 넘어서는 것을 주장한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.