[논문 리뷰] Reimagining Synthetic Tabular Data Generation through Data-Centric AI: A Comprehensive Benchmark
이 논문은 합성 표 형식 데이터 생성을 평가하고 안내하기 위한 데이터 중심 AI 프레임워크를 제시하며, 통계적 적합도만으로는 충분하지 않으며 데이터 프로필이 여러 생성 모델에서 다운스트림 유용성을 향상시킨다는 것을 보여준다.
Synthetic data serves as an alternative in training machine learning models, particularly when real-world data is limited or inaccessible. However, ensuring that synthetic data mirrors the complex nuances of real-world data is a challenging task. This paper addresses this issue by exploring the potential of integrating data-centric AI techniques which profile the data to guide the synthetic data generation process. Moreover, we shed light on the often ignored consequences of neglecting these data profiles during synthetic data generation -- despite seemingly high statistical fidelity. Subsequently, we propose a novel framework to evaluate the integration of data profiles to guide the creation of more representative synthetic data. In an empirical study, we evaluate the performance of five state-of-the-art models for tabular data generation on eleven distinct tabular datasets. The findings offer critical insights into the successes and limitations of current synthetic data generation techniques. Finally, we provide practical recommendations for integrating data-centric insights into the synthetic data generation process, with a specific focus on classification performance, model selection, and feature selection. This study aims to reevaluate conventional approaches to synthetic data generation and promote the application of data-centric AI techniques in improving the quality and effectiveness of synthetic data.
연구 동기 및 목표
- 합성 표 형식 데이터 생성에서 순수하게 통계적 충실도만으로 한계가 있음을 강조한다.
- 데이터를 프로파일링하고 합성 데이터 생성을 안내하는 데이터 중심 AI 프레임워크를 제안한다.
- 11개 데이터세트에 걸쳐 다섯 가지 최첨단 표 데이터 생성기를 벤치마크한다.
- 다운스트림 분류, 모델 선택, 특징 선택에 대한 데이터 중심 전처리/후처리의 영향을 평가한다.
- 합성 데이터 워크플로우에 데이터 중심 인사이트를 통합하기 위한 실용적 권고를 제공한다.
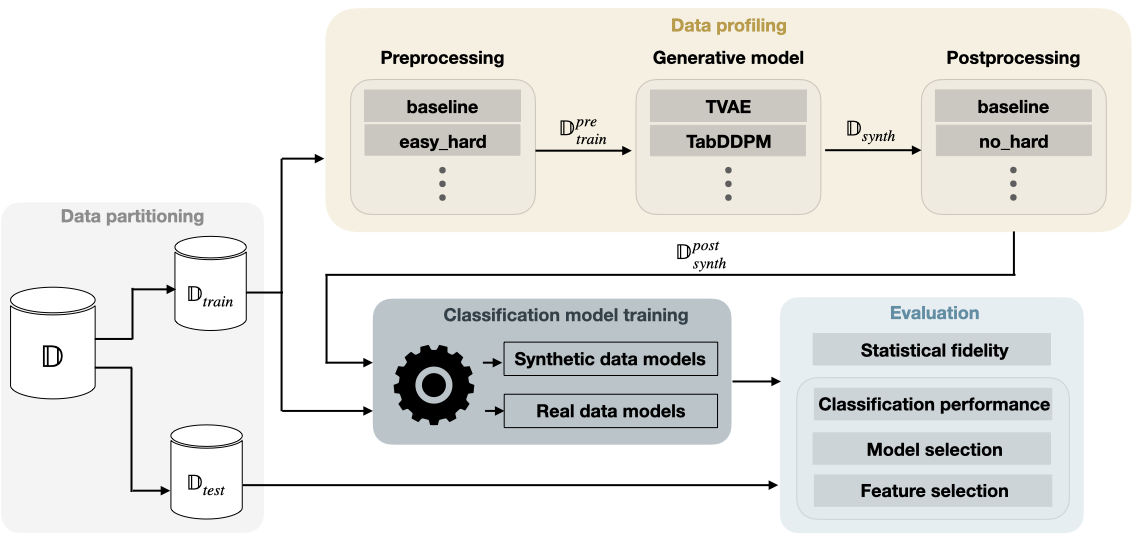
제안 방법
- Cleanlab, Data-IQ, 및 Data Maps와 같은 방법을 사용하여 데이터 중심 프로파일링(쉬움/모호함/어려움)을 정의한다.
- 훈련하기 전에 실제 훈련 데이터를 전처리하여 프로파일을 만든다.
- 다른 데이터 프로필에 대해 별도의 생성 모델을 학습하고 합성 데이터를 비례적으로 결합한다.
- 합성 데이터에 후처리 전략을 적용한다(기준선 vs. 어려운 예제 제거).
- 실제 데이터와 합성 데이터로 분류기를 학습하고 다운스트림 평가(AUROC, 순위)를 통해 비교한다.
- 분포/통계적 적합도를 역 KL, MMD, Wasserstein 등의 발산 지표로 평가하고 데이터 유용성 작업으로 확대한다.
![Figure 1: Measures of data-centric profiling (A) better reflect the downstream performance of generative models (B) than measures of statistical fidelity (C). Assessed on the Adult dataset [ 16 ] using five different generative models A) Proportion easy examples in the generated datasets identified](https://ar5iv.labs.arxiv.org/html/2310.16981/assets/figs/poc_proportions.png)
실험 결과
연구 질문
- RQ1통계적 충실도만으로 합성 표 데이터의 다운스트림 유용성을 예측할 수 있는가?
- RQ2데이터 중심 프로파일링이 분류, 모델 선택, 특징 선택에 대해 합성 데이터의 현실성과 유용성을 향상시킬 수 있는가?
- RQ3데이터 프로필에 의해 안내될 때 서로 다른 생성 모델은 다운스트림 작업에서 어떻게 성능을 보이는가?
- RQ4레이블 노이즈가 데이터 중심 전처리/후처리의 효과에 미치는 영향은 무엇인가?
주요 결과
| 생성 모델 | 분류 모델 | 선정 | 특징 선택 | 통계적 충실도 |
|---|---|---|---|---|
| Real data | 0.866 (0.855, 0.877) | 1.0 | 1.0 | 1.0 |
| bayesian_network | 0.622 (0.588, 0.656) | 0.155 (0.055, 0.264) | 0.091 (-0.001, 0.188) | 0.998 (0.998, 0.999) |
| ctgan | 0.797 (0.769, 0.823) | 0.519 (0.457, 0.579) | 0.63 (0.557, 0.691) | 0.979 (0.967, 0.987) |
| ddpm | 0.813 (0.781, 0.844) | 0.508 (0.446, 0.573) | 0.635 (0.546, 0.718) | 0.846 (0.668, 0.972) |
| nflow | 0.737 (0.713, 0.761) | 0.354 (0.288, 0.427) | 0.415 (0.34, 0.485) | 0.975 (0.968, 0.981) |
| tvae | 0.792 (0.764, 0.818) | 0.506 (0.436, 0.565) | 0.675 (0.63, 0.722) | 0.966 (0.953, 0.978) |
- 통계적 충실도만으로는 다운스트림 작업에 대한 합성 데이터 유용성을 판단하기에 불충분하다.
- 다른 생성 모델들(CTGAN, TabDDPM, TVAE)은 서로 다른 작업에서 뛰어나다(모델 선택, 특징 선택, 분류).
- 데이터 중심 전처리 및 후처리는 대부분의 모델과 데이터세트에서 분류, 모델 선택, 특징 선택을 향상시키는 경향이 있으며, 종종 통계적 충실도에서 다소 손실이 있다.
- 레이블 노이즈가 다양할 때 데이터 중심 처리의 이점은 지속되지만 노이즈가 높아지면 다소 감소한다(예: >8%).
- 단일 생성기가 모든 작업에서 우위를 보이지는 않으며 CTGAN과 TVAE가 종종 충실도와 다운스트림 유용성 간의 유리한 트레이드오프를 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.