[논문 리뷰] Reinforcement Learning-based Counter-Misinformation Response Generation: A Case Study of COVID-19 Vaccine Misinformation
본 논문은 MisinfoCorrect를 소개하는데, 이는 두 개의 새로운 데이터셋(현장 수집(in-the-wild) 및 크라우드소싱)을 사용하여 코로나19 백신 잘못된 정보에 대해 공손하고 증거에 기반하며 반박적인 응답을 생성하는 RL 기반의 반잘못 정보 응답 생성기이며, 이를 통해 베이스라인보다 우수함을 보인다.
The spread of online misinformation threatens public health, democracy, and the broader society. While professional fact-checkers form the first line of defense by fact-checking popular false claims, they do not engage directly in conversations with misinformation spreaders. On the other hand, non-expert ordinary users act as eyes-on-the-ground who proactively counter misinformation -- recent research has shown that 96% counter-misinformation responses are made by ordinary users. However, research also found that 2/3 times, these responses are rude and lack evidence. This work seeks to create a counter-misinformation response generation model to empower users to effectively correct misinformation. This objective is challenging due to the absence of datasets containing ground-truth of ideal counter-misinformation responses, and the lack of models that can generate responses backed by communication theories. In this work, we create two novel datasets of misinformation and counter-misinformation response pairs from in-the-wild social media and crowdsourcing from college-educated students. We annotate the collected data to distinguish poor from ideal responses that are factual, polite, and refute misinformation. We propose MisinfoCorrect, a reinforcement learning-based framework that learns to generate counter-misinformation responses for an input misinformation post. The model rewards the generator to increase the politeness, factuality, and refutation attitude while retaining text fluency and relevancy. Quantitative and qualitative evaluation shows that our model outperforms several baselines by generating high-quality counter-responses. This work illustrates the promise of generative text models for social good -- here, to help create a safe and reliable information ecosystem. The code and data is accessible on https://github.com/claws-lab/MisinfoCorrect.
연구 동기 및 목표
- 효과적이고 증거 기반의 반응을 생성하여 잘못된 정보에 대한 군중 주도 보정을 촉진한다.
- 소셜 미디어와 크라우드소싱으로부터 잘못된 정보 게시물과 반응에 대한 두 개의 주석 달린 데이터셋을 만든다.
- 유창성과 관련성을 보장하는 동시에 공손함, 반박 및 증거에 대해 보상하는 강화 학습 프레임워크를 개발한다.
제안 방법
- 두 개의 데이터셋을 구성한다: 현장 Twitter 파생 데이터셋은 754개의 잘못된 정보-대응반응 쌍, 그리고 591개의 크라우드소싱 반응 데이터셋.
- 반응에 대해 반박, 증거, 그리고 공손성과 같은 속성을 주석 달고 표본 분포를 보고한다.
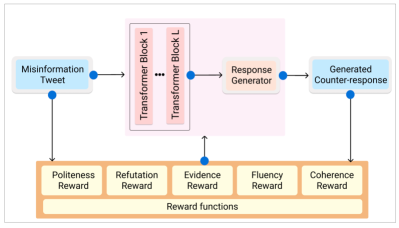
- GPT-2 기반 생성기인 MisinfoCorrect를 DialoGPT 가중치로 미세조정하고 합성 보상으로 RL을 사용해 학습시킨다.
- 상태를 잘못된 정보 게시물로, 행동을 생성된 반응으로, 정책을 트랜스포머 기반 생성기로 정의한다.
- 공손함, 반박, 증거, 유창성(역 perplexity), 일관성(게시물과의 의미적 유사성)에 대한 보상을 설계한다.
- 총 보상 r = α*r_politeness + β*r_refutation + γ*r_evidence + θ*r_fluency + λ*r_coherence; 보상 증강 목적 함수 L(θ) = -r*log p(ĉ|m)로 학습한다.
- DialoGPT 가중치로 초기화하고 페어링된 데이터를 사용한 워밍 스타트 전략을 적용한다; Adam으로 최적화한다.

실험 결과
연구 질문
- RQ1RQ1: 제안된 모델이 바람직한 속성을 갖춘 고품질의 반응을 생성할 수 있는가?
- RQ2RQ2: 현장 데이터와 크라우드소싱 데이터의 사용이 생성 품질에 어떤 영향을 미치는가?
주요 결과
- 총 1,345개의 반정보 응답이라는 두 개의 대규모 데이터셋이 생성되었다(754개 소셜 미디어 쌍; 591개 크라우드 생성).
- MisinfoCorrect는 고품질 반응 생성을 위해 다섯 가지 대표적 베이스라인을 능가한다.
- 공손함, 반박 및 증거는 RL 설정 내에서 맞춤형 보상을 통해 명시적으로 최적화된다.
- 이 접근법은 COVID-19 백신 잘못된 정보에 대해 증거에 기반하고 존중하는 반응을 학습하는 가능성을 입증한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.