[논문 리뷰] Researchy Questions: A Dataset of Multi-Perspective, Decompositional Questions for LLM Web Agents
이 논문은 Researchy Questions를 소개합니다. 이는 real search logs에서 추출된 비사실형(non-factoid)이고 분해적(decompositional)이며 다중 관점의 질문들로 구성된 대규모 데이터셋으로, LLM 웹 에이전트가 불분명한 정보 요구를 어떻게 다루는지 연구하기 위한 것입니다. 96k개의 질문과 관련 분해 계획 및 클릭된 증거가 포함되어 있습니다.
Existing question answering (QA) datasets are no longer challenging to most powerful Large Language Models (LLMs). Traditional QA benchmarks like TriviaQA, NaturalQuestions, ELI5 and HotpotQA mainly study ``known unknowns'' with clear indications of both what information is missing, and how to find it to answer the question. Hence, good performance on these benchmarks provides a false sense of security. A yet unmet need of the NLP community is a bank of non-factoid, multi-perspective questions involving a great deal of unclear information needs, i.e. ``unknown uknowns''. We claim we can find such questions in search engine logs, which is surprising because most question-intent queries are indeed factoid. We present Researchy Questions, a dataset of search engine queries tediously filtered to be non-factoid, ``decompositional'' and multi-perspective. We show that users spend a lot of ``effort'' on these questions in terms of signals like clicks and session length, and that they are also challenging for GPT-4. We also show that ``slow thinking'' answering techniques, like decomposition into sub-questions shows benefit over answering directly. We release $\sim$ 100k Researchy Questions, along with the Clueweb22 URLs that were clicked.
연구 동기 및 목표
- 현실의 사용자의 정보 요구에서 알려지지 않은 것들을 드러내는 복잡하고 비사실형(non-factoid) 질문의 필요성을 제기한다.
- 검색 로그 쿼리를 분해적 QA 데이터셋으로 채굴, 필터링, 중복 제거하는 구축 파이프라인을 설명한다.
- LLM 에이전트의 동작을 근거화하고 평가하기 위한 계층적 분해 및 증거 신호(클릭된 URL)를 제공한다.
- Researchy Questions를 활용한 분해적 응답의 이점과 사용자 검색 행동에 대한 통찰을 보여주는 기본 평가를 제시한다.
제안 방법
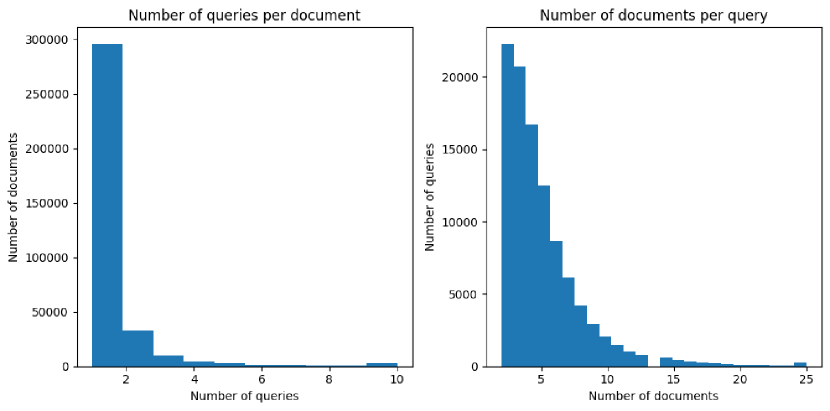
- 실제 영어 검색 로그를 채굴하여 최소 50건의 서로 다른 발생이 있고 다수의 클릭된 URL을 가진 후보 질문을 수집한다.
- 분류기와 GPT-4 라벨링을 이용해 분해적 응답에 적합한 비사실형의 개방도메인 질문을 선별하기 위한 단계별 후보 필터링.
- ANCE 기반 임베딩과 클러스터링을 사용하여 질의 의도의 응집식 중복 제거를 수행하고 그룹의 대표 헤드를 산출한다.
- 최종 GPT-4 기반 품질 검사를 적용하여 애매모호하거나 불완전하거나 추정적이거나 안전하지 않은 질문을 걸러 96k개의 질문을 산출한다.
- 각 질문에 대한 2-수준의 계층적 분해를 제공하고 해당 ClueWeb22 클릭된 URL를 증거 신호로 공개한다.

실험 결과
연구 질문
- RQ1What are Researchy Questions, and how do they differ from traditional factoid QA benchmarks?
- RQ2Can non-factoid, decompositional questions mined from search logs effectively reveal unknown unknowns for LLM web agents?
- RQ3Do hierarchical decompositions improve retrieval and synthesis for complex, multi-document queries compared to direct answering?
- RQ4What behavioral signals (e.g., clicks, session length) indicate greater effort and complexity in Researchy Questions?
- RQ5How do decompositional answering techniques compare to direct answering on long-form, multi-perspective questions?
주요 결과
- Researchy Questions are non-factoid, decompositional, and multi-perspective, requiring substantial research effort beyond a paragraph answer.
- Users spend more time and clicks on Researchy Questions, indicating higher information-seeking effort and diverse evidence needs.
- GPT-4-based decomposition approaches (especially factored decomposition) outperform direct closed-book answering on long-form, multi-faceted questions.
- Decompositional techniques yield accuracy and quality gains on long-form questions, with notable improvements for datasets like Wikihow and Researchy Questions.
- Approximately 96k questions are released, each with a 2-level hierarchical plan and a vector-based deduplication head, plus the associated ClueWeb22 clicked URLs.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.