[논문 리뷰] Resource Allocation and Workload Scheduling for Large-Scale Distributed Deep Learning: A Survey
이 논문은 2019–2024년의 대규모 분산 딥러닝에서 리소스 할당 및 작업 부하 스케줄링 전략을 조사하고, 대형 모델 학습에 대한 사례연구를 포함한다.
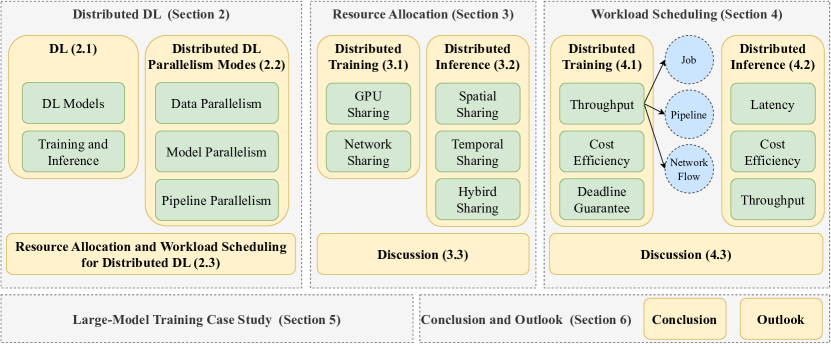
With rapidly increasing distributed deep learning workloads in large-scale data centers, efficient distributed deep learning framework strategies for resource allocation and workload scheduling have become the key to high-performance deep learning. The large-scale environment with large volumes of datasets, models, and computational and communication resources raises various unique challenges for resource allocation and workload scheduling in distributed deep learning, such as scheduling complexity, resource and workload heterogeneity, and fault tolerance. To uncover these challenges and corresponding solutions, this survey reviews the literature, mainly from 2019 to 2024, on efficient resource allocation and workload scheduling strategies for large-scale distributed DL. We explore these strategies by focusing on various resource types, scheduling granularity levels, and performance goals during distributed training and inference processes. We highlight critical challenges for each topic and discuss key insights of existing technologies. To illustrate practical large-scale resource allocation and workload scheduling in real distributed deep learning scenarios, we use a case study of training large language models. This survey aims to encourage computer science, artificial intelligence, and communications researchers to understand recent advances and explore future research directions for efficient framework strategies for large-scale distributed deep learning.
연구 동기 및 목표
- 대규모 분산 DL용 리소스 할당 및 작업 부하 스케줄링 프레임워크를 체계적으로 검토한다.
- 리소스 유형(GPU, 네트워크) 및 스케줄링의 정밀도(작업 단위, 파이프라인, 네트워크 흐름) 간의 도전 과제를 분석한다.
- 데이터 센터에서의 실무 배치를 안내하는 인사이트를 제공하기 위해 기존 기술을 비교한다.
- 대형 모델 분산 학습의 사례 연구를 통해 응용 사례를 제시한다.
- 효율성 및 확장성을 개선하기 위한 향후 연구 방향을 제안한다.
제안 방법
- 2019–2024년 분산 DL 리소스 관리 및 스케줄링에 대한 체계적 문헌 조사를 수행한다.
- 전략을 리소스 유형(GPU 공유, 네트워크 공유) 및 스케줄링 정밀도(작업, 파이프라인, coflow)별로 분류한다.
- 학습 및 추론 워크플로우와 다중 성능 목표를 중심으로 분석을 정리한다.
- 대형 모델 분산 학습에 대한 사례 연구를 제공하여 실제 적용을 시연한다.
- 향후 연구를 안내하기 위한 도전과제와 핵심 인사이트의 종합을 제시한다.
실험 결과
연구 질문
- RQ1대규모 분산 DL에서 리소스 할당 및 워크로드 스케줄링의 주요 도전은 무엇인가?
- RQ2GPU 공유 및 네트워크 대역폭 공유에 어떤 전략이 있으며, 스케줄링 정밀도에 따라 어떻게 다른가?
- RQ3데이터 센터에서 학습 및 추론 성능을 개선하기 위해 이러한 프레임워크 전략을 실제로 어떻게 적용할 수 있는가?
- RQ42019년부터 2024년까지의 문헌 조사를 통해 어떤 통찰과 향후 방향이 도출되는가?
주요 결과
- 이 조사는 대규모 분산 DL의 학습 및 추론 전반에 걸친 리소스 할당 및 워크로드 스케줄링 프레임워크를 포괄적으로 맵핑한다.
- GPU 공유, 네트워크 대역폭 공유, 그리고 작업, 파이프라인 및 네트워크 흐름 수준의 스케줄링에 대한 핵심 도전 과제를 강조한다.
- 관련 조사를 비교하고, 계산-통신 최적화를 결합하는 측면을 강조하여 격차를 메운다.
- 대형 모델 분산 학습에 대한 사례 연구를 제공하여 데이터 센터의 실용적 응용을 시연한다.
- 격차를 식별하고 효율적인 프레임워크 전략을 위한 향후 연구 방향을 제안한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.