[논문 리뷰] Rethinking and Improving Relative Position Encoding for Vision Transformer
이 논문은 시각 Transformer에서 방향성 상대 거리와 자기주의 주변 상대 위치 상호작용을 모델링함으로써 성능을 햖थ하는 이미지 전용 상대 위치 인코딩(iRPE) 방법을 제안한다. 이 방법은 하이퍼파라미터 조정 없이 ImageNet에서 최대 1.5%의 top-1 정확도 향상과 COCO에서 1.3%의 mAP 향상을 달성하며, 이미지 분류에서는 절대 인코딩을 효과적으로 대체할 수 있음을 보여주며, 객체 검출에서는 여전히 필수적임을 입증한다.
Relative position encoding (RPE) is important for transformer to capture sequence ordering of input tokens. General efficacy has been proven in natural language processing. However, in computer vision, its efficacy is not well studied and even remains controversial, e.g., whether relative position encoding can work equally well as absolute position? In order to clarify this, we first review existing relative position encoding methods and analyze their pros and cons when applied in vision transformers. We then propose new relative position encoding methods dedicated to 2D images, called image RPE (iRPE). Our methods consider directional relative distance modeling as well as the interactions between queries and relative position embeddings in self-attention mechanism. The proposed iRPE methods are simple and lightweight. They can be easily plugged into transformer blocks. Experiments demonstrate that solely due to the proposed encoding methods, DeiT and DETR obtain up to 1.5% (top-1 Acc) and 1.3% (mAP) stable improvements over their original versions on ImageNet and COCO respectively, without tuning any extra hyperparameters such as learning rate and weight decay. Our ablation and analysis also yield interesting findings, some of which run counter to previous understanding. Code and models are open-sourced at https://github.com/microsoft/Cream/tree/main/iRPE.
연구 동기 및 목표
- 상대 위치 인코딩(RPE)이 절대 위치 인코딩에 비해 시각 Transformer에서 효과적인가에 대한 논란을 해결하기 위해.
- 1차원 RPE 확장의 한계를 해결하기 위해 2차원 이미지 데이터에 특화된 RPE 방법을 설계하기 위해.
- 방향성 상대 거리와 쿼리-RPE 상호작용을 통합함으로써 시각 Transformer의 공간 인덕티브 바이어스 모델링을 향상시키기 위해.
- 계산 비용을 크게 증가시키지 않으면서도 경량이며 즉시 사용 가능한 솔루션을 제공하기 위해.
- 이미지 분류와 객체 검출 작업에서 RPE의 역할을 경험적으로 명확히 하기 위해.
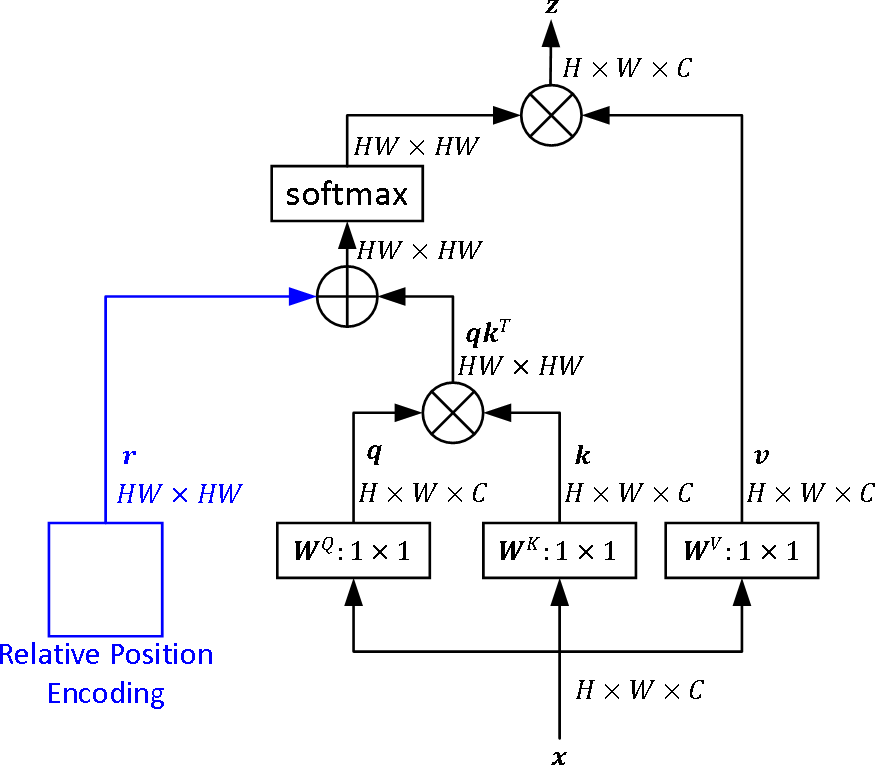
제안 방법
- 2차원 이미지에 특화된 수평 및 수직 상대 거리를 명시적으로 모델링하는 데 목적이 있는 네 가지 새로운 상대 위치 인코딩 방법(iRPE)을 제안한다.
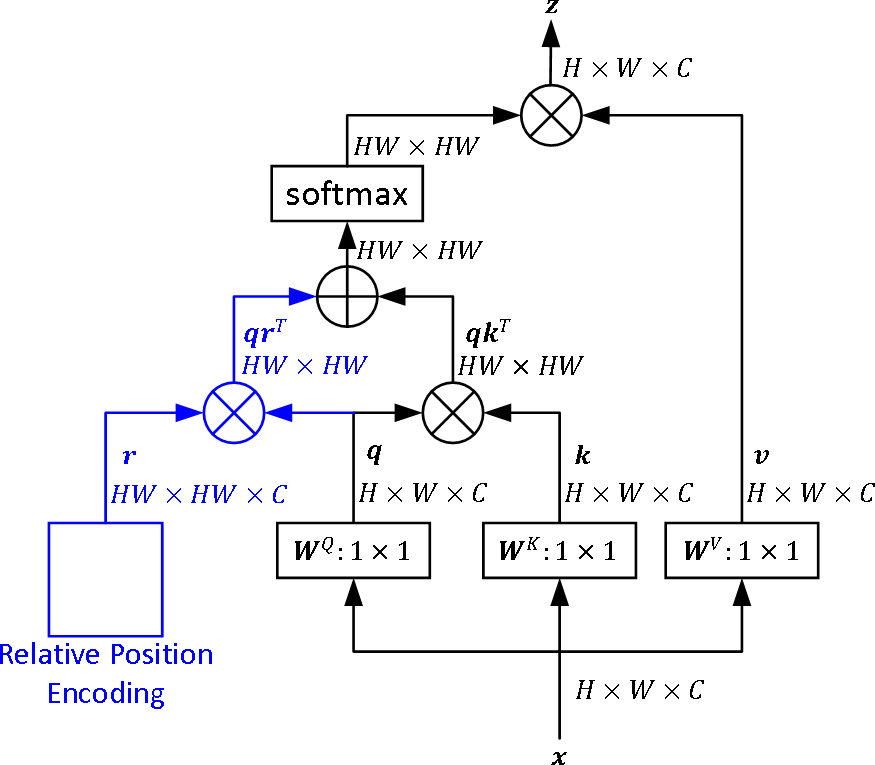
- 쿼리 특징과 상대 위치 임베딩을 결합하여 어텐션 가중치를 계산하는 컨텍스트 기반 곱셈 메커니즘을 도입함으로써 상호작용 모델링을 향상시킨다.
- 다중 헤드 어텐션 헤드 간에 공유된 RPE 테이블을 사용하여 파라미터를 줄이면서도 성능를 유지한다.
- 복잡도를 O(n²d)에서 O(nkd)로 감소시켜 계산을 최적화함으로써 고해상도 입력에 대한 확장성을 확보한다. 여기서 k ≪ n이다.
- 표준 트랜스포머 블록에 직접 iRPE 모듈을 통합함으로써 호환성과 통합 용이성을 확보한다.
- 각 높이 및 너비 방향의 상대 오프셋에 대해 고유한 벡터를 갖는 학습 가능한 룩업 테이블을 사용하여 상대 위치 임베딩을 구현한다.
실험 결과
연구 질문
- RQ1시각 Transformer를 사용한 이미지 분류 작업에서 상대 위치 인코딩이 절대 위치 인코딩을 효과적으로 대체할 수 있는가?
- RQ2왜 상대 위치 인코딩은 분류와 같은 다양한 시각 작업 간에 일관되지 않은 성능을 보이는가?
- RQ3방향성 상대 거리 모델링은 2차원 시각 트랜스포머의 어텐션 패턴에 어떤 영향을 미치는가?
- RQ4객체 검출 및 세그멘테이션과 같은 고해상도 시각 작업에 RPE를 적용할 경우 계산에 어떤 영향을 미치는가?
- RQ5쿼리-RPE 상호작용은 모델이 국소적 및 전역적 공간적 의존성을 포착하는 데 어떤 영향을 미치는가?
주요 결과
- 제안된 iRPE 방법은 하이퍼파라미터 조정 없이 DeiT-S가 ImageNet에서 1.5%의 top-1 정확도 향상을, DETR-ResNet50이 COCO에서 1.3%의 mAP 향상을 달성한다.
- 이미지 분류 작업에서는 절대 위치 인코딩을 상대 위치 인코딩으로 완전히 대체할 수 있으며, 이는 우수하거나 유사한 성능를 제공한다.
- 객체 검출에서는 절대 위치 인코딩이 여전히 필요하며, 정밀한 객체 위치 추정을 위한 필수적인 인덕티브 바이어스를 제공한다.
- 방향성 상대 거리 모델링은 특히 얕은 레이어에서 주변 피처에 더 집중하는 모델이 되기 때문에 어텐션 패턴을 크게 향상시킨다.
- 쿼리-RPE 상호작용을 포함한 컨텍스트 기반 곱셈 메커니즘은 국소적 공간적 구조를 포착하는 데 모델의 능력을 향상시키며, 컨볼루션 인덕티브 바이어스를 모방한다.
- 어텐션 헤드 간에 RPE를 공유함으로써 비공유 버전과 유사한 성능를 달성하면서도 파라미터를 줄이고 정확도 저하를 최소화한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.