[논문 리뷰] Rethinking BiSeNet For Real-time Semantic Segmentation
이 논문은 Short-Term Dense Concatenate 백본과 Detail Guidance 디코더를 도입한 STDC-Seg를 제시하여 추가 추론 비용 없이 빠르고 정확한 실시간 의미론적 분할을 가능하게 한다.
BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
연구 동기 및 목표
- 매개변수와 연산이 적으면서도 확장 가능한 수용 영역을 제공하는 효율적인 백본(STDC 모듈)을 설계한다.
- Detail Guidance를 통해 공간 상세 학습을 저수준 특징에 통합함으로써 추가적인 공간 경로의 필요성을 제거한다.
- 높은 수준의 시맨틱 특징을 가이드된 저수준 디테일과 융합하여 경계 보존을 개선한다.
- 단일 스트림 엔드투엔드 아키텍처를 사용하여 Cityscapes, CamVid와 같은 실시간 분할 벤치마크에서 강력한 속도-정확도 트레이드오프를 달성한다.
제안 방법
- 여러 블록에서 다중 해상도 특징 맵을 점차 작아지는 커널로 연결하는 STDC 모듈을 도입하여 확장 가능한 수용 영역과 FLOPs 감소를 달성한다.
- 중간 맵을 공통 해상도로 맞춘 뒤 연결(concatenation)으로 STDC 블록 출력을 다운샘플링하여 융합한다.
- 디코더에서 Laplacian 기반 프로세스로 이진 디테일 그라운드트-truth을 생성하고 Detail Head를 통해 저수준 특징을 가이드하되 추론 비용은 추가하지 않는 Detail Aggregation 모듈로 Detail Guidance를 적용한다.
- Segmentation 손실과 디테일 손실(L_detail = L_Dice + L_BCE)을 함께 사용하여 저수준 특징을 공간적 디테일 쪽으로 유도한다; 추론은 Segmentation 경로만 사용한다.
- 다중 스케일 컨텍스트를 위한 BiSeNet에서 영감을 받은 컨텍스트 경로를 사용하고 이를 Feature Fusion 모듈을 통해 디코더와 융합한다.
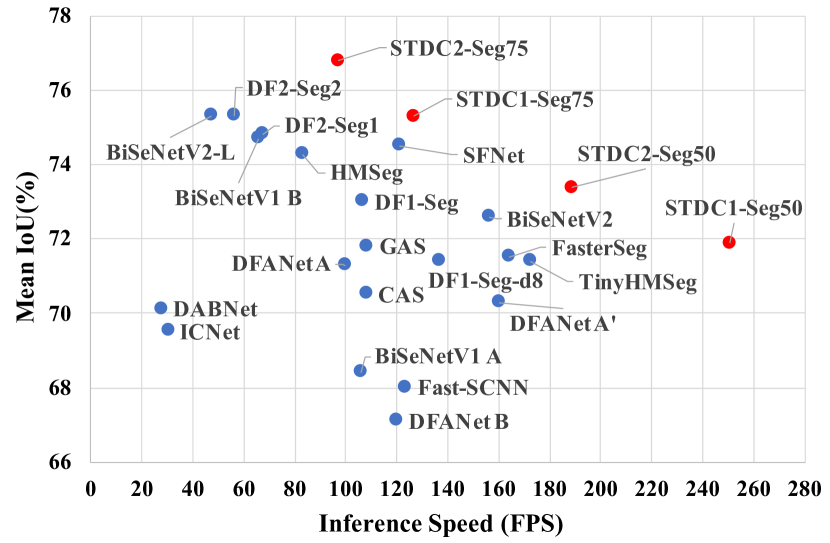
실험 결과
연구 질문
- RQ1제안된 STDC 백본이 경량 백본에 비해 실시간 분할에서 상당히 더 높은 속도로 경쟁력 있는 분할 정확도를 달성할 수 있는가?
- RQ2Detail Guidance 모듈이 추론 시간 증가 없이 경계와 작은 물체의 구분을 개선하는가?
- RQ3Cityscapes와 CamVid에서 STDC-Seg가 다른 최첨단 실시간 분할 방법과 비교하여 mIoU와 FPS 측면에서 어떤 차이를 보이는가?
- RQ4STDC 블록의 수가 정확도와 속도에 미치는 영향은 무엇인가?
- RQ5Detail Guidance가 있는 단일 스트림 디코더가 BiSeNet 스타일의 이중 경로 아키텍처를 대체하기에 충분한가?
주요 결과
- STDC2-Seg50은 Cityscapes에서 512x1024 입력 기준 188.6 FPS에서 73.4% mIoU를 달성한다.
- STDC1-Seg50은 Cityscapes에서 512x1024 입력 기준 250.4 FPS에서 71.9% mIoU를 달성한다.
- STDC2-Seg75은 Cityscapes에서 768x1536 입력 기준 97.0 FPS로 76.8% mIoU를 달성한다.
- Cityscapes 검증 세트에서 STDC2-Seg75는 97.0 FPS에서 77.0% mIoU를 달성한다(768x1536 입력).
- STDC1-Seg는 CamVid(720x960)에서 197.6 FPS로 73.0% mIoU를 달성한다.
- Detail Guidance는 경계 및 작은 물체 구분을 추론 비용 증가 없이 개선하여 계산당 정확도 면에서 Spatial Path 기반 구성을 능가한다.
![Figure 2: Illustration of architectures of BiSeNet [ 28 ] and our proposed approach. (a) presents Bilateral Segmentation Network (BiSeNet [ 28 ] ), which use an extra Spatial Path to encode spatial information. (b) demonstrates our proposed method, which use a Detail Guidance module to encode spatia](https://ar5iv.labs.arxiv.org/html/2104.13188/assets/figures/architecture-comparison.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.