[논문 리뷰] Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
SETR, 이미지를 패치 시퀀스로 다루는 순수 트랜스포머 인코더를 제안하여 의미론적 분할에서 최첨단 성능을 달성하고, ADE20K 및 Pascal Context에서 최첨단 성능과 Cityscapes에서도 경쟁력 있는 결과를 보여준다.
Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first position in the highly competitive ADE20K test server leaderboard on the day of submission.
연구 동기 및 목표
- 인코더-디코더 FCN 아키텍처를 넘어서는 의미론적 분할을 재검토한다.
- 공간 해상도에서 다운샘플링을 피하는 순수 트랜스포머 인코더를 도입한다.
- 트랜스포머 특징으로부터 전체 해상도 분할을 복구하기 위한 디코더 설계를 탐구한다.
- 이미지 패치 전반에 걸친 글로벌 셀프 어텐션이 우수한 특징 표현을 제공함을 입증한다.
제안 방법
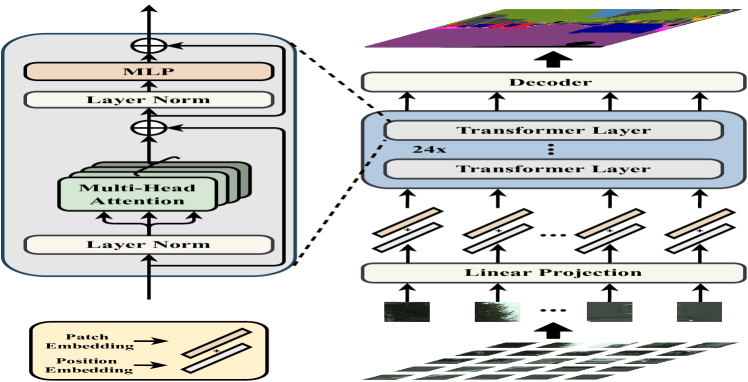
- 고정 크기의 패치로 이미지를 분할하고 이를 1D 시퀀스로 선형 임베딩한다.
- 전역 셀프 어텐션을 갖춘 순수 Transformer 인코더를 사용하여 패치 수준의 특징을 학습한다.
- 학습 가능한 패치 위치 임베딩을 통해 공간 정보를 추가한다.
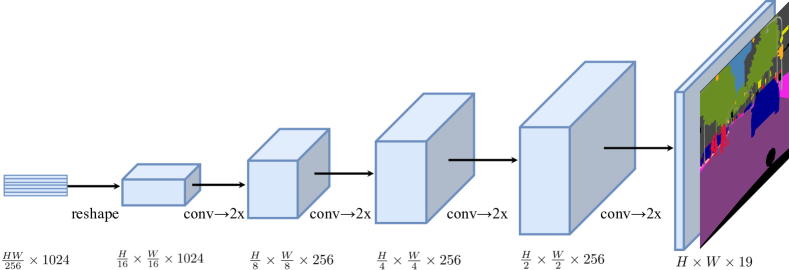
- 세 가지 디코더 설계(naive upsampling, progressive upsampling (PUP), and multi-level feature aggregation (MLA))를 실험한다.
- 적용 가능한 경우 ViT/DeiT로 트랜스포머 백본을 사전 학습하고 중간 트랜스포머 계층에 보조 손실을 통합한다.
실험 결과
연구 질문
- RQ1이미지 패치에서 작동하는 순수 Transformer 인코더가 의미론적 분할을 위한 합성곱 인코더를 대체할 수 있는가?
- RQ2트랜스포머 기반 인코더를 사용할 때 서로 다른 디코더 설계가 픽셀 단위 분할에 어떤 영향을 미치는가?
- RQ3표준 분할 벤치마크에서 SETR 성능에 대한 사전 학습 전략(ViT/DeiT)의 효과는 무엇인가?
주요 결과
- SETR은 ADE20K에서 최첨단 성능을 달성하고 (MS inference) 50.28% mIoU, Pascal Context에서 (MS inference) 55.83% mIoU를 달성한다.
- SETR은 Cityscapes에서도 경쟁력 있는 결과를 보여주며, SETR-PUP가 다수의 FCN 기반 및 주의(attention) 보강 베이스라인을 능가한다.
- 트랜스포머 인코더 (ViT/DeiT)의 사전 학습은 성능을 크게 향상시키며 무작위로 초기화된 변형들을 능가한다.
- 세 가지 디코더 설계는 서로 다른 트레이드오프를 보이며, progressive upsampling (SETR-PUP)이 일반적으로 정확도와 복잡성의 최상의 균형을 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.