[논문 리뷰] Rethinking Vision Transformers for MobileNet Size and Speed
EfficientFormerV2는 세밀하고 지연-인식 아키텍처 탐색을 통해 모델 크기와 지연 시간을 함께 최적화하여 모바일 기기에서 Vision Transformer가 MobileNet 규모의 크기와 속도에 필적하면서도 정확도를 더 높일 수 있음을 보여준다.
With the success of Vision Transformers (ViTs) in computer vision tasks, recent arts try to optimize the performance and complexity of ViTs to enable efficient deployment on mobile devices. Multiple approaches are proposed to accelerate attention mechanism, improve inefficient designs, or incorporate mobile-friendly lightweight convolutions to form hybrid architectures. However, ViT and its variants still have higher latency or considerably more parameters than lightweight CNNs, even true for the years-old MobileNet. In practice, latency and size are both crucial for efficient deployment on resource-constraint hardware. In this work, we investigate a central question, can transformer models run as fast as MobileNet and maintain a similar size? We revisit the design choices of ViTs and propose a novel supernet with low latency and high parameter efficiency. We further introduce a novel fine-grained joint search strategy for transformer models that can find efficient architectures by optimizing latency and number of parameters simultaneously. The proposed models, EfficientFormerV2, achieve 3.5% higher top-1 accuracy than MobileNetV2 on ImageNet-1K with similar latency and parameters. This work demonstrate that properly designed and optimized vision transformers can achieve high performance even with MobileNet-level size and speed.
연구 동기 및 목표
- ViTs가 정확하지만 모바일 배포에 비해 너무 크거나 느린 실용성 격차를 해결하고 동기를 부여한다.
- 모바일 친화적인 ViT 백본을 파라미터 수와 지연 시간이 MobileNet 계열과 비슷하도록 설계한다.
- 모델 크기와 추론 속도를 함께 최적화하는 미세한 공동 탐색 전략을 제안한다.
- ImageNet-1K에서의 파레토 최적 아키텍처를 시연하고 탐지 및 분할과 같은 다운스트림 작업에서 검증한다.
제안 방법
- 4단계 계층적 백본 아키텍처를 가진 EfficientFormerV2를 도입한다.
- 잔차 로컬 토큰 믹서를 지연도(Locality)를 위한 깊이별 합성곱이 포함된 통합 FFN으로 대체한다.
- V의 로컬 정보 및 Talking Head 연결을 포함한 MHSA 개선을 탐구한다.
- Stride Attention 및 Dual-Path Attention Downsampling으로 고해상도 어텐션을 가능하게 하여 정확도와 지연 간의 균형을 맞춘다.
- 정확도, 모델 크기, 지연 시간을 결합한 모바일 효율 점수(MES)를 제안하여 공동 탐색을 주도한다.
- 탄력적 깊이, 너비, FFN 확장 비를 가진 검색 가능한 초망(supernet)을 구성하고 MES와 정확도를 최적화하는 액션 프런트를 사용한 평가 기반 NAS를 수행한다.
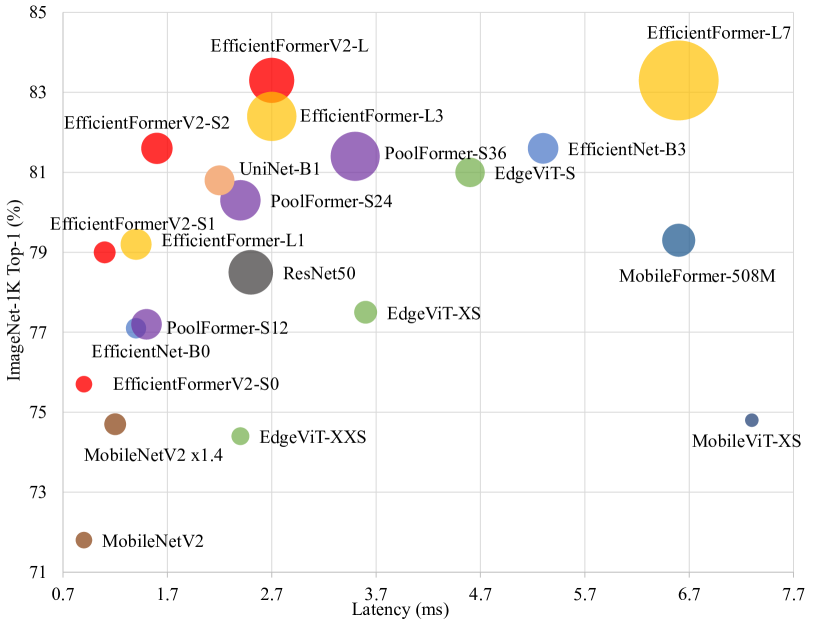
실험 결과
연구 질문
- RQ1비전 트랜스포머를 MobileNet 수준의 크기와 속도로 설계하되 정확도를 희생하지 않을 수 있을까?
- RQ2실제 기기에서 경쟁력 있는 지연을 가진 모바일 친화적 ViT를 가능하게 하는 아키텍처 변경은 무엇인가?
- RQ3NAS가 ViT의 모델 크기와 지연을 함께 최적화하여 파레토 최적의 트레이드오프를 달성할 수 있을까?
- RQ4EfficientFormerV2 변형이 탐지 및 분할과 같은 다운스트림 작업에서 개선으로 이어지는가?
주요 결과
- EfficientFormerV2-S0는 ImageNet-1K에서 MobileNetV2와 유사한 지연 및 파라미터 수 대비 더 높은 Top-1 정확도를 달성한다.
- EfficientFormerV2-S1은 EfficientFormer-L1보다 약 2배 작고 1.3배 빠르면서도 유사한 성능을 유지한다.
- EfficientFormerV2-S2는 지연이 유사한 범위에서 여러 모바일 친화적 베이스라인보다 정확도가 앞선다.
- 다운스트림 작업에서 EfficientFormerV2 백본을 사용할 때 COCO의 Mask R-CNN 및 ADE20K의 의미론적 분할에서 개선이 나타난다.
- MES 기반의 공동 탐색은 단일 메트릭 최적화보다 크기, 지연 및 정확도의 파레토 최적 모델을 더 잘 생성한다.
- 제안된 Stride Attention 및 Dual-Path Attention Downsampling은 정확도 향상을 유지하면서 지연을 크게 줄인다.
![Figure 2: Network architectures. We consider three metrics, i.e. , model performance, size, and inference speed, and study the models that improve any metric without hurting others. (a) Network of EfficientFormer [ 47 ] that serves as a baseline model. (b) Unified FFN (Sec. 3.1 ). (c) MHSA improveme](https://ar5iv.labs.arxiv.org/html/2212.08059/assets/x2.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.