[논문 리뷰] Rethinking White-Box Watermarks on Deep Learning Models under Neural Structural Obfuscation
이 논문은 더미 뉴런 기반의 신경구조 Obfuscation이 비허용 없이도 9개의 주류 화이트박스 DNN 워터마크를 비활성화할 수 있음을, 워터마크 검증을 방해하는 소멸하지 않는 더미 뉴런을 도입하여 증명합니다. 또한 Stealthy obfuscation을 달성하기 위해 생성/주입 프리미티브와 위장 기법을 제시합니다.
Copyright protection for deep neural networks (DNNs) is an urgent need for AI corporations. To trace illegally distributed model copies, DNN watermarking is an emerging technique for embedding and verifying secret identity messages in the prediction behaviors or the model internals. Sacrificing less functionality and involving more knowledge about the target DNN, the latter branch called extit{white-box DNN watermarking} is believed to be accurate, credible and secure against most known watermark removal attacks, with emerging research efforts in both the academy and the industry. In this paper, we present the first systematic study on how the mainstream white-box DNN watermarks are commonly vulnerable to neural structural obfuscation with extit{dummy neurons}, a group of neurons which can be added to a target model but leave the model behavior invariant. Devising a comprehensive framework to automatically generate and inject dummy neurons with high stealthiness, our novel attack intensively modifies the architecture of the target model to inhibit the success of watermark verification. With extensive evaluation, our work for the first time shows that nine published watermarking schemes require amendments to their verification procedures.
연구 동기 및 목표
- 주요 화이트박스 DNN 워터마크 검증이 신경구조 Obfuscation에 취약한지 강조한다.
- 생성 및 주입 프리미티브를 포함한 포괄적 더미-뉴런 기반 공격 프레임워크를 제안한다.
- 모델 유틸리티를 보존하면서 9개의 발표된 화이트박스 워터마킹 스킴 전반에서 공격 효과를 시연한다.
제안 방법
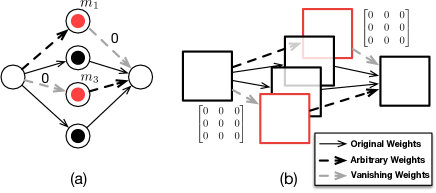
- 모델 출력을 불변으로 남기면서 워터마크 검증을 변경하는 더미 뉴런을 도입한다.
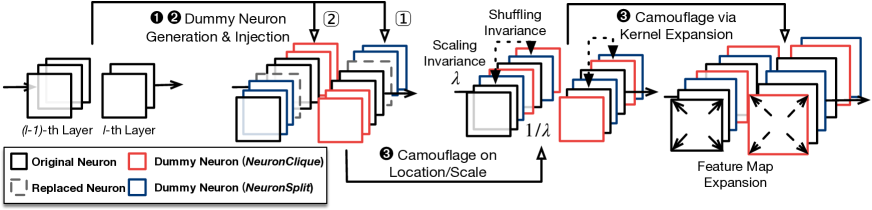
- 비 vanishing 가중치를 가진 더미 뉴런 그룹을 생성하기 위해 NeuronClique 및 NeuronSplit 프리미티브를 개발한다.
- 은밀함 고려와 함께 뒤에서부터 앞쪽으로 더미 뉴런을 주입하고 스케일링/셔플링 불변성을 활용한다.
- 은폐된 모델을 위장하기 위해 커널 확장 및 가중치 분포 트릭을 적용한다.
- 더미-뉴런 제거 접근법을 포함한 방어 지향적 논의를 제공한다.
실험 결과
연구 질문
- RQ1주류 화이트박스 워터마크 검증을 유용성 저하나 데이터 접근 없이 신뢰성 있게 중단할 수 있는가?
- RQ2vanishing하지 않는 가중치를 가진 더미 뉴런이 다양한 스킴에서 워터마크 검증을 효과적으로 무효화하는가?
- RQ3더미 뉴런을 자율적으로 생성하고 모델 기능을 보존하면서 은밀하게 주입하는 방법은 무엇인가?
- RQ4이러한 신경구조 Obfuscation 및 워터마크 제거에 대한 방어책은 무엇인가?
주요 결과
- 9개의 발표된 화이트박스 워터마크 스킴은 공격 후 성공적인 검증을 잃고 검증이 무작위로 축소된다.
- Obfuscation 후 일반 모델 유틸리티는 변함없다.
- 공격 프레임워크는 NeuronClique 및 NeuronSplit 프리미티브를 사용하여 더미 뉴런을 자동으로 생성하고 주입한다.
- 확장은 스케일링, 셔플링 및 커널 확장 기술을 통해 은밀함을 향상시킨다.
- 논문은 방어자 지식 요구사항 및 더미-뉴런 제거 알고리즘을 다룬다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.