[논문 리뷰] Reverse Engineering Self-Supervised Learning
본 논문은 SSL 표현을 경험적으로 분석하여, SSL이 규제화에 의해 주도되는 의미적 클러스터링과 데이터 압축을 유도하고, 학습 중에 라벨에 접근하지 않아도 계층 및 계층 구조 전반에서 의미적 정렬이 향상된다는 것을 보여준다.
Self-supervised learning (SSL) is a powerful tool in machine learning, but understanding the learned representations and their underlying mechanisms remains a challenge. This paper presents an in-depth empirical analysis of SSL-trained representations, encompassing diverse models, architectures, and hyperparameters. Our study reveals an intriguing aspect of the SSL training process: it inherently facilitates the clustering of samples with respect to semantic labels, which is surprisingly driven by the SSL objective's regularization term. This clustering process not only enhances downstream classification but also compresses the data information. Furthermore, we establish that SSL-trained representations align more closely with semantic classes rather than random classes. Remarkably, we show that learned representations align with semantic classes across various hierarchical levels, and this alignment increases during training and when moving deeper into the network. Our findings provide valuable insights into SSL's representation learning mechanisms and their impact on performance across different sets of classes.
연구 동기 및 목표
- SSL-학습 표현이 샘플 증강과 의미 클래스에 대해 어떻게 군집하는지 조사한다.
- 클러스터링을 유도하는 규제화와 불변성의 역할을 탐구한다.
- SSL 표현이 계층적 수준에 걸쳐 의미 클래스와 정렬되는지 평가한다.
- 학습 중 네트워크 계층 전반에 걸쳐 클러스터링과 의미 정렬이 어떻게 진화하는지 검토한다.
제안 방법
- Train SSL models (e.g., VICReg) on CIFAR-100 using standard augmentations. Measure clustering via nearest class-center (NCC) accuracy and class-variance metrics (CDNV). Analyze sample-level versus semantic-class clustering dynamics over training epochs. Decompose SSL loss into invariance and regularization components to assess their impact. Estimate mutual information between input and embeddings during training (MINE). Evaluate linear probe performance and hierarchical clustering across layers and targets (samples, 100 classes, 20 superclasses).
- Use RES-L-H (ResNet variant) backbones with a two-layer MLP projection head for VICReg experiments.
- Compare SSL clustering to supervised clustering with and without data augmentation to contextualize results.
- Explore target randomness by creating target labels with varying semantic meaningfulness and track learning.
- Examine intermediate layers to determine how hierarchical semantic targets are captured across depth.

실험 결과
연구 질문
- RQ1Do SSL-trained representations cluster data with respect to semantic classes in addition to augmentations?
- RQ2What is the role of the regularization term in SSL in promoting semantic clustering and information compression?
- RQ3How does alignment to semantic targets evolve as training progresses and as we move deeper into the network?
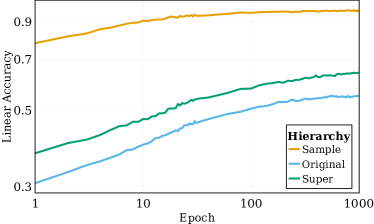
- RQ4Can SSL representations learn and reflect hierarchical class structures (samples, original classes, superclasses) across layers?
- RQ5How does the randomness of targets affect the ability of SSL representations to align with semantic structure?
주요 결과
- SSL training induces strong clustering of augmented samples around their mean embeddings, and increasingly clusters by semantic classes at later training stages.
- Regularization, not invariance, primarily drives improvements in semantic clustering and downstream linear accuracy, with invariance saturating early.
- Representations show high alignment with semantic classes across hierarchies, even without label information during SSL training.
- Clustering into semantic classes improves across deeper layers and deeper layers better capture high-level hierarchies (superclasses) than original classes.
- Mutual information between input and embeddings decreases over training, indicating implicit information compression.
- SSL models exhibit neural-collapse-like centroid structures at the sample level, with persistent semantic clustering that strengthens over training.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.