[논문 리뷰] Revisiting Zeroth-Order Optimization for Memory-Efficient LLM Fine-Tuning: A Benchmark
이 논문은 zeroth-order (BP-free) optimization methods를 벤치마크하여 메모리 효율적인 대형 언어 모델의 파인튜닝을 여러 계열과 작업 및 파인튜닝 스킴에 걸쳐 평가하고, 개선점을 제시한다.
In the evolving landscape of natural language processing (NLP), fine-tuning pre-trained Large Language Models (LLMs) with first-order (FO) optimizers like SGD and Adam has become standard. Yet, as LLMs grow {in size}, the substantial memory overhead from back-propagation (BP) for FO gradient computation presents a significant challenge. Addressing this issue is crucial, especially for applications like on-device training where memory efficiency is paramount. This paper proposes a shift towards BP-free, zeroth-order (ZO) optimization as a solution for reducing memory costs during LLM fine-tuning, building on the initial concept introduced by MeZO. Unlike traditional ZO-SGD methods, our work expands the exploration to a wider array of ZO optimization techniques, through a comprehensive, first-of-its-kind benchmarking study across five LLM families (Roberta, OPT, LLaMA, Vicuna, Mistral), three task complexities, and five fine-tuning schemes. Our study unveils previously overlooked optimization principles, highlighting the importance of task alignment, the role of the forward gradient method, and the balance between algorithm complexity and fine-tuning performance. We further introduce novel enhancements to ZO optimization, including block-wise descent, hybrid training, and gradient sparsity. Our study offers a promising direction for achieving further memory-efficient LLM fine-tuning. Codes to reproduce all our experiments are at https://github.com/ZO-Bench/ZO-LLM .
연구 동기 및 목표
- BP-free zeroth-order optimization의 메모리 효율성과 LLM 파인튜닝에서의 정확도를 1차 방법과 비교하여 평가한다.
- 다섯 개의 LLM 계열과 세 가지 작업 복잡도에 걸쳐 여섯 가지 ZO 최적화 접근법을 벤치마크한다.
- ZO 최적화의 성능에 영향을 주는 최적화 원리 및 작업 정렬 요인을 LLM 파인튜닝에서 식별한다.
- 메모리 효율성과 정확도를 개선하기 위한 ZO 방법의 향상(블록 단위, 하이브리드 ZO/FO, 희소성)을 제안한다.
제안 방법
- LLM 파인튜닝에 적용 가능한 zeroth-order optimization 방법을 검토하고 분류한다 (ZO-SGD, ZO-SGD-Sign, ZO-SGD-MMT, ZO-SGD-Cons, ZO-Adam, Forward-Grad).
- FO 그래디언트를 근사하기 위해 방향 미분 해석을 갖춘 무작위 그래디언트 추정기(RGE)를 사용한다.
- 사전 학습 목표와 파인튜닝 작업의 정렬을 맞추는 프롬프트를 비교하여 작업 정렬을 조사한다.
- Roberta-Large, OPT, LLaMA2, Vicuna, Mistral 등 5개 LLM 계열, 3가지 작업 복잡도(SST2, COPA, WinoGrande) 및 5가지 파인튜닝 스킴(FT, LoRA, Prefix, Prompt 등)을 대상으로 대규모 벤치마크를 수행한다.
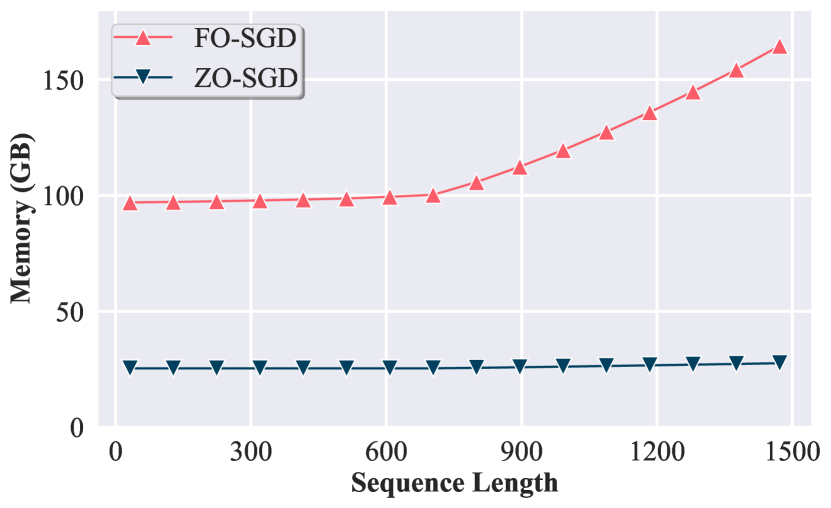
- BP-free 대 FO 방법을 비교하기 위해 매 반복의 메모리, GPU 사용량 및 런타임을 평가한다.
- 향상: 블록 단위 ZO, 하이브리드 ZO/FO 학습, 희소성 유도 ZO 그래디언트 추정.
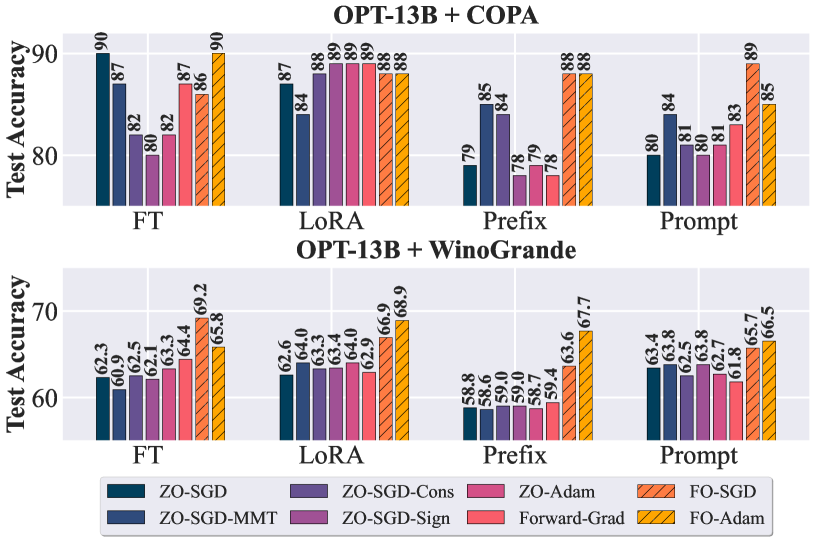
실험 결과
연구 질문
- RQ1포괄적인 벤치마크가 LLM 파인튜닝에서 제로차 최적화의 정확도와 메모리 효율성 간의 트레이드오프를 밝힐 수 있는가?
- RQ2작업 정렬, forward gradient, 그리고 알고리즘적 복잡성이 모델 규모에 걸친 ZO 기반 파인튜닝 성능에 어떤 영향을 미치는가?
- RQ3블록 단위 최적화, 하이브리드 ZO/FO, 그래디언트 희소성 등의 개선이 메모리 이점을 유지하면서 ZO 파인튜닝을 향상시키는가?
- RQ4PEFT 스킴과 모델 계열 전반에서 ZO 방법과 Forward-Grad 및 FO 최적화기의 상대 성능은 어떠한가?
주요 결과
- ZO 최적화는 특정 설정에서 경쟁력 있는 결과를 달성할 수 있지만 모델과 작업 간에 큰 분산을 보인다.
- Forward-Grad는 쿼리 예산이 충분할 때 많은 ZO 방법보다 우수할 수 있지만 대형 모델에서나 혼합 정밀도 학습이 호환되지 않을 때 메모리 효율 이점이 감소한다.
- ZO-SGD-Cons와 ZO-SGD-MMT는 여러 설정에서 안정적인 성능을 제공하는 반면, ZO-SGD-Sign은 간단한 프롬프트를 제외하면 종종 성능이 저조하다.
- 프롬프트 기반 작업 정렬은 ZO 성능에 크게 영향을 미친다; 정렬이 없으면 ZO 방법의 정확도가 크게 떨어진다.
- LoRA 기반 파인튜닝은 다양한 ZO 방법에 걸쳐 강건함을 보이며 메모리 효율적인 학습 전략과의 호환성을 시사한다.
- 더 큰 모델과 더 복잡한 작업에서 FO 방법이 일반적으로 ZO 방법보다 눈에 띄게 우수하며, ZO 접근법의 확장성 한계를 부각한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.