[논문 리뷰] ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
ReWOO decouples reasoning from tool observations in augmented language models, dramatically reducing token usage while maintaining or improving accuracy across multi-step NLP tasks, and enabling specialization of reasoning in smaller models.
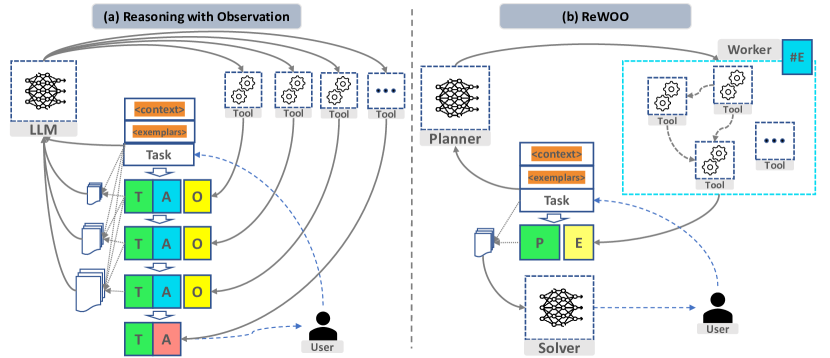
Augmented Language Models (ALMs) blend the reasoning capabilities of Large Language Models (LLMs) with tools that allow for knowledge retrieval and action execution. Existing ALM systems trigger LLM thought processes while pulling observations from these tools in an interleaved fashion. Specifically, an LLM reasons to call an external tool, gets halted to fetch the tool's response, and then decides the next action based on all preceding response tokens. Such a paradigm, though straightforward and easy to implement, often leads to huge computation complexity from redundant prompts and repeated execution. This study addresses such challenges for the first time, proposing a modular paradigm ReWOO (Reasoning WithOut Observation) that detaches the reasoning process from external observations, thus significantly reducing token consumption. Comprehensive evaluations across six public NLP benchmarks and a curated dataset reveal consistent performance enhancements with our proposed methodology. Notably, ReWOO achieves 5x token efficiency and 4% accuracy improvement on HotpotQA, a multi-step reasoning benchmark. Furthermore, ReWOO demonstrates robustness under tool-failure scenarios. Beyond prompt efficiency, decoupling parametric modules from non-parametric tool calls enables instruction fine-tuning to offload LLMs into smaller language models, thus substantially reducing model parameters. Our illustrative work offloads reasoning ability from 175B GPT3.5 into 7B LLaMA, demonstrating the significant potential for truly efficient and scalable ALM systems.
연구 동기 및 목표
- 도구-강화 LLM 워크플로에서 도토큰 중복 제거를 추론과 관측을 분리함으로써 동기를 부여한다.
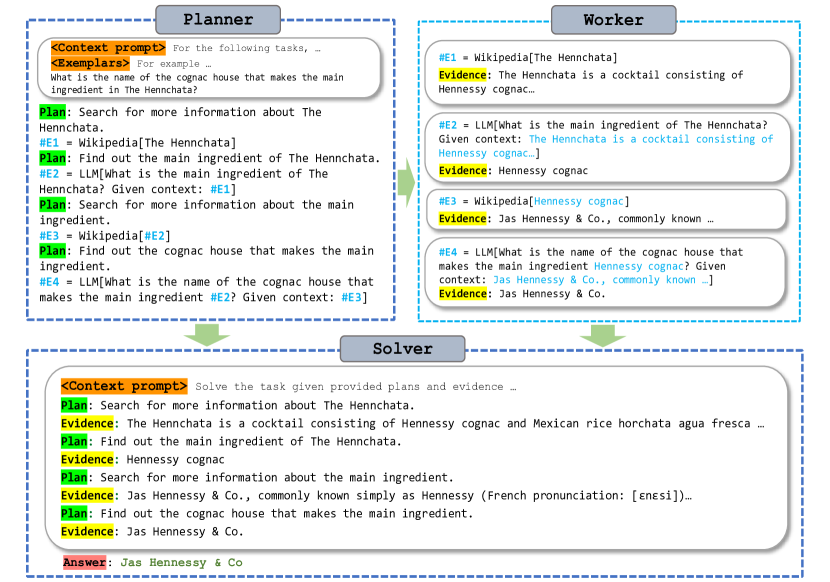
- 모듈식 Planner-Worker-Solver 프레임워크(ReWOO)를 제안하여 추론을 도구 피드백과 분리한다.
- 다양한 벤치마크에서 토큰 효율성 향상과 정확도 개선을 정량화한다.
- 견고성을 보여주고 예견 가능한 추론을 소형 모델로 오프로드할 수 있는 가능성을 보여준다.
제안 방법
- 추론, 도구 호출, 증거 종합을 분리하는 Planner-Worker-Solver 아키텍처를 도입한다.
- 관찰 의존 프롬프트와 비교하여 토큰 사용을 줄이는 형식 프롬프트 토큰 분석을 제공한다.
- 도구 응답 전에 계획을 가능하게 하는 예시와 다양한 도구 세트를 사용한다.
- instruction tuning을 통해 Planner 7B 등 소형 LLM으로 예견 가능한 추론을 오프로드하여 전문화를 활용한다.
- 다양한 벤치마크(HotpotQA, TriviaQA, GSM8K, StrategyQA, PhysicsQA, SportsUnderstanding, SOTUQA)와 Baseline으로 GPT-3.5-turbo를 평가한다.
실험 결과
연구 질문
- RQ1관찰로부터 추론을 분리하는 것이 ALM의 토큰 비용을 정확도 손실 없이 줄일 수 있는가?
- RQ2ReWOO가 다단 NLP 작업에서 ReAct 및 직접 프롬 prompting 대비 어떤 성능을 보이는가?
- RQ3예견 가능한 추론을 소형 모델으로 어느 정도 오프로드할 수 있는가?
- RQ4도구 실패 및 불필요한 도구에 대해 ReWOO의 견고성은 어느 정도인가?
- RQ5이 패러다임에서 대화 RLHF가 성능에 미치는 영향은 무엇인가?
주요 결과
- ReWOO는 여섯 개의 NLP 벤치마크에서 평균적으로 토큰 사용을 64% 감소시킨다.
- ReWOO는 ReAct 대비 평균적으로 절대 정확도 4.4 퍼센트 포인트의 이득을 달성한다.
- SOTUQA에서 ReWOO는 정확도에서 절대 8%p의 우위를 보이며 토큰을 43% 더 적게 사용한다.
- 도구 실패 시나리오에서도 ReWOO는 견고성을 유지하고 도구가 실패할 때 ReAct보다 덜 성능이 저하된다.
- 전문화는 7B LLaMA 기반 Planner가 여러 벤치마크에서 25배 더 큰 GPT-3.5의 성능과 일치하도록 할 수 있다.
- 벤치마크 전반에 걸쳐 ReWOO는 프롬프트 비용이 현저히 낮은 일관된 성능을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.