[논문 리뷰] RF-DETR Object Detection vs YOLOv12 : A Study of Transformer-based and CNN-based Architectures for Single-Class and Multi-Class Greenfruit Detection in Complex Orchard Environments Under Label Ambiguity
이 연구는 복잡한 과수원에서 녹색 과일 탐지를 위해 RF-DETR(트랜스포머 기반)과 YOLOv12(CNN 기반)를 직접 비교하고, 라벨 불확실성 하에서 단일 클래스 및 다중 클래스(가려짐 대 비가려짐) 시나리오를 평가합니다. RF-DETR는 정확도에서 우세하고, YOLOv12는 엣지-간결성에서 이점을 보입니다.
This study conducts a detailed comparison of RF-DETR object detection base model and YOLOv12 object detection model configurations for detecting greenfruits in a complex orchard environment marked by label ambiguity, occlusions, and background blending. A custom dataset was developed featuring both single-class (greenfruit) and multi-class (occluded and non-occluded greenfruits) annotations to assess model performance under dynamic real-world conditions. RF-DETR object detection model, utilizing a DINOv2 backbone and deformable attention, excelled in global context modeling, effectively identifying partially occluded or ambiguous greenfruits. In contrast, YOLOv12 leveraged CNN-based attention for enhanced local feature extraction, optimizing it for computational efficiency and edge deployment. RF-DETR achieved the highest mean Average Precision (mAP50) of 0.9464 in single-class detection, proving its superior ability to localize greenfruits in cluttered scenes. Although YOLOv12N recorded the highest mAP@50:95 of 0.7620, RF-DETR consistently outperformed in complex spatial scenarios. For multi-class detection, RF-DETR led with an mAP@50 of 0.8298, showing its capability to differentiate between occluded and non-occluded fruits, while YOLOv12L scored highest in mAP@50:95 with 0.6622, indicating better classification in detailed occlusion contexts. Training dynamics analysis highlighted RF-DETR's swift convergence, particularly in single-class settings where it plateaued within 10 epochs, demonstrating the efficiency of transformer-based architectures in adapting to dynamic visual data. These findings validate RF-DETR's effectiveness for precision agricultural applications, with YOLOv12 suited for fast-response scenarios. >Index Terms: RF-DETR object detection, YOLOv12, YOLOv13, YOLOv14, YOLOv15, YOLOE, YOLO World, YOLO, You Only Look Once, Roboflow, Detection Transformers, CNNs
연구 동기 및 목표
- 단일 클래스 및 다중 클래스 레이블이 있는 커스텀 녹색 과일 데이터셋에서 RF-DETR 및 YOLOv12의 탐지 정확도 평가.
- 실제 과수원 조건에서 가려짐, 위장, 배경 혼잡도에서 모델 성능 평가.
- 정밀 농업 배포 의사결정을 안내하기 위한 수렴 동향 및 추론 효율성 분석.
제안 방법
- RF-DETR와 YOLOv12에 대해 동일한 데이터셋, 학습 프로토콜, 에포크를 사용한다.
- DINOv2 백본과 변형 가능 주의력을 갖춘 RF-DETR; 앵커 박스나 NMS 없음; 단일 스케일 특징.
- R-ELAN 백본과 영역 주의력을 갖춘 YOLOv12; 탐지, 방향 바운딩 박스, 인스턴스 분할용 다중 작업 헤드.
- 입력 해상도를 640x640로 표준화; FP32로 학습하며 배치 크기 ~16, RTX A5000에서.
- 정밀도, 재현율, F1, mAP@50 및 mAP@50:95, plus mIoU로 평가; 추론 속도 평가.
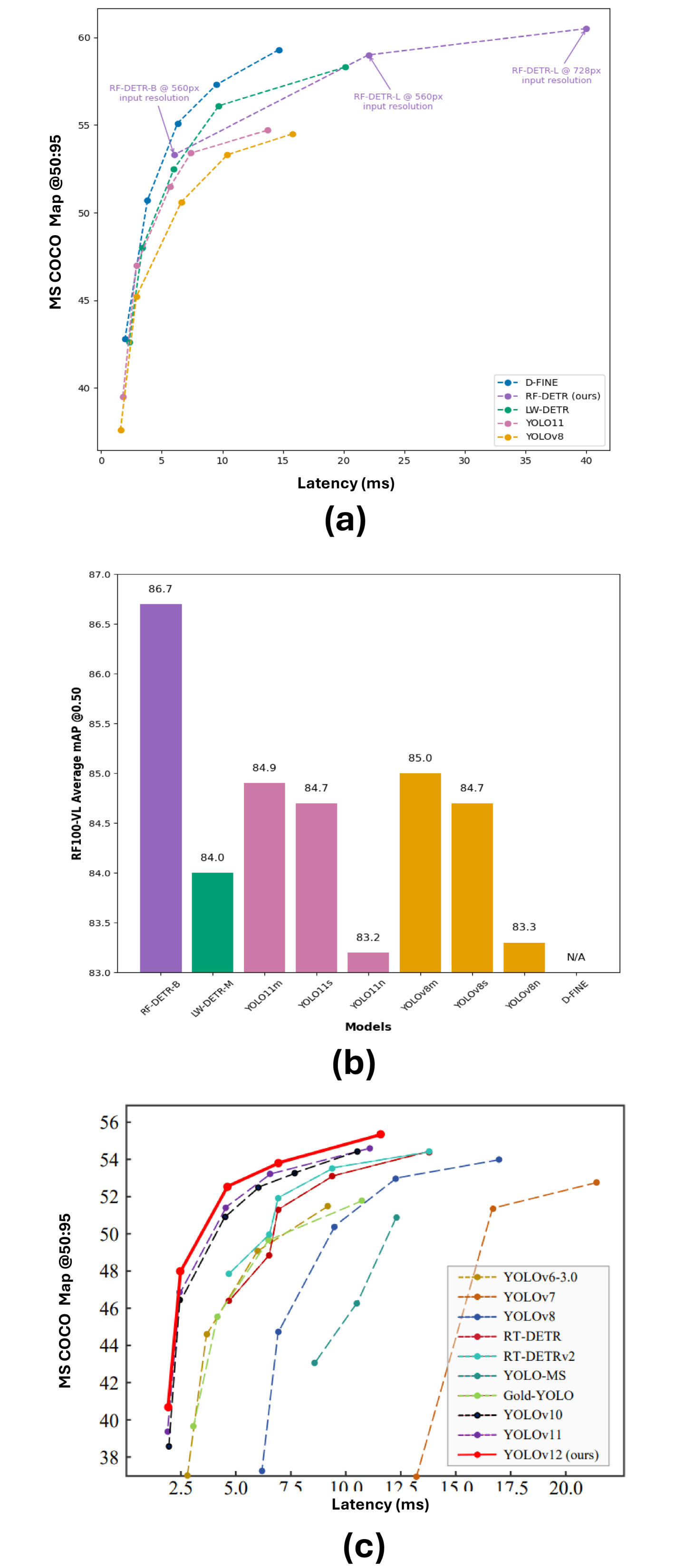
실험 결과
연구 질문
- RQ1라벨 불확실성 하에서 단일 클래스 녹색 과일 탐지에서 RF-DETR와 YOLOv12의 성능 차이는 어떠한가?
- RQ2가려짐과 비가려짐 과일을 구분하는 다중 클래스 탐지에서 두 모델의 성능은 어떠한가?
- RQ3이 농업 맥락에서 트랜스포머 기반 vs CNN 기반 탐지기의 수렴 동역학 및 학습 효율성은 무엇인가?
- RQ4RF-DETR와 YOLOv12의 상대적 추론 속도 및 엣지 배치 적합성은 어떠한가?
주요 결과
- RF-DETR은 단일 클래스 탐지에서 mAP@50가 0.9464를 달성.
- YOLOv12N은 단일 클래스 시나리오에서 최상의 mAP@50:95를 0.7620로 달성.
- 다중 클래스 탐지에서 RF-DETR은 mAP@50가 0.8298에 도달.
- 다중 클래스 조건에서 YOLOv12L이 mAP@50:95를 0.6622로 이끈다.
- RF-DETR은 빠른 수렴을 보이고 작업에 따라 10-20 Epoch 이내에 수렴하는 경향으로, 효율적인 학습 역학을 강조한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.