[논문 리뷰] RGBT Salient Object Detection: A Large-scale Dataset and Benchmark
VT5000을 소개한다, 5000개의 이미지 쌍으로 구성된 대규모 정렬 RGBT 데이터셋으로 활성 객체 검출에 사용되며, ADFNet이라는 어텐션 기반 모달 융합 네트워크를 제시한다. 이는 VT5000 및 두 공개 데이터셋 VT821/VT1000에서 기존 방법들보다 성능이 우수하다.
Salient object detection in complex scenes and environments is a challenging research topic. Most works focus on RGB-based salient object detection, which limits its performance of real-life applications when confronted with adverse conditions such as dark environments and complex backgrounds. Taking advantage of RGB and thermal infrared images becomes a new research direction for detecting salient object in complex scenes recently, as thermal infrared spectrum imaging provides the complementary information and has been applied to many computer vision tasks. However, current research for RGBT salient object detection is limited by the lack of a large-scale dataset and comprehensive benchmark. This work contributes such a RGBT image dataset named VT5000, including 5000 spatially aligned RGBT image pairs with ground truth annotations. VT5000 has 11 challenges collected in different scenes and environments for exploring the robustness of algorithms. With this dataset, we propose a powerful baseline approach, which extracts multi-level features within each modality and aggregates these features of all modalities with the attention mechanism, for accurate RGBT salient object detection. Extensive experiments show that the proposed baseline approach outperforms the state-of-the-art methods on VT5000 dataset and other two public datasets. In addition, we carry out a comprehensive analysis of different algorithms of RGBT salient object detection on VT5000 dataset, and then make several valuable conclusions and provide some potential research directions for RGBT salient object detection.
연구 동기 및 목표
- 크게 다양하고 자유롭게 이용 가능한 RGBT 데이터셋(VT5000)을 지상실측 마스크 및 해상 11개의 주석과 함께 생성한다.
- RGB 및 열(thermal) 가지를 활용한 주의 집중 기반 융합을 갖춘 엔드-투-엔드 CNN 기반 베이스라인(ADFNet)을 제안한다.
- 경계 정확도를 향상시키기 위한 에지 인식 손실 및 다층 특징 융합과 전역 맥락 모듈로 saliency를 다듬는다.
- VT5000 및 공개 데이터셋에 대한 RGBT SOD 방법을 분석하고 비교하여 향후 연구를 안내한다.
제안 방법
- RGB와 열 특성을 각각 추출하는 2-스트림 VGG16 기반 백본을 개발한다.
- 융합 전 CBAM(Convolutional Block Attention Module)을 적용하여 채널 및 공간 특징 가중치를 부여한다.
- 저수준 및 고수준 정보를 모두 보존하기 위해 다층에서 모달 특징을 융합한다.
- 다중 스케일에서 전역 맥락 지침을 제공하기 위해 피라미드 풀링 모듈(PPM)을 도입한다.
- 융합 후 다중 스케일 특징을 통합하기 위해 특징 집계 모듈(FAM)을 사용한다.
- 크로스 엔트로피 손실과 경계 기반 정제 손실로 학습하여 객체 경계를 선명하게 한다.

실험 결과
연구 질문
- RQ1깊은 네트워크를 학습시키기에 RGBT SOD 데이터셋은 얼마나 크고 다양해야 하는가?
- RQ2어텐션 기반 모달 융합이 단일 모드 또는 단순 융합 베이스라인에 비해 RGBT 활성 객체 검출을 향상시키는가?
- RQ3다층 융합 및 전역 맥락 모듈이 RGBT SOD에서 위치화 및 경계 구분을 개선하는가?
- RQ4제안한 방법의 VT5000 및 기존 VT821/VT1000 데이터셋에서의 비교 성능은 어떠한가?
주요 결과
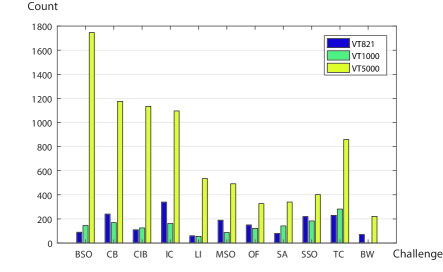
- VT5000은 11개의 주석 도전과제가 포함된 5000개의 정렬된 RGBT 이미지 쌍을 제공하여 RGBT SOD 방법의 견고한 평가를 가능하게 한다.
- 제안된 ADFNet은 VT5000 및 두 공용 데이터셋(VT821 및 VT1000)에서 일관되게 최첨단 방법보다 우수한 성능을 보인다.
- CBAM 기반의 주의 집중 및 다층 융합은 saliency 검출을 위해 RGB와 열 신호를 보완적으로 효과적으로 활용한다.
- PPM 및 FAM 모듈은 각각 전역 맥락 인식 및 다중 스케일 특징 통합을 향상시킨다.
- 에지 손실은 saliency 맵에서 객체 경계를 더 선명하게 만드는 데 도움을 준다.
- 포괄적인 VT5000 분석은 RGBT SOD에 대한 실행 가능한 통찰력과 미래 연구 방향을 제시한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.