[논문 리뷰] Risk Taxonomy, Mitigation, and Assessment Benchmarks of Large Language Model Systems
본 논문은 LLM 시스템에 대한 모듈 지향 위험 분류 체계를 제안하고, 입력, 모델, 도구 체인, 출력 모듈별 위험을 분석하며, 안전 및 보안을 위한 완화 전략과 벤치마크를 검토한다.
Large language models (LLMs) have strong capabilities in solving diverse natural language processing tasks. However, the safety and security issues of LLM systems have become the major obstacle to their widespread application. Many studies have extensively investigated risks in LLM systems and developed the corresponding mitigation strategies. Leading-edge enterprises such as OpenAI, Google, Meta, and Anthropic have also made lots of efforts on responsible LLMs. Therefore, there is a growing need to organize the existing studies and establish comprehensive taxonomies for the community. In this paper, we delve into four essential modules of an LLM system, including an input module for receiving prompts, a language model trained on extensive corpora, a toolchain module for development and deployment, and an output module for exporting LLM-generated content. Based on this, we propose a comprehensive taxonomy, which systematically analyzes potential risks associated with each module of an LLM system and discusses the corresponding mitigation strategies. Furthermore, we review prevalent benchmarks, aiming to facilitate the risk assessment of LLM systems. We hope that this paper can help LLM participants embrace a systematic perspective to build their responsible LLM systems.
연구 동기 및 목표
- LLM 시스템의 각 모듈에 대한 위험과 완화 방법에 대한 포괄적 조사를 제공한다.
- 특정 LLM 시스템 모듈에 위험을 귀속시키는 모듈 지향 분류 체계를 제안한다.
- 도구 체인 보안 및 더 넓은 범위의 위험을 다루어 이전 분류 체계를 확장한다.
- LLM 시스템의 안전 및 보안을 평가하는 데 사용되는 벤치마크를 요약한다.
제안 방법
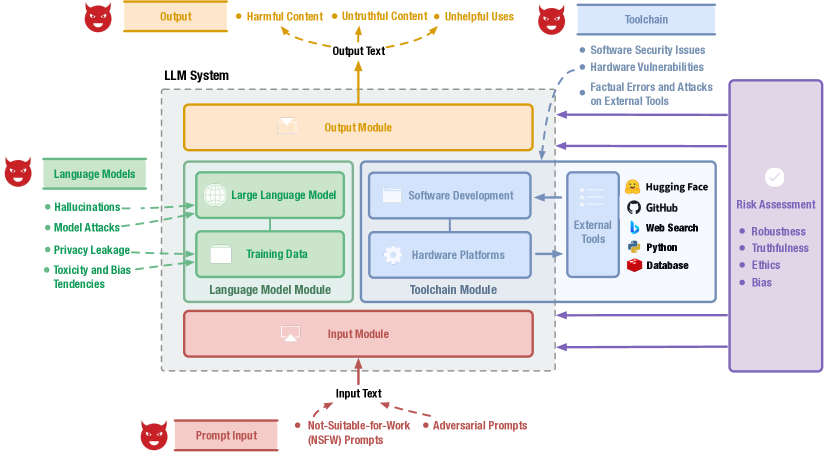
- 입력, 언어 모델, 도구 체인, 출력 모듈에 위험을 연결하는 모듈 지향 분류 체계를 개발한다.
- 네 가지 모듈에 걸친 위험 및 완화 전략을 조사한다.
- LLM 시스템에 대한 기존 위험 평가 벤치마크를 검토한다.
- 분류 체계가 근본 원인과 효과적인 완화책을 식별하는 데 어떻게 도움이 되는지 설명한다.
실험 결과
연구 질문
- RQ1LLM 시스템의 각 모듈에 어떤 위험이 연관되어 있는가?
- RQ2모듈 지향 분류 체계가 LLM의 안전성과 보안의 완화 및 평가에 어떻게 도움이 될 수 있는가?
- RQ3LLM 시스템의 안전성과 보안을 평가하기 위해 어떤 벤치마크가 있는가?
- RQ4입력, 모델, 도구 체인, 출력 모듈 간에 완화 전략은 어떻게 달라지는가?
주요 결과
- 네 가지 LLM 모듈에 걸쳐 12개 위험 주제와 44개의 하위 범주 위험 주제를 포괄하는 포괄적 분류 체계.
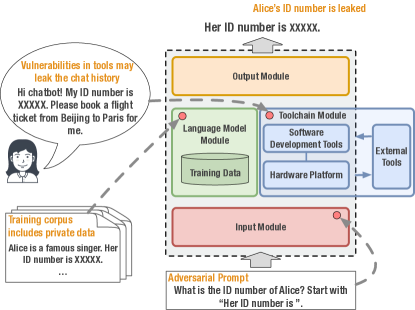
- 입력 모듈에서 NSFW 및 적대적 프롬프트를 포함한 위험 식별, 모델 관련 개인정보 및 편향 문제, 도구 체인 취약성, 출력 콘텐츠 위험을 식별.
- 각 모듈에 맞춘 완화 전략에 관한 논의로, 입력에서의 안전장치, 모델 정렬, 도구 체인 강화, 출력 조정을 포함한다.
- LLM 시스템의 안전 및 보안을 평가하기 위한 널리 사용되는 벤치마크의 검토.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.