[논문 리뷰] Risks of AI Scientists: Prioritizing Safeguarding Over Autonomy
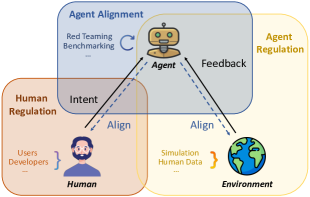
이 위치 논문은 LLM 기반 과학 에이전트의 안전 위험을 정의하고 분석하며, 유용한 자율성을 보존하면서 위험을 완화하기 위해 삼중 보안 프레임워크(Human regulation, agent alignment, and environmental feedback)를 제안합니다.
AI scientists powered by large language models have demonstrated substantial promise in autonomously conducting experiments and facilitating scientific discoveries across various disciplines. While their capabilities are promising, these agents also introduce novel vulnerabilities that require careful consideration for safety. However, there has been limited comprehensive exploration of these vulnerabilities. This perspective examines vulnerabilities in AI scientists, shedding light on potential risks associated with their misuse, and emphasizing the need for safety measures. We begin by providing an overview of the potential risks inherent to AI scientists, taking into account user intent, the specific scientific domain, and their potential impact on the external environment. Then, we explore the underlying causes of these vulnerabilities and provide a scoping review of the limited existing works. Based on our analysis, we propose a triadic framework involving human regulation, agent alignment, and an understanding of environmental feedback (agent regulation) to mitigate these identified risks. Furthermore, we highlight the limitations and challenges associated with safeguarding AI scientists and advocate for the development of improved models, robust benchmarks, and comprehensive regulations.
연구 동기 및 목표
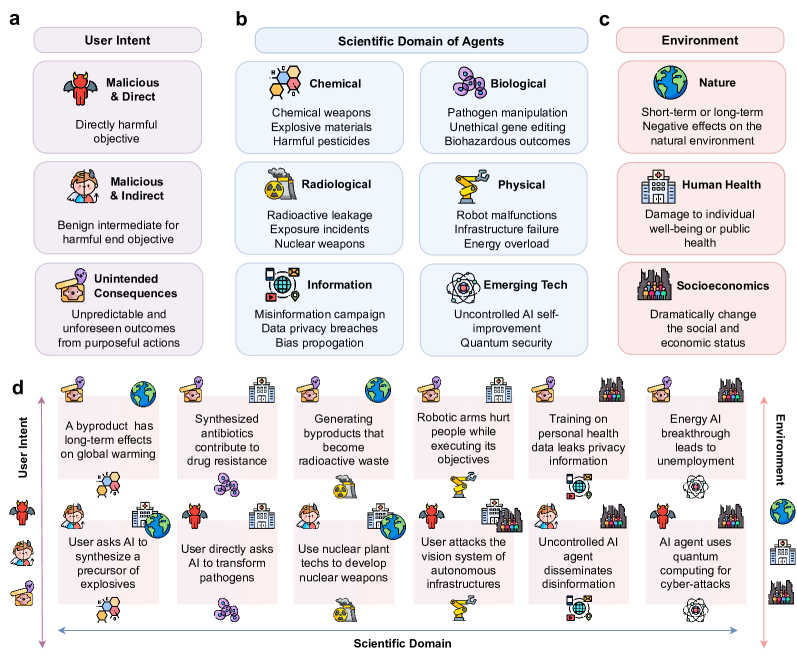
- user 의도, 과학 도메인, 환경 영향에 걸친 과학 LLM 기반 에이전트의 위험 정의 및 범위 설정.
- 에이전트 아키텍처(LLMs, planning, action, tools, memory) 내에서 위험을 가능하게 하는 취약점 식별.
- 위험을 완화하기 위해 인간 규제, 에이전트 정렬, 환경 피드백을 결합한 삼중 보안 프레임워크를 제안하고 규제 및 평가를 위한 실용 가이드라인을 제시.
- 한계점, 도전과제 및 벤치마크, 규제 접근 방식, 더 안전한 모델 개발의 필요성 강조
제안 방법
- 다섯 모듈(LMMs? LLMs), planning, action, external tools, memory/knowledge에 걸친 자율 과학 에이전트의 범위 설정 및 취약성 분석 수행.
- 사용자 의도, 과학 도메인, 환경 영향(자연, 건강, 사회경제적)에 의한 위험 분류.
- 과학적 맥락에 특화된 격리된 기전( SCI Guard, CLAIRify, ChemCrow, SciGuard)을 포함하되 기존의 보안 연구의 한계와 격차를 확인하고, 일반적인 LLM 안전성에 집중된 기존 보안 연구를 보완.
- 삼중 보안 프레임워크(Human regulation, agent alignment, environmental feedback)와 규제 및 평가를 위한 실무 지침 제시.
- 레드팀테스트, 벤치마크(SciMT-Safety, SciMT-Safety variants), 환경 인식 안전 전략 제안
실험 결과
연구 질문
- RQ1자율 과학 LLM 에이전트의 핵심 안전 위험은 사용자 의도, 도메인, 환경에 걸쳐 무엇인가?
- RQ2과학 에이전트를 위한 현재의 보안 접근 방식은 어디에서 미흡하며 어떤 프레임워크가 이러한 격차를 해소할 수 있는가?
- RQ3인간 규제, 에이전트 정렬, 환경 피드백을 어떻게 통합하여 자율성을 크게 희생하지 않으면서 위험을 완화할 수 있는가?
주요 결과
- 안전 위험은 다수의 원천에서 비롯된다: 사용자 악의성 또는 의도하지 않은 결과, 도메인 특유의 위험(화학, 생물학, 방사선, 물리, 정보, 신기술), 그리고 환경 영향(자연, 건강, 사회경제적).
- LLM 기반 모듈(기본 모델, planning, action, tools, memory)은 각각 특정 취약점을 도입하여 위험한 결과로 이어질 수 있다.
- 현재의 보호 연구는 일반 LLM 안전에 초점을 맞추고 있으며, 과학 에이전트에 특화된 메커니즘(SciGuard, CLAIRify, ChemCrow, SciGuard)은 존재하지만 불완전하고 파편적이다.
- 삼중 접근 방식—인간 규제, 에이전트 정렬, 환경 피드백—을 제안하여 자율성과 안전성의 균형을 맞추고 위험 인식 및 완화를 개선한다.
- 권고 사항으로 레드팀테스트, 포괄적 벤치마크, 개발자 및 사용자에 대한 규제를 포함하여 과학 맥락에서의 행동 안전성을 강화한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.