[논문 리뷰] RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
논문은 Reinforcement Learning from AI Feedback (RLAIF)가 세 가지 텍스트 생성 작업에서 RLHF와 일치하거나 이를 능가하며, 종종 비용이 더 낮고 인간 선호 정렬과 비교할 만하고, AI 보상을 직접 사용하는 것이 표준 증류 접근법보다 우수하다는 것을 보여준다.
Reinforcement learning from human feedback (RLHF) has proven effective in aligning large language models (LLMs) with human preferences, but gathering high-quality preference labels is expensive. RL from AI Feedback (RLAIF), introduced in Bai et al., offers a promising alternative that trains the reward model (RM) on preferences generated by an off-the-shelf LLM. Across the tasks of summarization, helpful dialogue generation, and harmless dialogue generation, we show that RLAIF achieves comparable performance to RLHF. Furthermore, we take a step towards "self-improvement" by demonstrating that RLAIF can outperform a supervised fine-tuned baseline even when the AI labeler is the same size as the policy, or even the exact same checkpoint as the initial policy. Finally, we introduce direct-RLAIF (d-RLAIF) - a technique that circumvents RM training by obtaining rewards directly from an off-the-shelf LLM during RL, which achieves superior performance to canonical RLAIF. Our results suggest that RLAIF can achieve performance on-par with using human feedback, offering a potential solution to the scalability limitations of RLHF.
연구 동기 및 목표
- AI가 생성한 선호 라벨이 RLHF에서 인간 라벨을 대체할 수 있음을 입증한다.
- 요약, 유용한 대화, 무해한 대화 작업에서 RLAIF를 RLHF 및 SFT 기준선과 비교한다.
- prompting 기법과 AI 라벨러 사이즈가 인간 선호도에 대한 정렬에 미치는 영향을 탐색한다.
- AI 라벨러의 사이즈가 정책 규모와 동일할 때 직접 AI 보상을 사용하는 것이 RL 성능을 개선하는지 조사한다.
제안 방법
- PaLM 2를 즉시 사용 가능한 AI 라벨러로 사용하여 각 작업에 대한 후보 출력 간의 쌍 선호를 점수화한다.
- AI 생성 선호를 사용하여 보상 모델을 학습하고(distilled RLAIF) RM이 제공하는 보상으로 REINFORCE 기반 RL를 수행한다.
- RM이 없는 직접 RLAIF와 비교하여 LLM이 보상 출력을 직접 점수화하는 경우를 비교한다.
- AI 라벨러 정렬성과 인간 선호도 일치를 극대화하기 위한 프롬프트 변형(기본/자세한 프리앰블, 사고 연쇄 추론, 맥락 내 예시)을 실험한다.
- 정렬성은 AI 라벨러 정렬, 인간 선호도 대비 승률, 무해성 비율로 평가한다.
- 정同 사이즈의 AI 라벨러(정책 사이즈와 동일)와 직접 AI 보상으로Robustness를 점검한다.
- LLM 규모가 AI 라벨링 품질과 정렬성에 미치는 영향을 분석한다.
실험 결과
연구 질문
- RQ1AI 생성 선호가 요약 및 대화 작업에서 RLHF 스타일 학습의 인간 선호와 유사한 성능을 달성할 수 있는가?
- RQ2RLAIF가 RLHF에 비해 확장성 및 비용 측면에서 이점을 제공하되 인간 정렬 품질을 저하시키지 않는가?
- RQ3RL 중에 보상 모델로 AI 선호를 증류하는 대신 LLM에 보상을 직접 프롬프팅하는 것이 더 효과적인가?
- RQ4프롬프팅 기법과 AI 라벨러 사이즈가 인간 선호도 및 하위 정책 품질에 어떤 영향을 미치는가?
주요 결과
| 모델 비교 | 요약 승률 대비 SFT (%) | 도움이 되는 대화 승률 대비 SFT (%) | 무해성 비율 (%) |
|---|---|---|---|
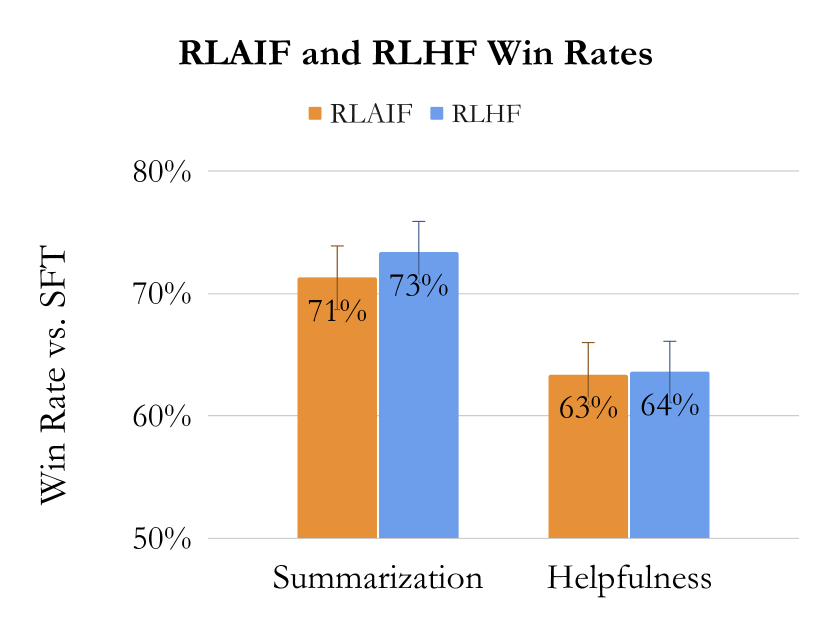
| RLAIF vs SFT | 71 | 63 | - |
| RLHF vs SFT | 73 | 64 | - |
| RLAIF vs RLHF | 50 | 52 | - |
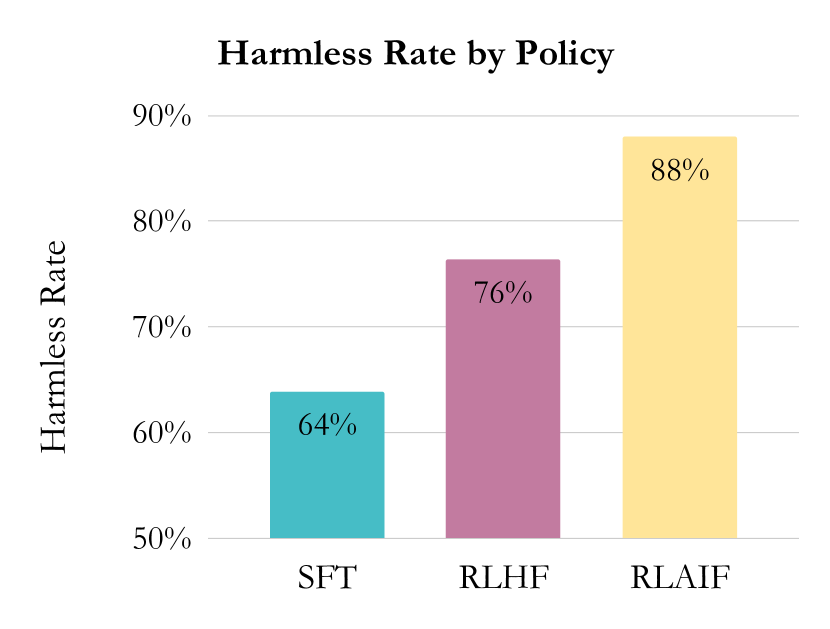
| 무해한 대화: RLAIF vs RLHF vs SFT | - | - | 88 (RLAIF) / 76 (RLHF) / 64 (SFT) |
- RLAIF는 세 가지 작업(요약, 유용한 대화, 무해한 대화)에서 RLHF와 비교하거나 우수한 성능을 보인다.
- RLAIF와 RLHF 모두 요약 및 유용한 대화에서 SFT 기준선을 능가하며; 승률은 RLAIF와 RLHF 간에 통계적으로 차이가 없다.
- 무해한 대화에서 RLAIF의 무해성 비율은 88%로 RLHF(76%) 및 SFT(64%)보다 높다.
- RL 중에 보상으로 AI 선호를 직접 프롬프팅하는 것이 AI 선호에서 증류된 보상 모델을 사용하는 표준 RLAIF 구성보다 우수할 수 있다.
- AI 라벨러가 정책과 동일한 크기일 때도 RLAIF가 SFT보다 개선될 수 있다(동일 크기 RLAIF).
- 사고 연쇄 추론을 이끌어내는 프롬프팅 기법은 일반적으로 AI 라벨러의 정렬성을 향상시키며, 자세한 프리앰블과 소수-shot 프롬프팅은 작업에 따라 혼합 효과를 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.